Crawl budget: entenda e otimize a exploração do seu site pelo Google
Por CaptainDNS
Publicado em 11 de fevereiro de 2026
- O crawl budget é o número de páginas que o Googlebot escolhe explorar no seu site em um determinado período.
- Ele resulta de dois fatores: o crawl rate limit (capacidade do seu servidor) e o crawl demand (interesse do Google pelas suas páginas).
- Em sites com mais de 10.000 páginas, um crawl budget mal otimizado atrasa a indexação de páginas importantes.
- Páginas pesadas consomem mais budget: teste o peso das suas páginas com nosso Page Crawl Checker.
O Google explora bilhões de páginas todos os dias. Mas não todas as suas. O crawl budget é o número de páginas que o Googlebot escolhe explorar no seu site em um determinado intervalo de tempo. Não tem nada a ver com dinheiro.
O seu site tem menos de alguns milhares de páginas? Então o crawl budget provavelmente não é um problema. O Google tem recursos suficientes para explorar tudo. Porém, quando o seu site ultrapassa 10.000 páginas, ou quando a sua arquitetura gera milhares de URLs de filtragem e paginação, a gestão do crawl budget se torna uma alavanca SEO importante.
Este guia cobre três pontos: o que é o crawl budget, como verificá-lo no Google Search Console e 7 técnicas concretas para otimizá-lo. Também abordamos um fator frequentemente ignorado: o impacto do desempenho DNS na velocidade de rastreio.
