Crawl budget: come comprendere e ottimizzare l'esplorazione del tuo sito da parte di Google
Di CaptainDNS
Pubblicato il 11 febbraio 2026
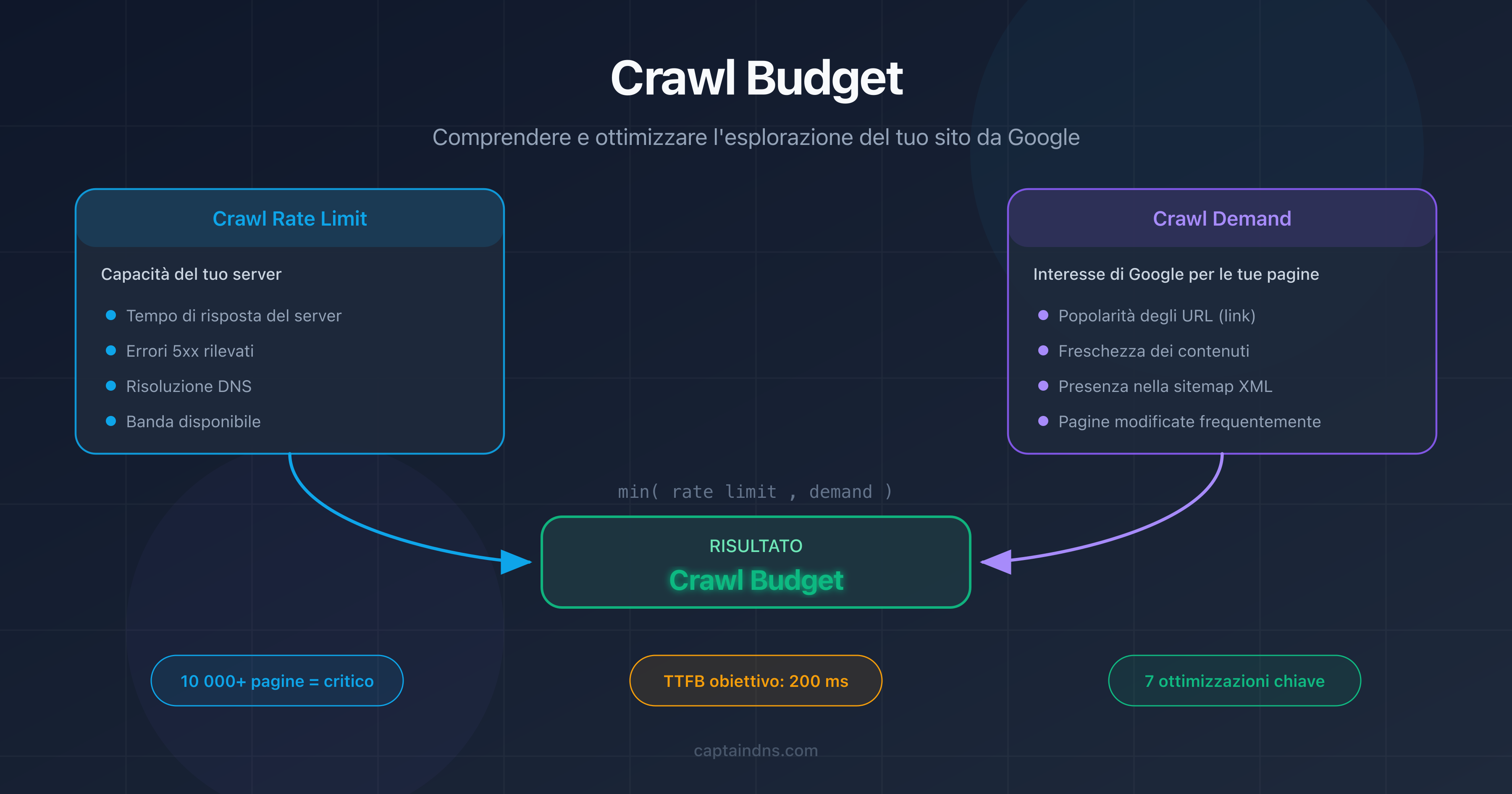
- Il crawl budget è il numero di pagine che Googlebot sceglie di esplorare sul tuo sito in un determinato periodo di tempo.
