Crawl Budget: Googles Crawling deiner Website verstehen und optimieren
Von CaptainDNS
Veröffentlicht am 11. Februar 2026
- Das Crawl Budget ist die Anzahl der Seiten, die Googlebot innerhalb eines bestimmten Zeitraums auf deiner Website crawlt.
- Es ergibt sich aus zwei Faktoren: dem crawl rate limit (Kapazität deines Servers) und dem crawl demand (Googles Interesse an deinen Seiten).
- Bei Websites mit mehr als 10.000 Seiten verzögert ein schlecht optimiertes Crawl Budget die Indexierung wichtiger Seiten.
- Schwere Seiten verbrauchen mehr Budget: Teste das Gewicht deiner Seiten mit unserem Page Crawl Checker.
Google crawlt jeden Tag Milliarden von Seiten. Aber nicht alle deine. Das Crawl Budget ist die Anzahl der Seiten, die Googlebot innerhalb eines bestimmten Zeitraums auf deiner Website crawlt. Mit Geld hat das nichts zu tun.
Hat deine Website weniger als ein paar tausend Seiten? Dann ist das Crawl Budget wahrscheinlich kein Problem. Google hat genügend Ressourcen, um alles zu crawlen. Sobald deine Website jedoch 10.000 Seiten überschreitet oder deine Architektur Tausende von Filter- und Paginierungs-URLs erzeugt, wird die Verwaltung des Crawl Budgets zu einem wichtigen SEO-Hebel.
Dieser Guide behandelt drei Punkte: was das Crawl Budget ist, wie du es in Google Search Console überprüfst und welche 7 konkreten Techniken es zur Optimierung gibt. Wir behandeln auch einen oft übersehenen Faktor: den Einfluss der DNS-Performance auf die Crawl-Geschwindigkeit.
Was ist das Crawl Budget?
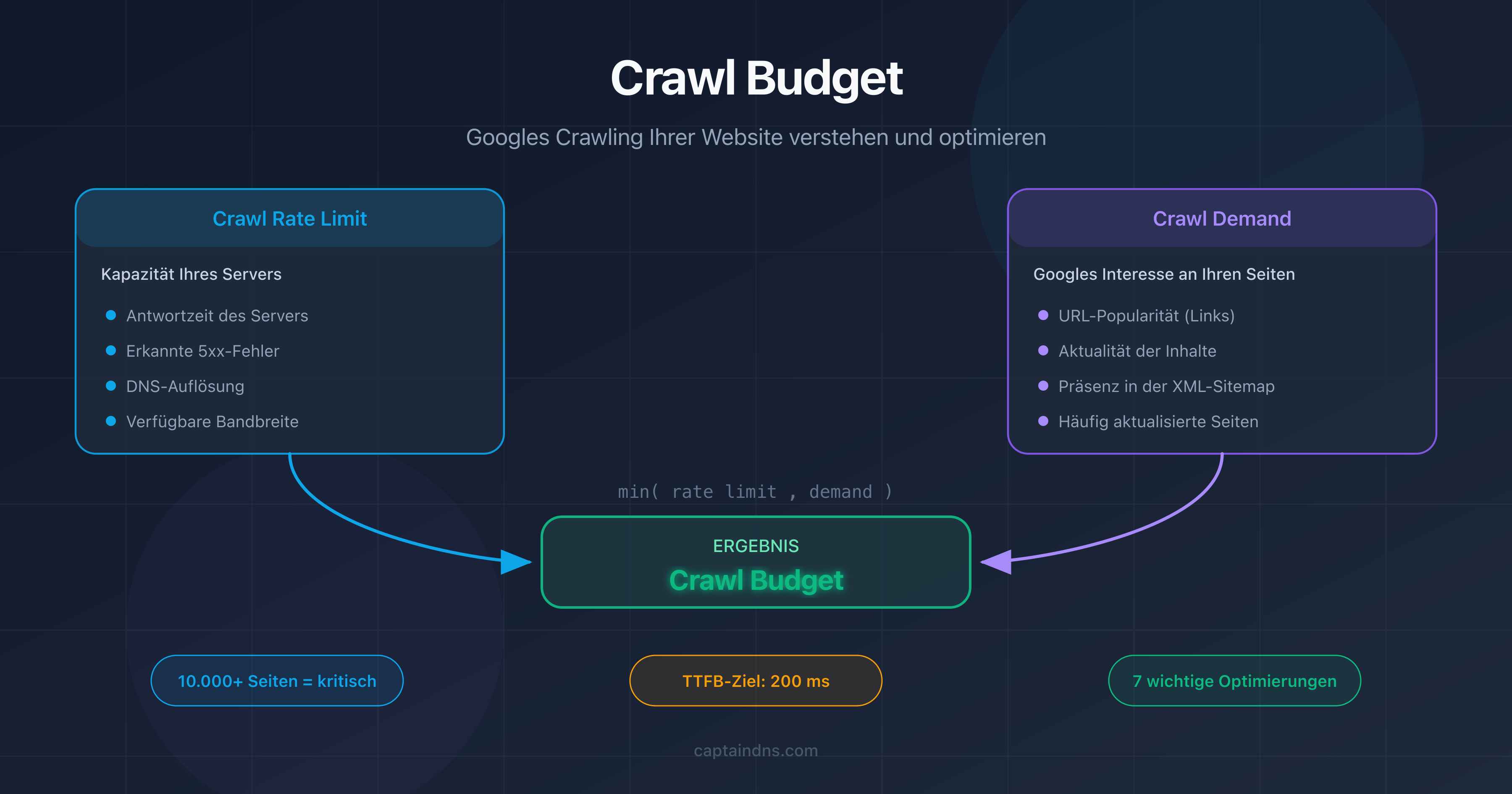
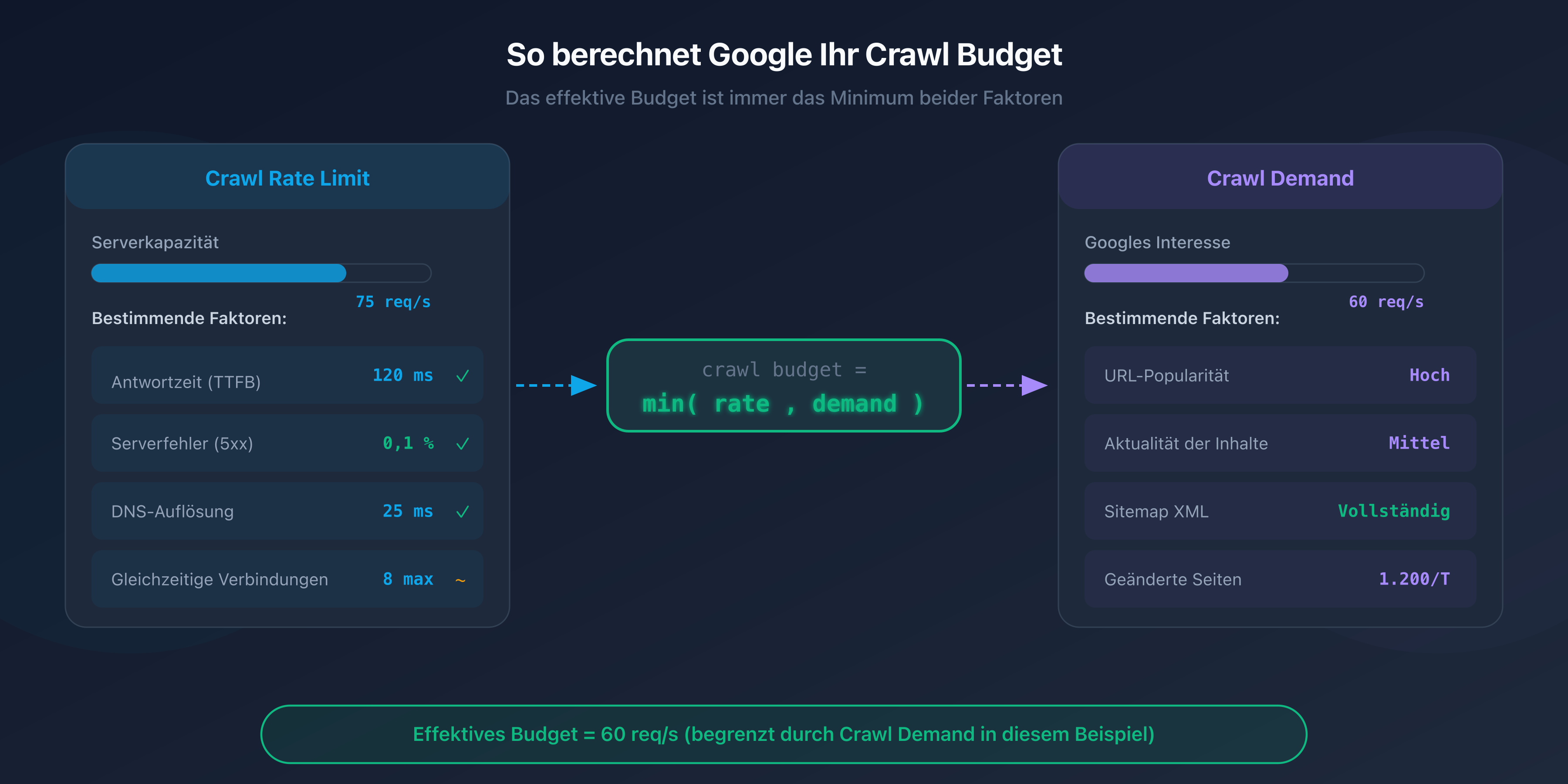
Das Crawl Budget ist ein von Google definiertes Konzept, das zwei unabhängige Faktoren kombiniert: das crawl rate limit und den crawl demand.