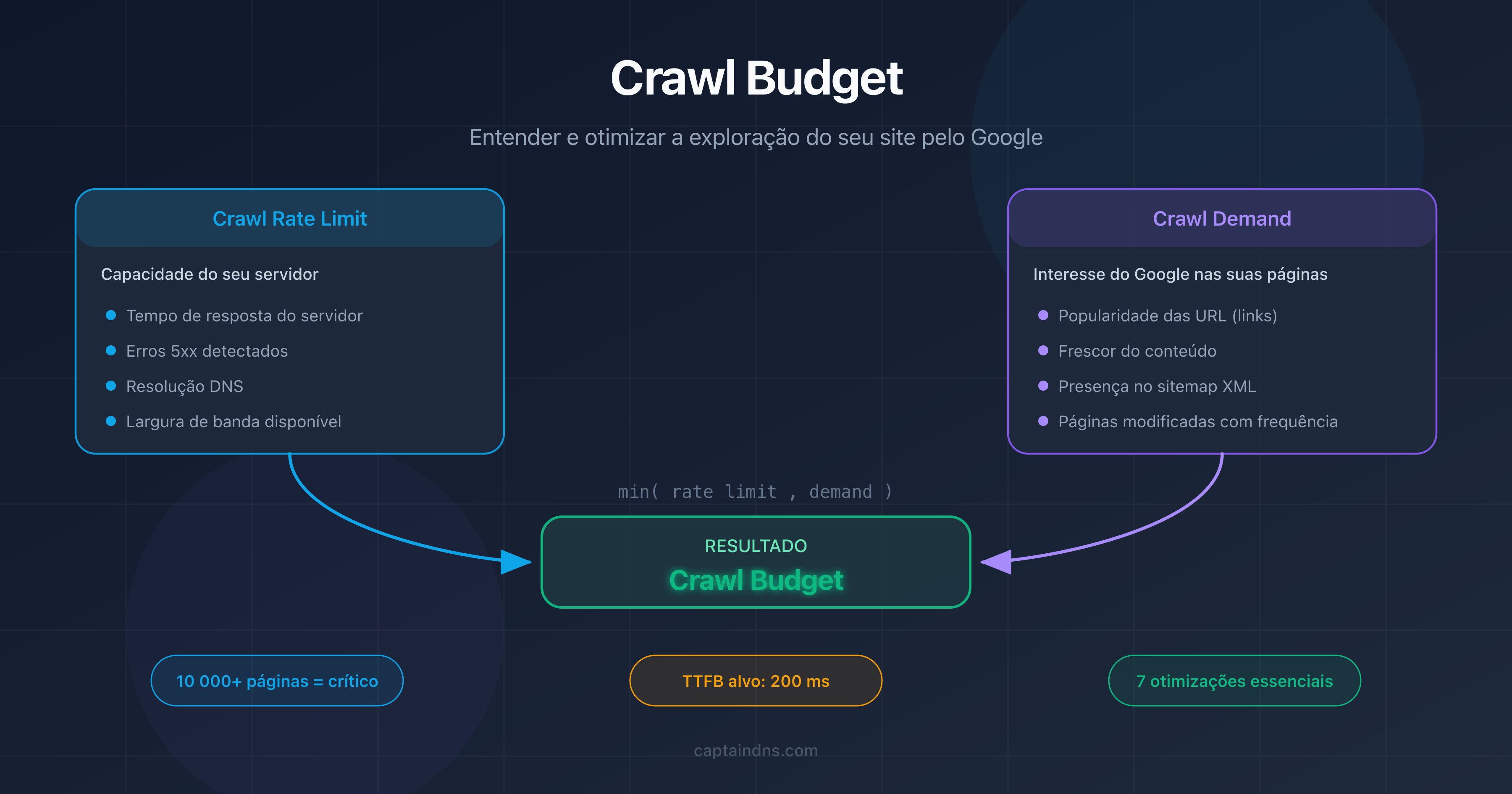
O que é o crawl budget?
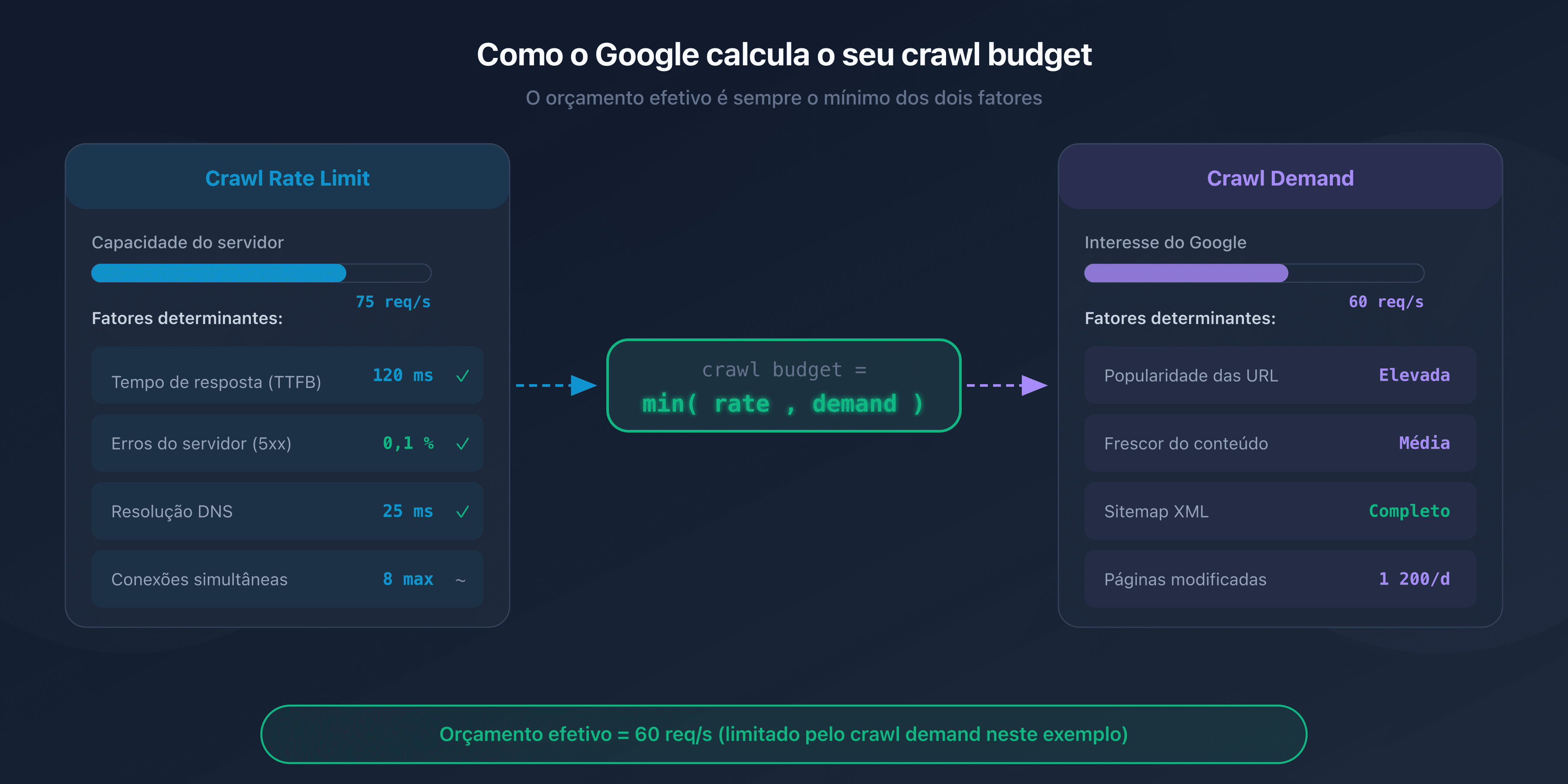
O crawl budget é um conceito definido pelo Google que combina dois fatores independentes: o crawl rate limit e o crawl demand.
Crawl rate limit: a capacidade do seu servidor
O crawl rate limit representa o número máximo de requisições simultâneas que o Googlebot pode enviar ao seu servidor sem sobrecarregá-lo. O Google ajusta esse limite automaticamente com base na responsividade do seu site.
Se o seu servidor responde rápido (tempo de resposta inferior a 200 ms), o Googlebot aumenta o ritmo. Se as respostas ficam mais lentas ou surgem erros 5xx, ele reduz a cadência para não agravar a situação.
Crawl demand: o interesse do Google pelas suas páginas
O crawl demand reflete a vontade do Google de rastrear suas páginas. Diversos fatores o influenciam:
- A popularidade das suas URLs: páginas que recebem links externos ou que geram tráfego são rastreadas com mais frequência.
- A atualização: páginas que mudam frequentemente (notícias, preços, estoque) são revisitadas com mais frequência do que páginas estáticas.