- Dipende da due fattori: il crawl rate limit (capacità del tuo server) e il crawl demand (interesse di Google per le tue pagine).
- Sui siti con più di 10.000 pagine, un crawl budget mal ottimizzato ritarda l'indicizzazione delle pagine importanti.
- Le pagine pesanti consumano più budget: testa il peso delle tue pagine con il nostro Page Crawl Checker.
Google esplora miliardi di pagine ogni giorno. Ma non tutte le tue. Il crawl budget è il numero di pagine che Googlebot sceglie di esplorare sul tuo sito in un determinato intervallo di tempo. Non ha nulla a che fare con un budget finanziario.
Il tuo sito ha meno di qualche migliaio di pagine? Allora il crawl budget probabilmente non è un problema. Google dispone di risorse sufficienti per esplorare tutto. Ma quando il tuo sito supera le 10.000 pagine, o la tua architettura genera migliaia di URL di filtraggio e paginazione, la gestione del crawl budget diventa una leva SEO fondamentale.
Questa guida copre tre aspetti: cos'è il crawl budget, come verificarlo in Google Search Console e 7 tecniche concrete per ottimizzarlo. Affrontiamo anche un fattore spesso ignorato: l'impatto delle prestazioni DNS sulla velocità di crawl.
Cos'è il crawl budget?
Il crawl budget è un concetto definito da Google che combina due fattori indipendenti: il crawl rate limit e il crawl demand.
Crawl rate limit: la capacità del tuo server
Il crawl rate limit rappresenta il numero massimo di richieste simultanee che Googlebot può inviare al tuo server senza sovraccaricarlo. Google regola questo limite automaticamente in base alla reattività del tuo sito.
Se il tuo server risponde velocemente (tempo di risposta inferiore a 200 ms), Googlebot aumenta il ritmo. Se le risposte rallentano o compaiono errori 5xx, riduce la frequenza per non aggravare la situazione.
Crawl demand: l'interesse di Google per le tue pagine