Crawl rate limit: die Kapazität deines Servers
Das crawl rate limit steht für die maximale Anzahl gleichzeitiger Anfragen, die Googlebot an deinen Server senden kann, ohne ihn zu überlasten. Google passt dieses Limit automatisch an die Reaktionsfähigkeit deiner Website an.
Wenn dein Server schnell antwortet (Antwortzeit unter 200 ms), erhöht Googlebot das Tempo. Wenn die Antworten langsamer werden oder 5xx-Fehler auftreten, drosselt er die Frequenz, um die Situation nicht zu verschlimmern.
Crawl demand: Googles Interesse an deinen Seiten
Der crawl demand spiegelt Googles Bereitschaft wider, deine Seiten zu crawlen. Mehrere Faktoren beeinflussen ihn:
- Popularität deiner URLs: Seiten, die externe Links erhalten oder Traffic generieren, werden häufiger gecrawlt.
- Aktualität: Seiten, die sich häufig ändern (News, Preise, Lagerbestände), werden öfter besucht als statische Seiten.
- Platzierung im Sitemap: URLs, die in deiner sitemap XML aufgeführt sind, signalisieren Google, dass sie gecrawlt werden sollten.
Die Crawl-Budget-Gleichung
Das effektive Crawl Budget deiner Website ergibt sich als Minimum aus crawl rate limit und crawl demand:
Crawl Budget = min(crawl rate limit, crawl demand)
Konkret: Selbst wenn dein Server 100 Anfragen pro Sekunde verarbeiten kann, crawlt Google nicht mehr Seiten, als es für nötig hält. Und umgekehrt: Wenn Google 50.000 Seiten crawlen möchte, dein Server aber nur 5 Anfragen pro Sekunde verträgt, wird das Crawling langsam sein.
Warum ist das Crawl Budget wichtig für SEO?
Auswirkung auf die Indexierung
Eine nicht gecrawlte Seite ist eine nicht indexierte Seite. Wenn Googlebot nicht genügend Zeit hat, bestimmte URLs deiner Website zu crawlen, erscheinen sie nicht in den Suchergebnissen, auch wenn ihr Inhalt hervorragend ist.
Das Problem ist besonders bei großen Websites sichtbar. Tief liegende Seiten, erreichbar nach 4-5 Klicks von der Startseite, werden seltener gecrawlt. Wenn dein Crawl Budget begrenzt ist, kann es Wochen oder sogar Monate dauern, bis diese Seiten indexiert werden.
Wann wird das Crawl Budget zum Problem?
Google ist eindeutig: Das Crawl Budget ist nur für große Websites ein Thema. Hier sind die Situationen, in denen du dich darum kümmern solltest:
- Websites mit mehr als 10.000 einzigartigen URLs: E-Commerce, Verzeichnisse, Content-Portale.
- Websites mit Facetten-Navigation: Filterkombinationen (Größe, Farbe, Preis, Marke) erzeugen Tausende nahezu identischer URLs.
- Websites mit dupliziertem Inhalt: HTTP- und HTTPS-Versionen, www und nicht-www, oder URL-Parameter, die Duplikate erzeugen.
- Websites mit technischen Fehlern: Redirect-Ketten, 404-Fehler und Soft-404-Seiten verschwenden Budget, ohne etwas beizutragen.
Die am stärksten betroffenen Websites
E-Commerce-Websites sind am häufigsten betroffen. Ein Katalog mit 50.000 Produkten und 20 Filterfacetten kann Millionen von URLs erzeugen. Ohne eine strikte Verwaltung der robots.txt und der canonical-Tags verbringt Googlebot seine Zeit damit, Seiten mit geringem Wert zu crawlen, anstatt strategisch wichtige Produktseiten zu besuchen.
Auch Medienwebsites mit umfangreichen Archiven, Foren und Kleinanzeigenportale sind betroffen.
Wie überprüfst du dein Crawl Budget?