- A presença no sitemap: URLs listadas no seu sitemap XML sinalizam ao Google que merecem ser exploradas.
A equação do crawl budget
O crawl budget efetivo do seu site é o mínimo entre o crawl rate limit e o crawl demand:
Crawl budget = min(crawl rate limit, crawl demand)
Na prática: mesmo que o seu servidor suporte 100 requisições por segundo, o Google não rastreará mais páginas do que julga necessário. E, inversamente, se o Google quer explorar 50.000 páginas mas o seu servidor suporta apenas 5 requisições por segundo, o rastreio será lento.
Por que o crawl budget é importante para o SEO?
Impacto na indexação
Uma página não rastreada é uma página não indexada. Se o Googlebot não tem tempo de explorar certas URLs do seu site, elas não aparecerão nos resultados de busca, mesmo que o conteúdo seja excelente.
O problema é particularmente visível em sites grandes. Páginas profundas, acessíveis após 4-5 cliques a partir da página inicial, são rastreadas com menor frequência. Se o seu crawl budget é limitado, essas páginas podem levar semanas, ou até meses, para serem indexadas.
Quando o crawl budget se torna um problema?
O Google é explícito: o crawl budget só é relevante para sites grandes. Veja as situações em que é preciso se preocupar:
- Sites com mais de 10.000 URLs únicas: e-commerce, diretórios, portais de conteúdo.