Il crawl demand riflette la volontà di Google di sottoporre a crawl le tue pagine. Diversi fattori lo influenzano:
- La popolarità delle tue URL: le pagine che ricevono link esterni o che generano traffico vengono sottoposte a crawl più spesso.
- La freschezza: le pagine che cambiano frequentemente (notizie, prezzi, disponibilità) vengono rivisitate più spesso rispetto alle pagine statiche.
- La presenza nel sitemap: le URL elencate nel tuo sitemap XML segnalano a Google che meritano di essere esplorate.
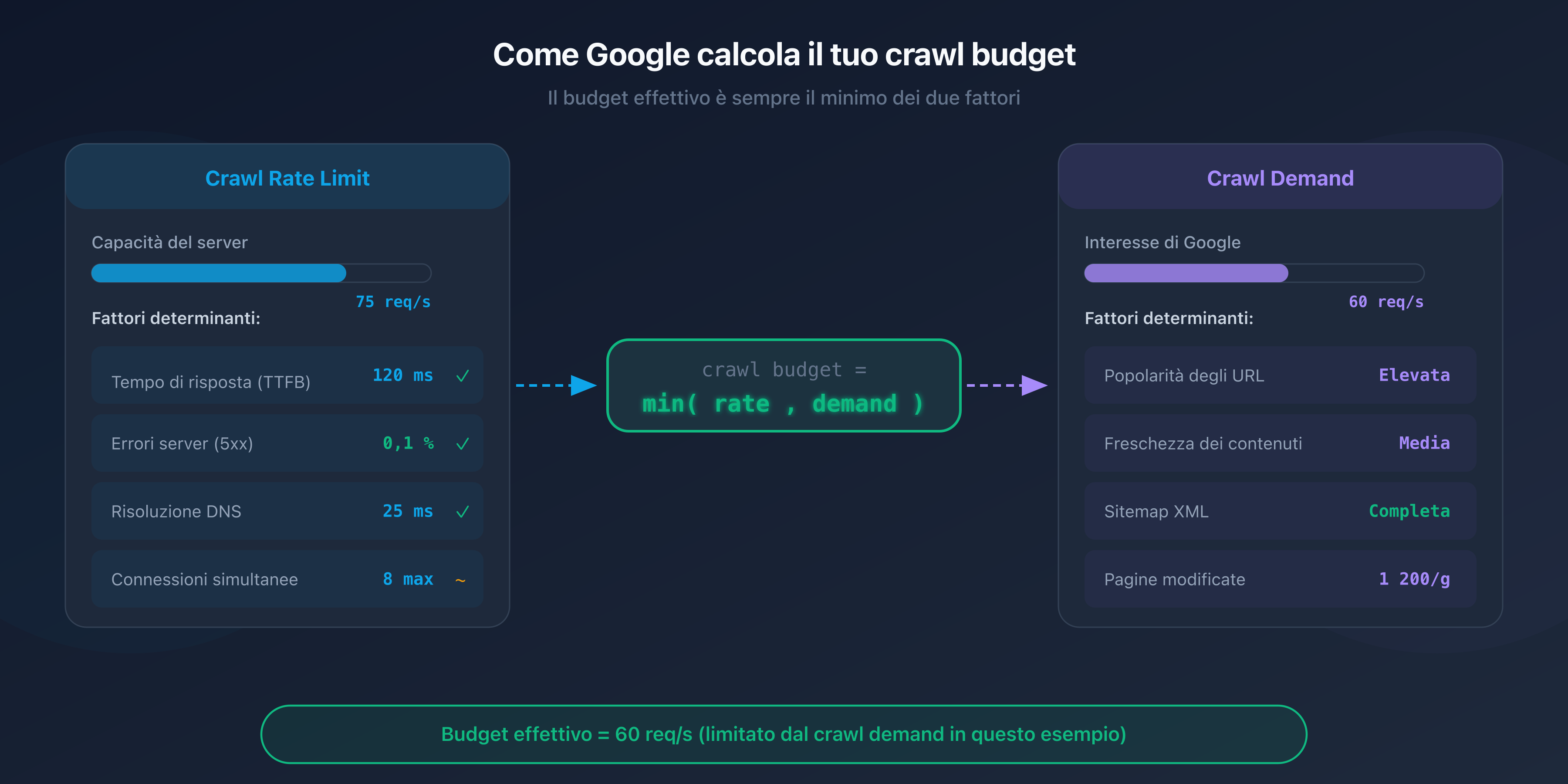
L'equazione del crawl budget
Il crawl budget effettivo del tuo sito è il minimo tra il crawl rate limit e il crawl demand:
Crawl budget = min(crawl rate limit, crawl demand)
In pratica: anche se il tuo server può supportare 100 richieste al secondo, Google non effettuerà il crawl di più pagine di quante ritenga necessarie. E viceversa, se Google vuole esplorare 50.000 pagine ma il tuo server supporta solo 5 richieste al secondo, il crawl sarà lento.
Perché il crawl budget è importante per la SEO?
Impatto sull'indicizzazione
Una pagina non sottoposta a crawl è una pagina non indicizzata. Se Googlebot non ha il tempo di esplorare alcune URL del tuo sito, queste non appariranno nei risultati di ricerca, anche se il loro contenuto è eccellente.
Il problema è particolarmente evidente sui siti di grandi dimensioni. Le pagine profonde, raggiungibili dopo 4-5 clic dalla homepage, vengono sottoposte a crawl meno spesso. Se il tuo crawl budget è limitato, queste pagine possono impiegare settimane, o addirittura mesi, prima di essere indicizzate.
Quando il crawl budget diventa un problema?
Google è esplicito: il crawl budget è un tema rilevante solo per i siti di grandi dimensioni. Ecco le situazioni in cui è necessario preoccuparsene:
- Siti con più di 10.000 URL uniche: e-commerce, directory, portali di contenuti.