Bericht "Crawling-Statistiken" in Google Search Console
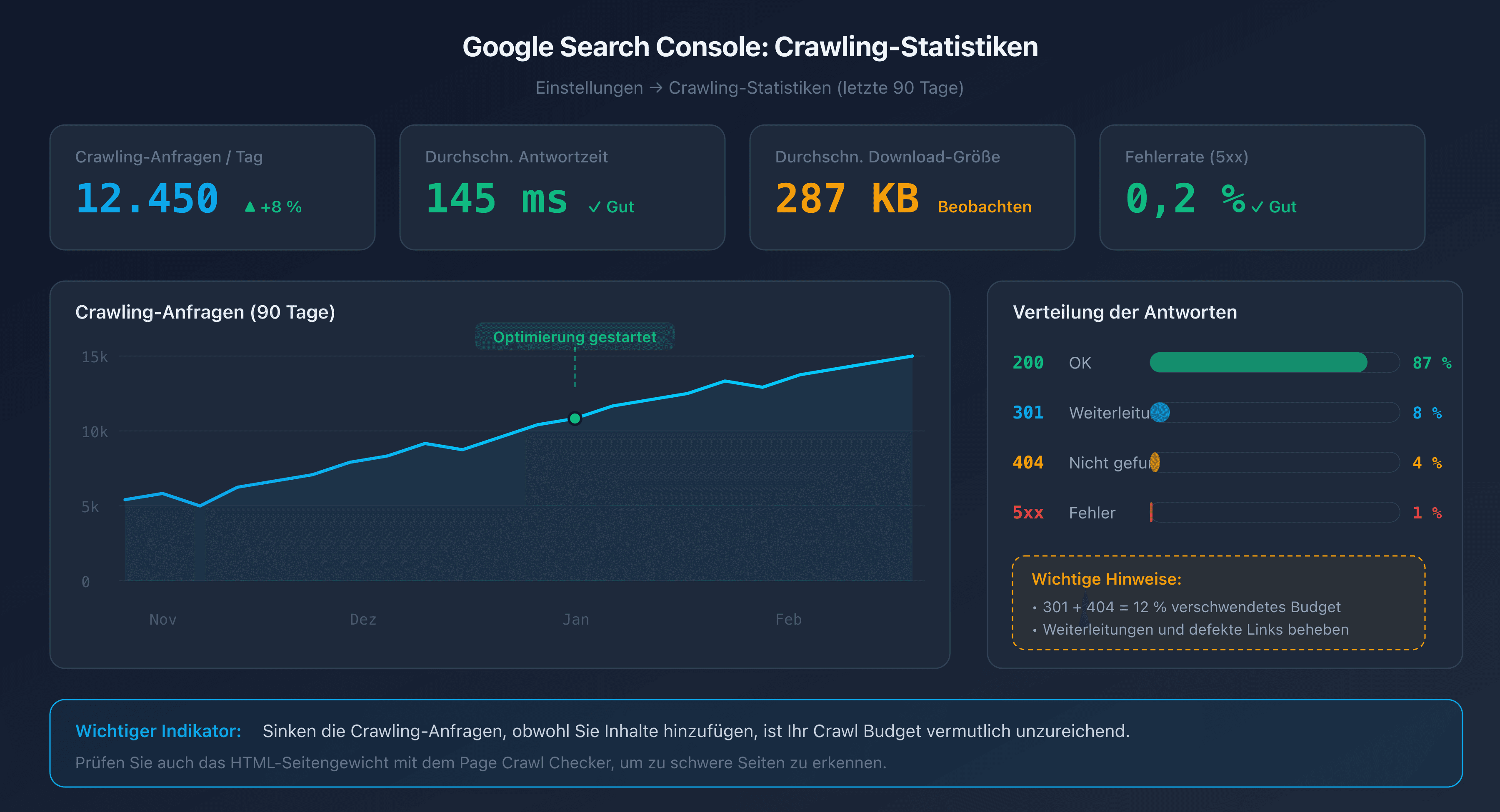
Google Search Console bietet einen speziellen Bericht unter Einstellungen > Crawling-Statistiken. Dieser Bericht zeigt für die letzten 90 Tage:
- Die Gesamtzahl der Crawl-Anfragen pro Tag.
- Die durchschnittliche Antwortzeit deines Servers.
- Die Verteilung nach Antworttyp (200, 301, 404, 5xx).
- Die durchschnittliche Größe der heruntergeladenen Seiten.
Ein guter Indikator: Wenn die Anzahl der Crawl-Anfragen sinkt, obwohl du neuen Content hinzufügst, ist dein Crawl Budget wahrscheinlich unzureichend.
Analyse der Server-Logs
Die Logs deines Webservers (Apache, Nginx) zeichnen jeden Besuch von Googlebot auf. Durch ihre Analyse kannst du feststellen:
- Welche Seiten am häufigsten gecrawlt werden (und welche nie).
- Die Crawl-Muster (Uhrzeiten, Frequenz, Tiefe).
- Die an Googlebot zurückgegebenen Fehler.
Filtere Anfragen, deren User-Agent "Googlebot" enthält, um den Crawler-Traffic zu isolieren.
URL Inspection Tool
Das URL-Prüftool in Google Search Console ermöglicht es, den Status einer einzelnen Seite zu überprüfen: Datum des letzten Crawls, Indexierungsstatus und eventuell erkannte Probleme.
7 Techniken zur Optimierung deines Crawl Budgets
1. Defekte Links und Redirect-Ketten beheben
Jeder defekte Link (404) und jede Redirect-Kette (301 auf 301 auf 301) verschwendet eine Crawl-Anfrage. Googlebot folgt dem Link, erhält einen Fehler oder eine Weiterleitung und muss von vorne beginnen. Das Ergebnis: Budget wird für nichts verbraucht.