- Sites com navegação facetada: as combinações de filtros (tamanho, cor, preço, marca) geram milhares de URLs quase idênticas.
- Sites com conteúdo duplicado: versões HTTP e HTTPS, www e sem www, ou parâmetros de URL que criam duplicatas.
- Sites com erros técnicos: cadeias de redirecionamentos, erros 404 e páginas soft-404 desperdiçam budget sem trazer nenhum benefício.
Os sites mais afetados
Os sites de e-commerce são os primeiros afetados. Um catálogo de 50.000 produtos com 20 facetas de filtragem pode gerar milhões de URLs. Sem uma gestão rigorosa do robots.txt e das tags canonical, o Googlebot gasta seu tempo rastreando páginas de baixo valor em detrimento das fichas de produto estratégicas.
Sites de mídia com arquivos volumosos, fóruns e sites de classificados também são afetados.
Como verificar seu crawl budget?
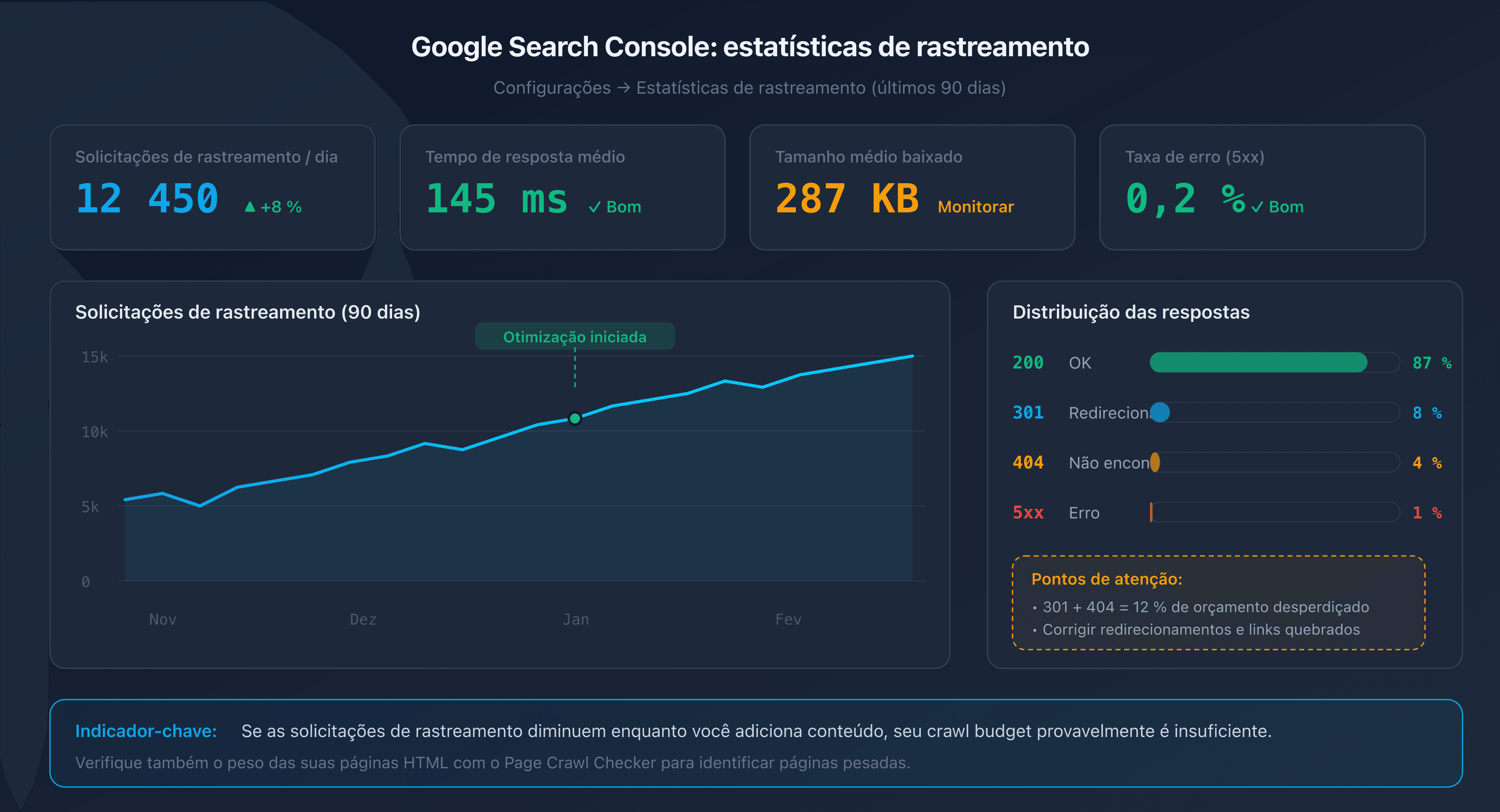
Relatório "Estatísticas de rastreio" no Google Search Console
O Google Search Console oferece um relatório dedicado na seção Configurações > Estatísticas de rastreio. Esse relatório exibe os últimos 90 dias:
- O número total de requisições de rastreio por dia.