- Siti con navigazione a faccette: le combinazioni di filtri (taglia, colore, prezzo, marca) generano migliaia di URL quasi identiche.
- Siti con contenuti duplicati: versioni HTTP e HTTPS, www e non-www, o parametri URL che creano duplicati.
- Siti con errori tecnici: le catene di redirect, gli errori 404 e le pagine soft-404 sprecano budget senza apportare nulla.
I siti più coinvolti
I siti e-commerce sono i primi colpiti. Un catalogo di 50.000 prodotti con 20 faccette di filtraggio può generare milioni di URL. Senza una gestione rigorosa del robots.txt e dei tag canonical, Googlebot passa il tempo a esplorare pagine di scarso valore a scapito delle schede prodotto strategiche.
Anche i siti media con archivi voluminosi, i forum e i siti di annunci sono interessati dal problema.
Come verificare il tuo crawl budget?
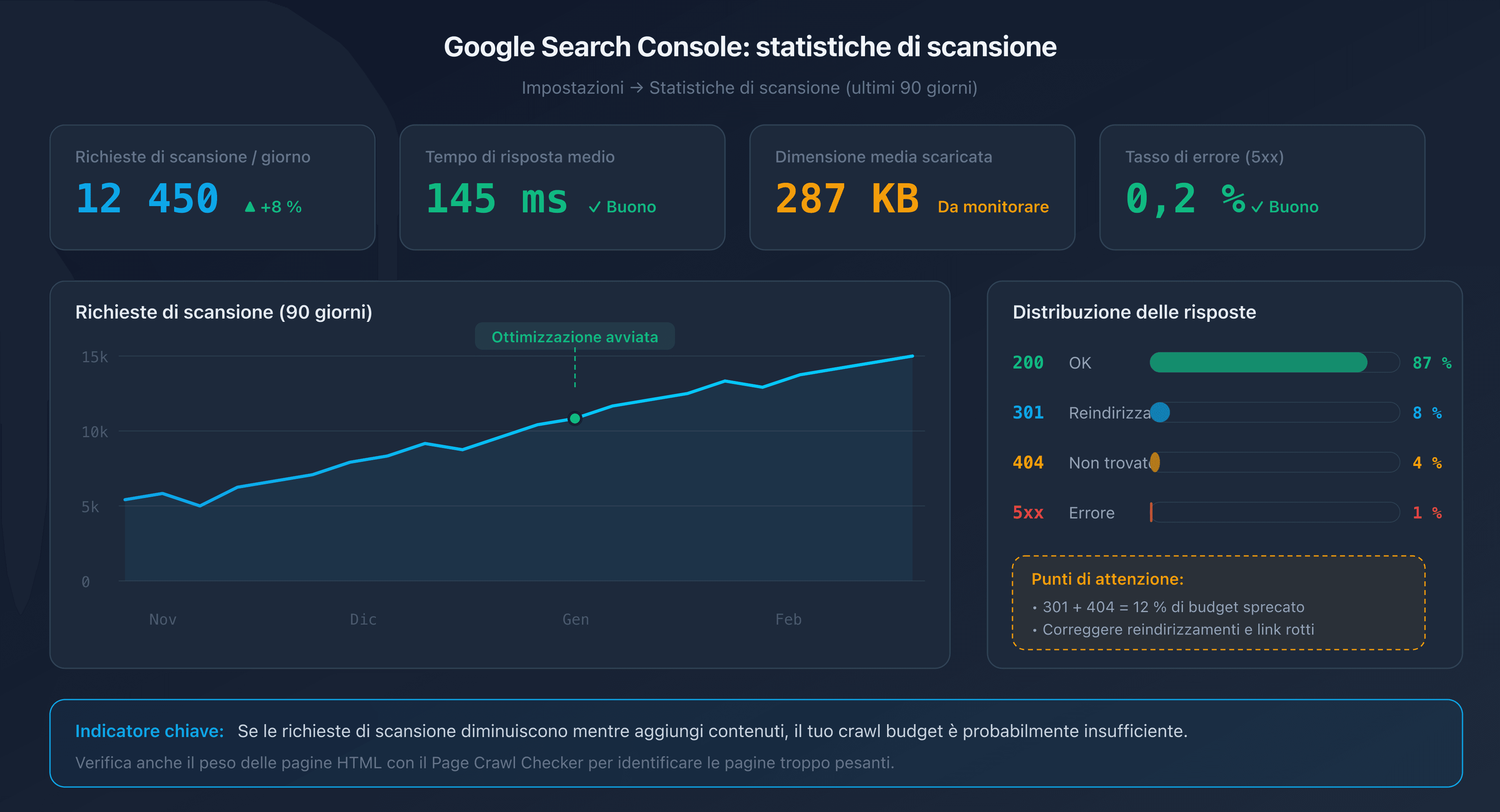
Report "Statistiche di scansione" in Google Search Console
Google Search Console fornisce un report dedicato nella sezione Impostazioni > Statistiche di scansione. Questo report mostra gli ultimi 90 giorni:
- Il numero totale di richieste di crawl al giorno.