Verwende einen Crawler wie Screaming Frog oder Sitebulb, um defekte Links und Redirect-Ketten auf deiner Website zu erkennen. Korrigiere die Links direkt auf das endgültige Ziel.
2. Die robots.txt optimieren
Die robots.txt ermöglicht es, Googlebot den Zugriff auf unnötige Bereiche deiner Website zu sperren. Typische Ziele:
- Administrations- und Backend-Seiten.
- Interne Suchergebnisseiten.
- Filter- und Sortierseiten (Facetten).
- CSS-/JS-Dateien, die nicht einzeln gecrawlt werden müssen.
# robots.txt - Filterseiten blockieren
User-agent: Googlebot
Disallow: /search?
Disallow: /filter/
Disallow: /sort/
Disallow: /admin/
Achtung: Das Blockieren einer URL in robots.txt verhindert das Crawling, aber nicht die Deindexierung. Wenn eine blockierte Seite externe Links erhält, kann Google sie trotzdem indexieren (ohne sie zu crawlen), indem es die Ankertexte der Links als Grundlage verwendet.
3. Die sitemap XML bereinigen
Deine sitemap XML sollte nur URLs enthalten, die du indexiert sehen möchtest. Entferne:
- URLs, die 404-Fehler oder 301-Weiterleitungen zurückgeben.