- O tempo de resposta médio do seu servidor.
- A distribuição por tipo de resposta (200, 301, 404, 5xx).
- O tamanho médio das páginas baixadas.
Um bom indicador: se o número de requisições de rastreio diminui enquanto você adiciona conteúdo, seu crawl budget provavelmente é insuficiente.
Análise dos logs do servidor
Os logs do seu servidor web (Apache, Nginx) registram cada visita do Googlebot. Ao analisá-los, você pode identificar:
- Quais páginas são rastreadas com mais frequência (e quais nunca são).
- Os padrões de rastreio (horários, frequência, profundidade).
- Os erros retornados ao Googlebot.
Filtre as requisições cujo User-Agent contém "Googlebot" para isolar o tráfego do crawler.
URL Inspection Tool
A ferramenta de inspeção de URL no Google Search Console permite verificar o estado individual de uma página: data do último rastreio, status de indexação e eventuais problemas detectados.
7 técnicas para otimizar seu crawl budget
1. Corrigir links quebrados e cadeias de redirecionamentos
Cada link quebrado (404) e cada cadeia de redirecionamentos (301 para 301 para 301) desperdiça uma requisição de rastreio. O Googlebot segue o link, recebe um erro ou redirecionamento, e precisa recomeçar. Resultado: budget consumido sem nenhum retorno.
Use um crawler como Screaming Frog ou Sitebulb para detectar links quebrados e cadeias de redirecionamentos no seu site. Corrija os links para apontar diretamente ao destino final.
2. Otimizar o robots.txt
O arquivo robots.txt permite bloquear o acesso do Googlebot a seções desnecessárias do seu site. Os alvos clássicos:
- Páginas de administração e back-office.
- Páginas de resultados de busca interna.
- Páginas de filtragem e ordenação (facetas).
- Arquivos CSS/JS que não precisam ser rastreados individualmente.
# robots.txt - bloquear páginas de filtragem
User-agent: Googlebot
Disallow: /search?
Disallow: /filter/
Disallow: /sort/
Disallow: /admin/
Atenção: bloquear uma URL no robots.txt impede o rastreio, mas não a desindexação. Se uma página bloqueada recebe links externos, o Google ainda pode indexá-la (sem rastreá-la) com base nas âncoras dos links.
3. Limpar o sitemap XML
Seu sitemap XML deve conter apenas as URLs que você deseja ver indexadas. Remova:
- URLs que retornam erros 404 ou redirecionamentos 301.
- URLs bloqueadas pelo robots.txt.
- URLs com tag
noindex. - Páginas de baixa qualidade ou duplicatas.
Um sitemap limpo indica ao Google quais páginas merecem sua atenção. Se o seu sitemap contém 100.000 URLs das quais apenas 20.000 são realmente úteis, você dilui o sinal.