- Il tempo di risposta medio del tuo server.
- La distribuzione per tipo di risposta (200, 301, 404, 5xx).
- La dimensione media delle pagine scaricate.
Un buon indicatore: se il numero di richieste di crawl diminuisce mentre aggiungi contenuti, il tuo crawl budget è probabilmente insufficiente.
Analisi dei log del server
I log del tuo server web (Apache, Nginx) registrano ogni visita di Googlebot. Analizzandoli, puoi identificare:
- Quali pagine vengono sottoposte a crawl più spesso (e quali non lo sono mai).
- I pattern di crawl (orari, frequenza, profondità).
- Gli errori restituiti a Googlebot.
Filtra le richieste il cui User-Agent contiene "Googlebot" per isolare il traffico del crawler.
URL Inspection Tool
Lo strumento di ispezione URL in Google Search Console permette di verificare lo stato individuale di una pagina: data dell'ultimo crawl, stato di indicizzazione e eventuali problemi rilevati.
7 tecniche per ottimizzare il tuo crawl budget
1. Correggere i link rotti e le catene di redirect
Ogni link rotto (404) e ogni catena di redirect (301 verso 301 verso 301) spreca una richiesta di crawl. Googlebot segue il link, riceve un errore o un redirect, e deve ricominciare. Risultato: budget consumato per niente.
Utilizza un crawler come Screaming Frog o Sitebulb per individuare i link rotti e le catene di redirect sul tuo sito. Correggi i link in modo che puntino direttamente alla destinazione finale.
2. Ottimizzare il robots.txt
Il file robots.txt permette di bloccare l'accesso di Googlebot alle sezioni inutili del tuo sito. Gli obiettivi classici:
- Pagine di amministrazione e back-office.
- Pagine dei risultati della ricerca interna.
- Pagine di filtraggio e ordinamento (faccette).
- File CSS/JS che non hanno bisogno di essere sottoposti a crawl individualmente.
# robots.txt - bloccare le pagine di filtraggio
User-agent: Googlebot
Disallow: /search?
Disallow: /filter/
Disallow: /sort/
Disallow: /admin/
Attenzione: bloccare una URL nel robots.txt impedisce il crawl, ma non la deindicizzazione. Se una pagina bloccata riceve link esterni, Google può comunque indicizzarla (senza effettuarne il crawl) basandosi sugli anchor dei link.
3. Pulire il sitemap XML
Il tuo sitemap XML deve contenere solo le URL che desideri vedere indicizzate. Rimuovi:
- Le URL che restituiscono errori 404 o redirect 301.
- Le URL bloccate dal robots.txt.
- Le URL con un tag
noindex. - Le pagine di scarsa qualità o i duplicati.
Un sitemap pulito indica a Google quali pagine meritano la sua attenzione. Se il tuo sitemap contiene 100.000 URL di cui solo 20.000 sono realmente utili, stai diluendo il segnale.