- URLs, die durch robots.txt blockiert sind.
- URLs mit einem
noindex-Tag. - Seiten mit geringer Qualität oder Duplikate.
Eine saubere Sitemap signalisiert Google, welche Seiten seine Aufmerksamkeit verdienen. Wenn deine Sitemap 100.000 URLs enthält, von denen nur 20.000 tatsächlich nützlich sind, verwässerst du das Signal.
4. Duplizierten Inhalt mit canonical eliminieren
Duplizierte Seiten sind eine direkte Verschwendung von Crawl Budget. Googlebot crawlt jede URL separat, auch wenn der Inhalt identisch ist.
Verwende das <link rel="canonical">-Tag, um die bevorzugte Version einer Seite anzugeben. Typische Fälle:
- Tracking-Parameter (
?utm_source=...). - Sortier- und Paginierungsvarianten.
- HTTP-/HTTPS- oder www-/nicht-www-Versionen.
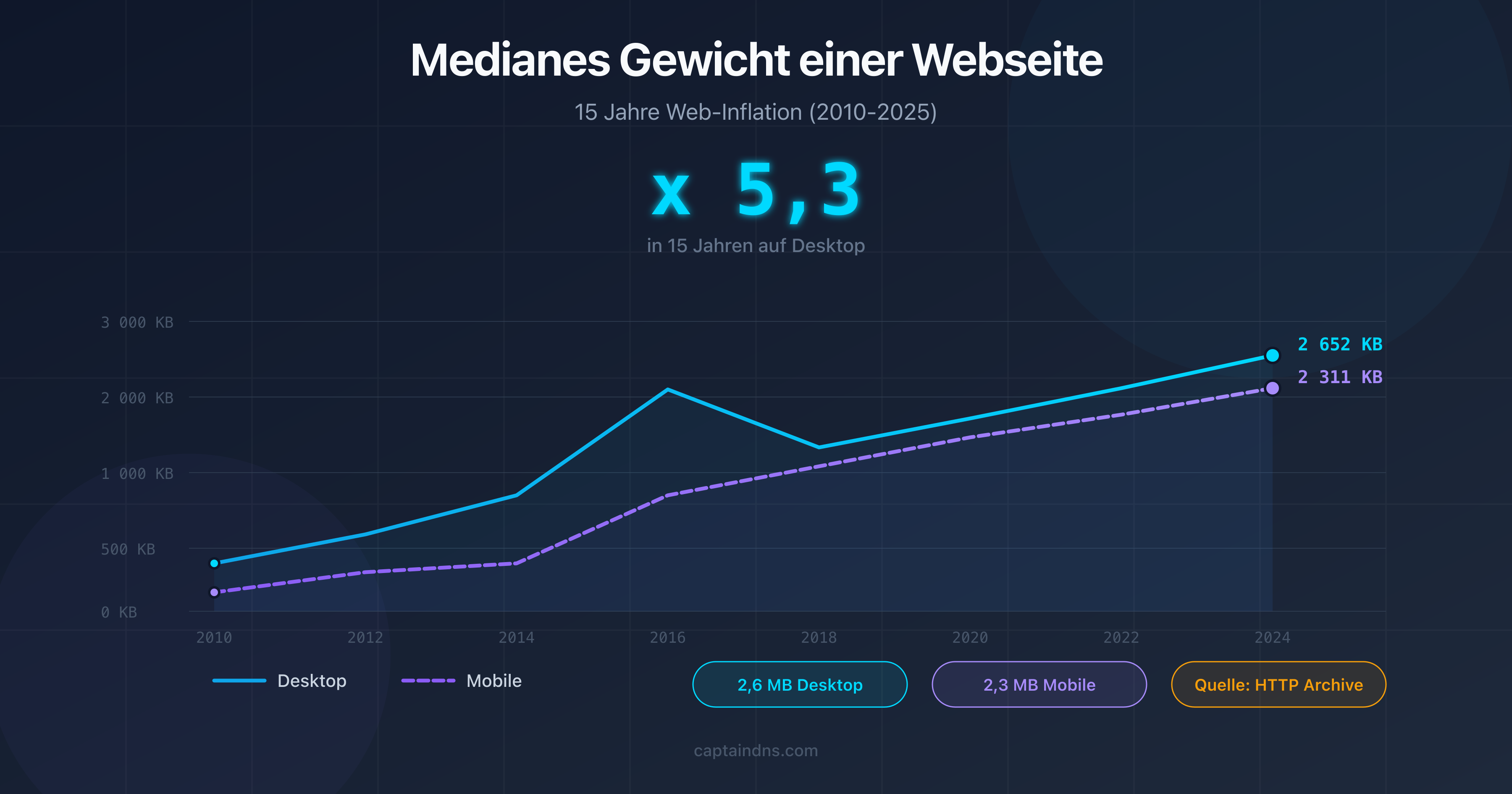
5. Das HTML-Gewicht der Seiten reduzieren
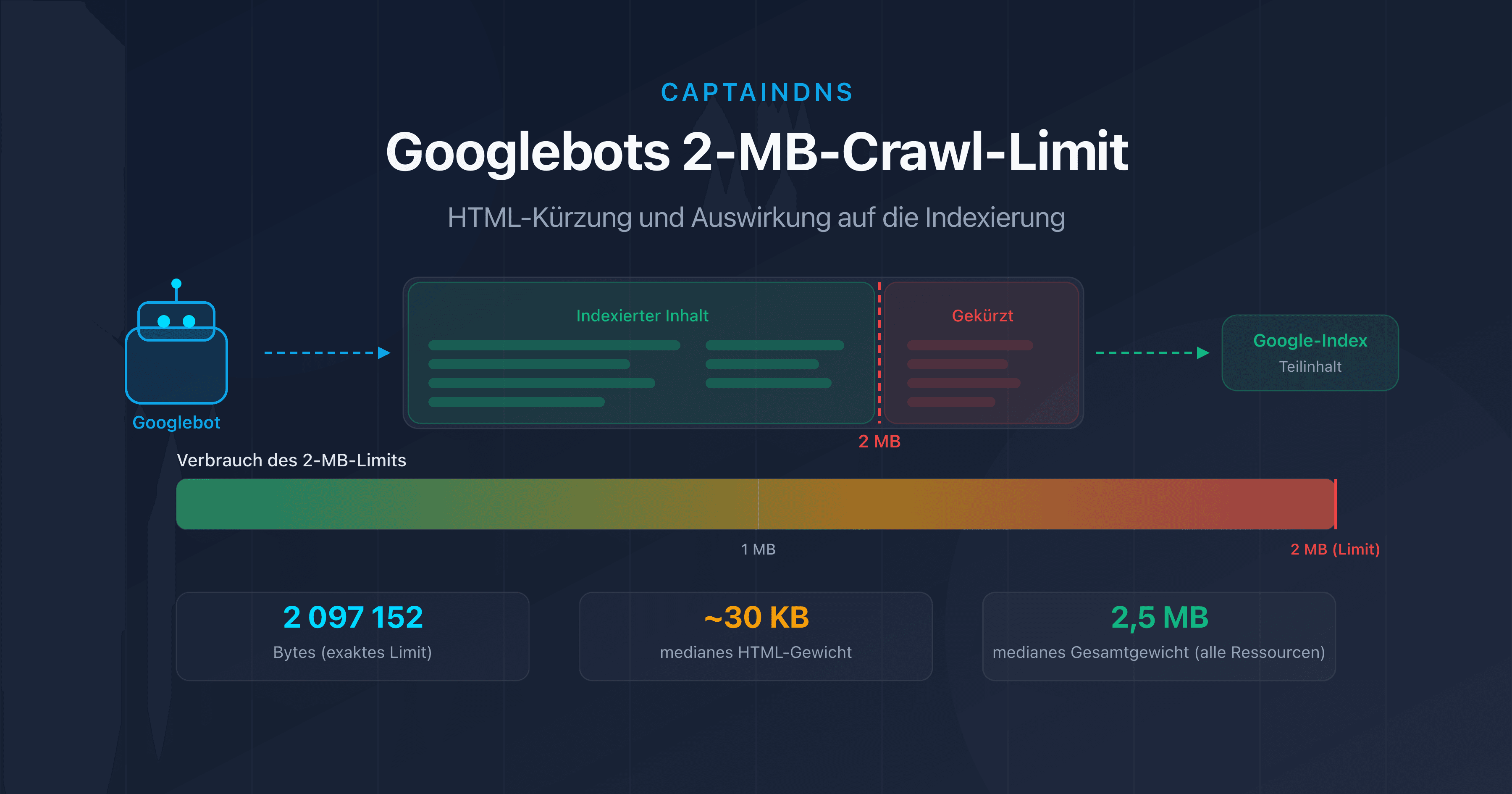
Schwere Seiten verbrauchen mehr Bandbreite und Downloadzeit, was das Crawling verlangsamt. Ab 2 MB HTML-Quellcode schneidet Googlebot den Inhalt sogar ab.