4. Eliminar conteúdo duplicado com canonical
Páginas duplicadas são um desperdício direto de crawl budget. O Googlebot rastreia cada URL separadamente, mesmo que o conteúdo seja idêntico.
Use a tag <link rel="canonical"> para indicar a versão preferida de uma página. Exemplos comuns:
- Parâmetros de tracking (
?utm_source=...). - Variantes de ordenação e paginação.
- Versões HTTP/HTTPS ou www/sem www.
5. Reduzir o peso das páginas HTML
Páginas pesadas consomem mais largura de banda e tempo de download, o que desacelera o rastreio. Acima de 2 MB de HTML fonte, o Googlebot trunca o conteúdo.
As ações mais eficazes:
- Externalizar o CSS e o JavaScript inline.
- Remover imagens em base64 e SVGs inline.
- Minificar o HTML.
- Paginar listas longas.
6. Melhorar o tempo de resposta do servidor
Quanto mais rápido o seu servidor responde, mais o Googlebot aumenta o crawl rate limit. O objetivo: um tempo de resposta do servidor (TTFB) inferior a 200 ms.
As principais alavancas:
- Cache do lado do servidor: Redis, Varnish ou um CDN para páginas estáticas.
- Banco de dados: otimizar consultas lentas, adicionar índices.
- Infraestrutura: uma hospedagem dimensionada para o tráfego esperado.
7. Evitar armadilhas de rastreio
As armadilhas de rastreio (crawl traps) são seções do seu site que geram um número quase infinito de URLs. O Googlebot pode se perder nelas e consumir todo o budget sem jamais alcançar suas páginas importantes.
Exemplos comuns:
- Calendários infinitos: cada mês gera uma nova URL, sem limite no tempo.
- Facetas combinadas: tamanho + cor + preço + marca = milhares de URLs.
- Sessões e identificadores na URL: cada visitante gera URLs únicas.
- Ordenação e paginação: página 1 ordenada por preço, página 1 ordenada por data, página 1 ordenada por popularidade = 3 URLs para o mesmo conteúdo.
O fator DNS: o impacto invisível no crawl budget
Seu robots.txt está limpo, sua sitemap é impecável, suas páginas são leves. Mesmo assim, o rastreio continua lento. Você verificou o desempenho DNS? Antes de cada requisição HTTP, o Googlebot precisa resolver o nome de domínio do seu site. Se essa resolução é lenta, cada requisição de rastreio começa com uma desvantagem.
Resolução DNS e Googlebot
Em cada sessão de rastreio, o Googlebot realiza uma resolução DNS para localizar o endereço IP do seu servidor. Se o seu servidor DNS leva 200 ms para responder em vez de 20 ms, isso adiciona 180 ms de latência a cada requisição.
Em uma sessão de rastreio de 1.000 páginas, essa diferença se traduz em 180 segundos (3 minutos) de tempo perdido apenas na resolução DNS. O Googlebot interpreta essa lentidão como sinal de sobrecarga e reduz o crawl rate limit.
TTL ideal para o rastreio
O TTL (Time To Live) dos seus registros DNS determina por quanto tempo o resolvedor DNS do Google mantém a resposta em cache. Um TTL muito curto (menos de 300 segundos) obriga a resolver o domínio com mais frequência. Um TTL entre 3.600 e 86.400 segundos (1 hora a 24 horas) é um bom equilíbrio entre reatividade e desempenho.
Como testar o desempenho do seu DNS
Verifique o tempo de resolução DNS do seu domínio com ferramentas como dig ou as ferramentas DNS do CaptainDNS. Um tempo de resolução inferior a 50 ms é excelente. Acima de 100 ms, há espaço para otimização (escolha do provedor DNS, configuração Anycast, TTL).
Plano de ação recomendado
- Analise seu crawl budget: consulte o relatório "Estatísticas de rastreio" no Google Search Console. Anote o número de requisições por dia, o tempo de resposta médio e a distribuição dos códigos de resposta.