4. Eliminare i contenuti duplicati con i canonical
Le pagine duplicate sono uno spreco diretto di crawl budget. Googlebot effettua il crawl di ogni URL separatamente, anche se il contenuto è identico.
Utilizza il tag <link rel="canonical"> per indicare la versione preferita di una pagina. Esempi comuni:
- Parametri di tracking (
?utm_source=...). - Varianti di ordinamento e paginazione.
- Versioni HTTP/HTTPS o www/non-www.
5. Ridurre il peso delle pagine HTML
Le pagine pesanti consumano più larghezza di banda e tempo di download, rallentando il crawl. Oltre i 2 MB di HTML sorgente, Googlebot tronca direttamente il contenuto.
Le azioni più efficaci:
- Esternalizzare il CSS e il JavaScript inline.
- Eliminare le immagini in base64 e gli SVG inline.
- Minificare l'HTML.
- Paginare le liste lunghe.
6. Migliorare il tempo di risposta del server
Più veloce risponde il tuo server, più Googlebot aumenta il crawl rate limit. L'obiettivo: un tempo di risposta del server (TTFB) inferiore a 200 ms.
Le leve principali:
- Cache lato server: Redis, Varnish o un CDN per le pagine statiche.
- Database: ottimizzare le query lente, aggiungere indici.
- Infrastruttura: un hosting dimensionato per il traffico previsto.
7. Evitare le trappole di crawl
Le trappole di crawl (crawl trap) sono sezioni del tuo sito che generano un numero quasi infinito di URL. Googlebot può perdersi e consumare tutto il budget senza mai raggiungere le tue pagine importanti.
Esempi comuni:
- Calendari infiniti: ogni mese genera una nuova URL, senza limiti nel tempo.
- Faccette combinate: taglia + colore + prezzo + marca = migliaia di URL.
- Sessioni e identificativi nella URL: ogni visitatore genera URL uniche.
- Ordinamento e paginazione: pagina 1 ordinata per prezzo, pagina 1 ordinata per data, pagina 1 ordinata per popolarità = 3 URL per lo stesso contenuto.
Il fattore DNS: l'impatto invisibile sul crawl budget
Il tuo robots.txt è pulito, la tua sitemap è impeccabile, le tue pagine sono leggere. Eppure il crawl resta lento. Hai verificato le tue prestazioni DNS? Prima di ogni richiesta HTTP, Googlebot deve risolvere il nome di dominio del tuo sito. Se questa risoluzione è lenta, ogni richiesta di crawl parte con uno svantaggio.
Risoluzione DNS e Googlebot
Durante ogni sessione di crawl, Googlebot effettua una risoluzione DNS per localizzare l'indirizzo IP del tuo server. Se il tuo server DNS impiega 200 ms per rispondere invece di 20 ms, questo aggiunge 180 ms di latenza a ogni richiesta.
Su una sessione di crawl di 1.000 pagine, questa differenza si traduce in 180 secondi (3 minuti) di tempo perso esclusivamente per la risoluzione DNS. Googlebot interpreta questa lentezza come un segno di sovraccarico e riduce il crawl rate limit.
TTL ottimale per il crawl
Il TTL (Time To Live) dei tuoi record DNS determina per quanto tempo il resolver DNS di Google mantiene la risposta in cache. Un TTL troppo breve (meno di 300 secondi) obbliga a risolvere il dominio più spesso. Un TTL tra 3.600 e 86.400 secondi (da 1 ora a 24 ore) è un buon compromesso tra reattività e prestazioni.
Come testare le tue prestazioni DNS
Verifica il tempo di risoluzione DNS del tuo dominio con strumenti come dig o gli strumenti DNS di CaptainDNS. Un tempo di risoluzione inferiore a 50 ms è eccellente. Oltre 100 ms, c'è spazio per ottimizzare (scelta del provider DNS, configurazione anycast, TTL).
Piano d'azione consigliato
- Analizzare il tuo crawl budget: consulta il report "Statistiche di scansione" in Google Search Console. Annota il numero di richieste al giorno, il tempo di risposta medio e la distribuzione dei codici di risposta.