Die wirksamsten Maßnahmen:
- Inline-CSS und -JavaScript externalisieren.
- Base64-Bilder und Inline-SVGs entfernen.
- HTML minifizieren.
- Lange Listen paginieren.
6. Die Server-Antwortzeit verbessern
Je schneller dein Server antwortet, desto mehr erhöht Googlebot das crawl rate limit. Das Ziel: eine Server-Antwortzeit (TTFB) unter 200 ms.
Die wichtigsten Hebel:
- Serverseitiger Cache: Redis, Varnish oder ein CDN für statische Seiten.
- Datenbank: Langsame Abfragen optimieren, Indizes hinzufügen.
- Infrastruktur: ein Hosting, das für den erwarteten Traffic dimensioniert ist.
7. Crawl-Fallen vermeiden
Crawl-Fallen (Crawl Traps) sind Bereiche deiner Website, die eine quasi-unendliche Anzahl von URLs erzeugen. Googlebot kann sich darin verlieren und das gesamte Budget verbrauchen, ohne jemals deine wichtigen Seiten zu erreichen.
Typische Beispiele:
- Endlose Kalender: Jeder Monat erzeugt eine neue URL, ohne zeitliche Begrenzung.
- Kombinierte Facetten: Größe + Farbe + Preis + Marke = Tausende URLs.
- Sessions und IDs in der URL: Jeder Besucher erzeugt einzigartige URLs.
- Sortierung und Paginierung: Seite 1 sortiert nach Preis, Seite 1 sortiert nach Datum, Seite 1 sortiert nach Beliebtheit = 3 URLs für denselben Inhalt.
Der DNS-Faktor: der unsichtbare Einfluss auf das Crawl Budget
Deine robots.txt ist sauber, deine Sitemap ist tadellos, deine Seiten sind leicht. Trotzdem bleibt das Crawling langsam. Hast du deine DNS-Performance überprüft? Vor jeder HTTP-Anfrage muss Googlebot den Domainnamen deiner Website auflösen. Wenn diese Auflösung langsam ist, beginnt jede Crawl-Anfrage mit einem Nachteil.
DNS-Auflösung und Googlebot
Bei jeder Crawl-Sitzung führt Googlebot eine DNS-Auflösung durch, um die IP-Adresse deines Servers zu ermitteln. Wenn dein DNS-Server 200 ms statt 20 ms für die Antwort braucht, fügt das 180 ms Latenz zu jeder Anfrage hinzu.
Bei einer Crawl-Sitzung mit 1.000 Seiten bedeutet dieser Unterschied 180 Sekunden (3 Minuten) verlorene Zeit allein durch die DNS-Auflösung. Googlebot interpretiert diese Langsamkeit als Zeichen von Überlastung und senkt das crawl rate limit.
Optimaler TTL für das Crawling
Der TTL (Time To Live) deiner DNS-Einträge bestimmt, wie lange Googles DNS-Resolver die Antwort im Cache behält. Ein zu kurzer TTL (unter 300 Sekunden) erzwingt häufigere Auflösungen der Domain. Ein TTL zwischen 3.600 und 86.400 Sekunden (1 Stunde bis 24 Stunden) ist ein guter Kompromiss zwischen Reaktionsfähigkeit und Performance.
Wie du deine DNS-Performance testest
Überprüfe die DNS-Auflösungszeit deiner Domain mit Tools wie dig oder den DNS-Tools von CaptainDNS. Eine Auflösungszeit unter 50 ms ist ausgezeichnet. Ab 100 ms gibt es Optimierungspotenzial (Wahl des DNS-Anbieters, Anycast-Konfiguration, TTL).
Empfohlener Aktionsplan
- Dein Crawl Budget analysieren: Rufe den Bericht "Crawling-Statistiken" in Google Search Console auf. Notiere die Anzahl der Anfragen pro Tag, die durchschnittliche Antwortzeit und die Verteilung der Antwortcodes.