- Teste o peso das suas páginas críticas: use o Page Crawl Checker nas suas páginas mais importantes. Identifique as que ultrapassam 500 KB de HTML fonte.
- Aplique as 7 técnicas: corrija os links quebrados, limpe seu sitemap, elimine as duplicatas, reduza o peso das páginas e monitore o desempenho do seu DNS. Meça o impacto no Search Console após 2 a 4 semanas.
FAQ
O que é o crawl budget em SEO?
O crawl budget é o número de páginas que o Googlebot explora no seu site em um determinado intervalo de tempo. Ele resulta de dois fatores: o crawl rate limit (número máximo de requisições que o seu servidor pode absorver) e o crawl demand (interesse do Google pelas suas URLs). As páginas não rastreadas não podem ser indexadas.
O crawl budget é relevante para sites pequenos?
Não, para a grande maioria dos sites. O Google confirma que o crawl budget só é um fator limitante para sites com mais de 10.000 URLs únicas, ou para sites que geram muitas URLs por meio de navegação facetada, parâmetros de ordenação e paginação. Se o seu site tem menos de alguns milhares de páginas, o Googlebot não tem nenhuma dificuldade em explorar tudo.
Como verificar o crawl budget no Google Search Console?
Acesse o Google Search Console, seção Configurações, e clique em "Estatísticas de rastreio". Esse relatório exibe o número de requisições de rastreio por dia, o tempo de resposta médio, o tamanho das páginas baixadas e a distribuição dos códigos HTTP nos últimos 90 dias. Uma queda no número de requisições apesar da adição de conteúdo indica um problema de crawl budget.
Qual é a diferença entre crawl rate limit e crawl demand?
O crawl rate limit é a capacidade técnica: o número máximo de requisições que o Googlebot envia ao seu servidor sem sobrecarregá-lo. O crawl demand é o interesse do Google: quantas páginas ele efetivamente quer explorar com base na popularidade, atualização e presença no sitemap. O crawl budget efetivo é o mínimo entre os dois.
O robots.txt afeta o crawl budget?
Sim. As regras Disallow do robots.txt impedem o Googlebot de rastrear as URLs em questão, o que libera budget para as páginas importantes. Atenção: bloquear uma URL no robots.txt não impede sua indexação se ela recebe links externos. Para desindexar uma página, use a tag meta noindex (que exige que a página seja rastreável).
Os redirecionamentos consomem crawl budget?
Sim. Cada redirecionamento (301 ou 302) consome uma requisição de rastreio. O Googlebot segue o link inicial, recebe o redirecionamento e precisa fazer uma nova requisição para o destino. Cadeias de redirecionamentos (A para B para C para D) multiplicam o desperdício. Corrija os links para apontar diretamente à URL final.
Como o peso das páginas afeta o crawl budget?
Quanto mais pesada uma página em HTML, mais largura de banda e tempo de download ela consome. O Googlebot ajusta o crawl rate limit com base no tempo de resposta. Páginas leves (menos de 100 KB de HTML) permitem rastrear mais páginas por sessão. Acima de 2 MB de HTML fonte, o Googlebot trunca o conteúdo e o indexa apenas parcialmente.
Teste suas páginas agora: use nosso Page Crawl Checker para verificar o peso das suas páginas HTML e a conformidade com o limite de 2 MB do Googlebot.
Guias de rastreio e indexação relacionados
- Limite de 2 MB do Googlebot: o que acontece quando suas páginas são pesadas demais: teste se suas páginas ultrapassam o limite de truncagem.