- Testare il peso delle tue pagine critiche: utilizza il Page Crawl Checker sulle tue pagine più importanti. Identifica quelle che superano 500 KB di HTML sorgente.
- Applicare le 7 tecniche: correggi i link rotti, pulisci il tuo sitemap, elimina i duplicati, riduci il peso delle pagine e monitora le tue prestazioni DNS. Misura l'impatto in Search Console dopo 2-4 settimane.
FAQ
Cos'è il crawl budget nella SEO?
Il crawl budget è il numero di pagine che Googlebot esplora sul tuo sito in un determinato intervallo di tempo. Dipende da due fattori: il crawl rate limit (numero massimo di richieste che il tuo server può gestire) e il crawl demand (interesse di Google per le tue URL). Le pagine non sottoposte a crawl non possono essere indicizzate.
Il crawl budget riguarda anche i siti piccoli?
No, per la grande maggioranza dei siti. Google conferma che il crawl budget è un fattore limitante solo per i siti con più di 10.000 URL uniche, o per i siti che generano molte URL tramite la navigazione a faccette, i parametri di ordinamento e la paginazione. Se il tuo sito ha meno di qualche migliaio di pagine, Googlebot non ha alcuna difficoltà a esplorare tutto.
Come verificare il proprio crawl budget in Google Search Console?
Vai in Google Search Console, sezione Impostazioni, poi clicca su "Statistiche di scansione". Questo report mostra il numero di richieste di crawl al giorno, il tempo di risposta medio, la dimensione delle pagine scaricate e la distribuzione dei codici HTTP sugli ultimi 90 giorni. Un calo delle richieste nonostante l'aggiunta di contenuti indica un problema di crawl budget.
Qual è la differenza tra crawl rate limit e crawl demand?
Il crawl rate limit è la capacità tecnica: il numero massimo di richieste che Googlebot invia al tuo server senza sovraccaricarlo. Il crawl demand è l'interesse di Google: quante pagine Google vuole effettivamente esplorare in base alla loro popolarità, freschezza e presenza nel sitemap. Il crawl budget effettivo è il minimo dei due.
Il robots.txt influisce sul crawl budget?
Sì. Le regole Disallow del robots.txt impediscono a Googlebot di effettuare il crawl delle URL interessate, liberando budget per le pagine importanti. Attenzione: bloccare una URL nel robots.txt non impedisce la sua indicizzazione se riceve link esterni. Per deindicizzare una pagina, utilizza il meta tag noindex (che richiede che la pagina sia sottoposta a crawl).
I redirect consumano crawl budget?
Sì. Ogni redirect (301 o 302) consuma una richiesta di crawl. Googlebot segue il link iniziale, riceve il redirect, poi deve effettuare una nuova richiesta verso la destinazione. Le catene di redirect (A verso B verso C verso D) moltiplicano lo spreco. Correggi i link per puntare direttamente all'URL finale.
Come il peso delle pagine influisce sul crawl budget?
Più una pagina è pesante in HTML, più consuma larghezza di banda e tempo di download. Googlebot regola il crawl rate limit in base al tempo di risposta. Pagine leggere (meno di 100 KB di HTML) permettono di sottoporre a crawl più pagine per sessione. Oltre i 2 MB di HTML sorgente, Googlebot tronca il contenuto e lo indicizza solo parzialmente.
Testa le tue pagine ora: utilizza il nostro Page Crawl Checker per verificare il peso delle tue pagine HTML e la loro conformità con il limite di 2 MB di Googlebot.
Guide su crawl e indicizzazione correlate
- Limite di 2 MB di Googlebot: cosa succede quando le tue pagine sono troppo pesanti: testa se le tue pagine superano la soglia di troncamento.