- Das Gewicht deiner kritischen Seiten testen: Verwende den Page Crawl Checker für deine wichtigsten Seiten. Identifiziere diejenigen, die 500 KB HTML-Quellcode überschreiten.
- Die 7 Techniken anwenden: Behebe defekte Links, bereinige deine Sitemap, eliminiere Duplikate, reduziere das Seitengewicht und überwache deine DNS-Performance. Miss die Auswirkungen in Search Console nach 2-4 Wochen.
FAQ
Was ist das Crawl Budget in der Suchmaschinenoptimierung?
Das Crawl Budget ist die Anzahl der Seiten, die Googlebot innerhalb eines bestimmten Zeitraums auf deiner Website crawlt. Es ergibt sich aus zwei Faktoren: dem crawl rate limit (maximale Anzahl der Anfragen, die dein Server verarbeiten kann) und dem crawl demand (Googles Interesse an deinen URLs). Seiten, die nicht gecrawlt werden, können nicht indexiert werden.
Betrifft das Crawl Budget auch kleine Websites?
Nein, für die große Mehrheit der Websites nicht. Google bestätigt, dass das Crawl Budget nur für Websites mit mehr als 10.000 einzigartigen URLs ein limitierender Faktor ist, oder für Websites, die über Facetten-Navigation, Sortierparameter und Paginierung viele URLs erzeugen. Wenn deine Website weniger als ein paar tausend Seiten hat, hat Googlebot kein Problem, alles zu crawlen.
Wie überprüfe ich mein Crawl Budget in Google Search Console?
Gehe in Google Search Console zu Einstellungen und klicke auf "Crawling-Statistiken". Dieser Bericht zeigt die Anzahl der Crawl-Anfragen pro Tag, die durchschnittliche Antwortzeit, die Größe der heruntergeladenen Seiten und die Verteilung der HTTP-Codes über die letzten 90 Tage. Ein Rückgang der Anfragen trotz neuer Inhalte deutet auf ein Crawl-Budget-Problem hin.
Was ist der Unterschied zwischen crawl rate limit und crawl demand?
Das crawl rate limit ist die technische Kapazität: die maximale Anzahl der Anfragen, die Googlebot an deinen Server sendet, ohne ihn zu überlasten. Der crawl demand ist Googles Interesse: wie viele Seiten Google tatsächlich crawlen möchte, basierend auf Popularität, Aktualität und Präsenz in der Sitemap. Das effektive Crawl Budget ist das Minimum aus beiden Werten.
Beeinflusst die robots.txt das Crawl Budget?
Ja. Die Disallow-Regeln der robots.txt verhindern, dass Googlebot die betreffenden URLs crawlt, wodurch Budget für wichtige Seiten freigesetzt wird. Achtung: Das Blockieren einer URL in robots.txt verhindert nicht ihre Indexierung, wenn sie externe Links erhält. Um eine Seite zu deindexieren, verwende das Meta-Tag noindex (was voraussetzt, dass die Seite crawlbar bleibt).
Verbrauchen Weiterleitungen Crawl Budget?
Ja. Jede Weiterleitung (301 oder 302) verbraucht eine Crawl-Anfrage. Googlebot folgt dem ursprünglichen Link, erhält die Weiterleitung und muss dann eine neue Anfrage an das Ziel senden. Redirect-Ketten (A auf B auf C auf D) vervielfachen die Verschwendung. Korrigiere Links so, dass sie direkt auf die endgültige URL verweisen.
Wie beeinflusst das Seitengewicht das Crawl Budget?
Je schwerer eine Seite im HTML ist, desto mehr Bandbreite und Downloadzeit verbraucht sie. Googlebot passt das crawl rate limit basierend auf der Antwortzeit an. Leichte Seiten (unter 100 KB HTML) ermöglichen mehr gecrawlte Seiten pro Sitzung. Ab 2 MB HTML-Quellcode schneidet Googlebot den Inhalt ab und indexiert ihn nur teilweise.
Teste deine Seiten jetzt: Verwende unseren Page Crawl Checker, um das HTML-Gewicht deiner Seiten und ihre Konformität mit dem 2-MB-Limit von Googlebot zu prüfen.
Verwandte Crawl- und Indexierungs-Leitfäden
- Googlebots 2-MB-Limit: Was passiert, wenn deine Seiten zu schwer sind: Teste, ob deine Seiten den Trunkierungsschwellenwert überschreiten.
- Medianes Seitengewicht 2025: Zahlen und Entwicklung
Quellen
- Google Search Central. Large site management and crawl budget: offizielle Dokumentation zum Crawl Budget.
- Google Developers. Googlebot overview: Funktionsweise von Googlebot und Crawl-Limits.
- HTTP Archive. Web Almanac: Statistiken zum Seitengewicht.
- web.dev. Optimize server response times (TTFB): Best Practices zur Reduzierung der Server-Antwortzeit.