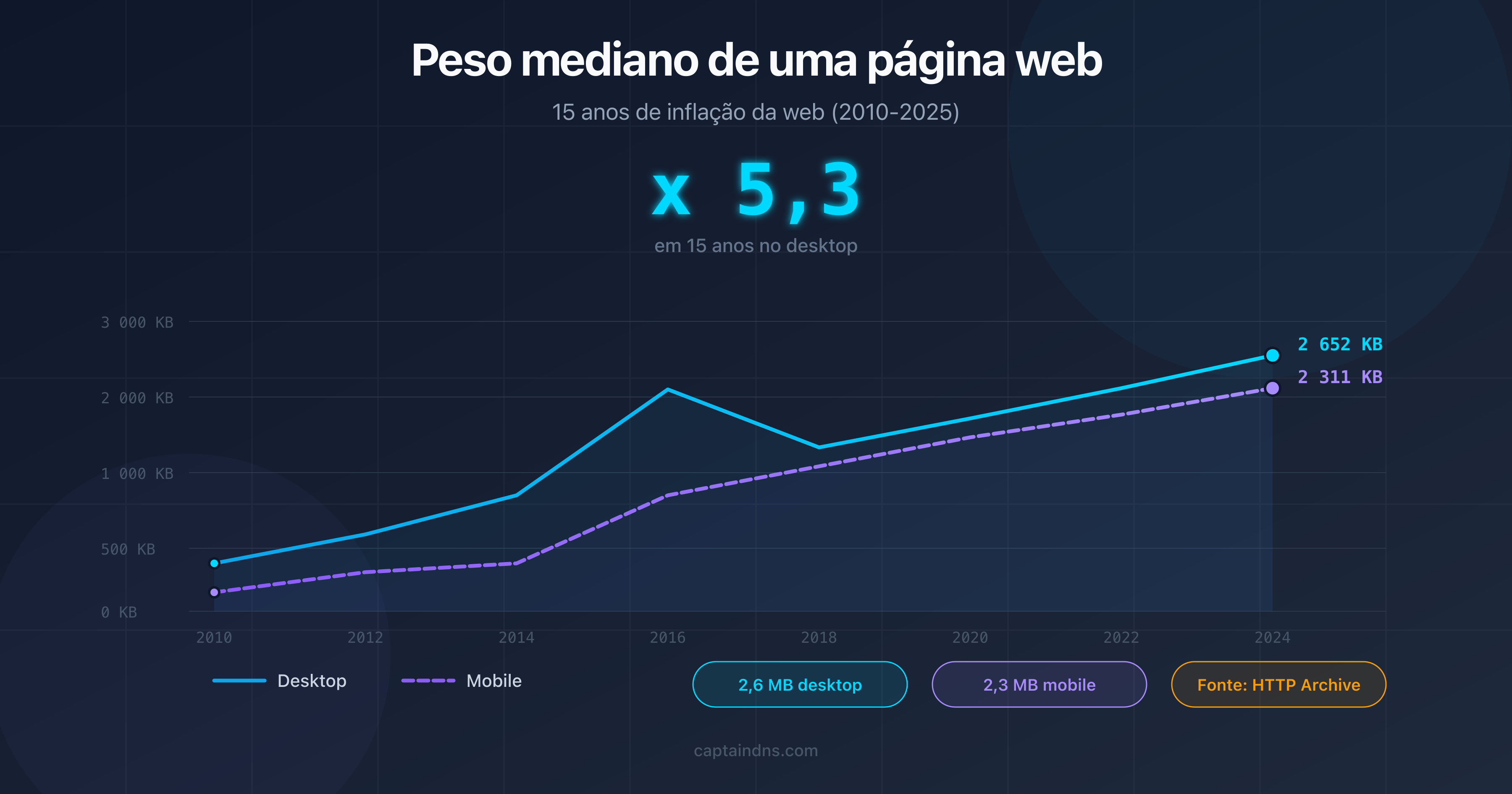
- Peso mediano de uma página web em 2025: dados e evolução
Fontes
- Google Search Central. Large site management and crawl budget: documentação oficial sobre o crawl budget.
- Google Developers. Googlebot overview: funcionamento do Googlebot e limites de rastreio.
- HTTP Archive. Web Almanac: estatísticas sobre o peso das páginas web.
- web.dev. Optimize server response times (TTFB): boas práticas para reduzir o tempo de resposta do servidor.