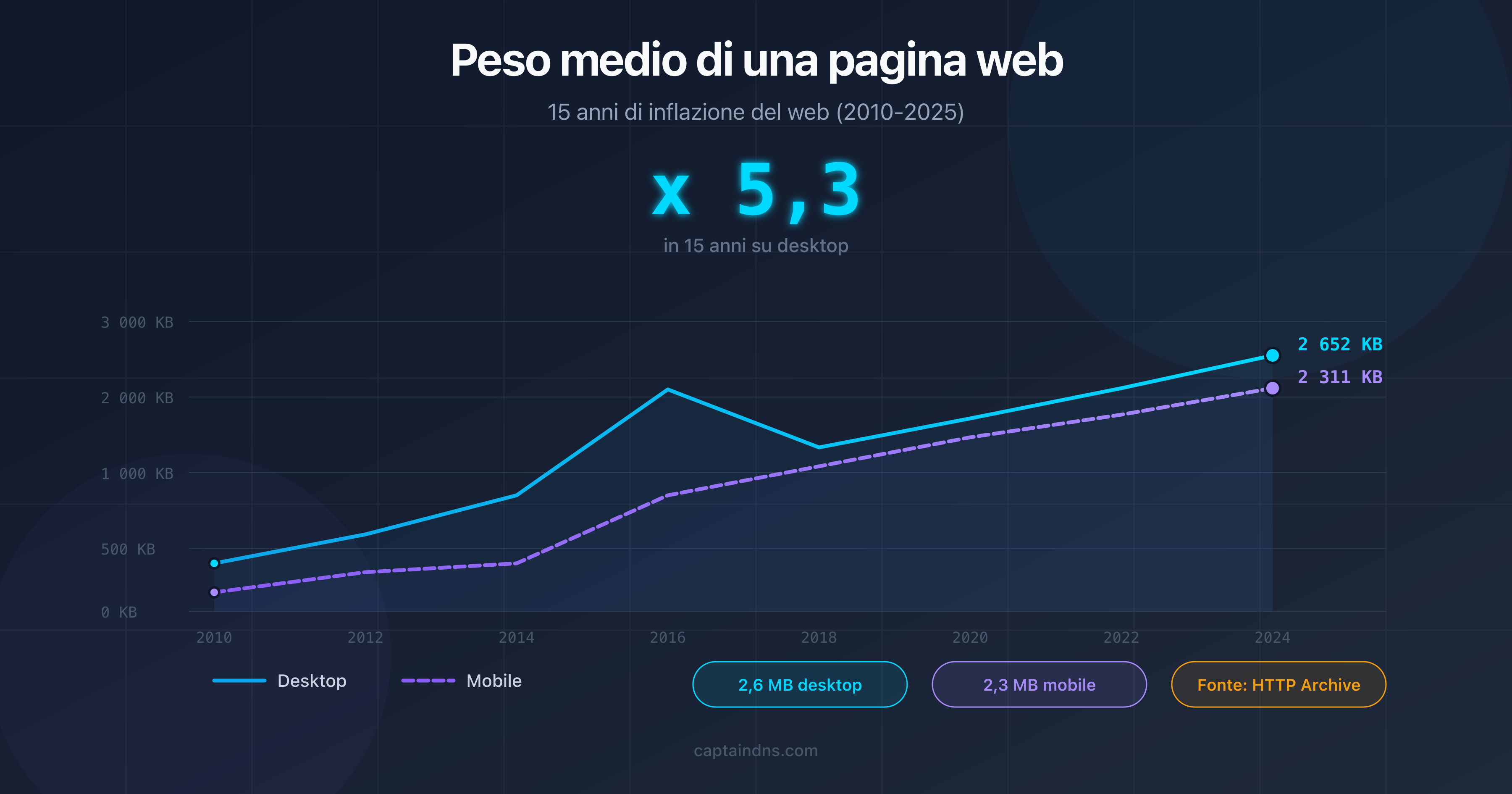
- Peso medio di una pagina web nel 2025: dati e tendenze
Fonti
- Google Search Central. Large site management and crawl budget: documentazione ufficiale sul crawl budget.
- Google Developers. Googlebot overview: funzionamento di Googlebot e limiti di crawl.
- HTTP Archive. Web Almanac: statistiche sul peso delle pagine web.
- web.dev. Optimize server response times (TTFB): buone pratiche per ridurre il tempo di risposta del server.