Budget de crawl : comprendre et optimiser l'exploration de votre site par Google
Par CaptainDNS
Publié le 11 février 2026
- Le budget de crawl est le nombre de pages que Googlebot choisit d'explorer sur votre site dans un laps de temps donné.
- Il résulte de deux facteurs : le crawl rate limit (capacité de votre serveur) et le crawl demand (intérêt de Google pour vos pages).
- Sur les sites de plus de 10 000 pages, un crawl budget mal optimisé retarde l'indexation de pages importantes.
- Les pages lourdes consomment plus de budget : testez le poids de vos pages avec notre Page Crawl Checker.
Google explore des milliards de pages chaque jour. Mais pas toutes les vôtres. Le crawl budget, c'est le nombre de pages que Googlebot choisit d'explorer sur votre site dans un intervalle de temps donné. Rien à voir avec un budget financier.
Votre site fait moins de quelques milliers de pages ? Le crawl budget n'est probablement pas un problème. Google a suffisamment de ressources pour tout explorer. Mais dès que votre site dépasse 10 000 pages, ou que votre architecture génère des milliers d'URL de filtrage et de pagination, la gestion du crawl budget devient un levier SEO majeur.
Ce guide couvre trois points : ce qu'est le crawl budget, comment le vérifier dans Google Search Console, et 7 techniques concrètes pour l'optimiser. Nous abordons aussi un facteur souvent ignoré : l'impact des performances DNS sur la vitesse de crawl.
Qu'est-ce que le budget de crawl ?
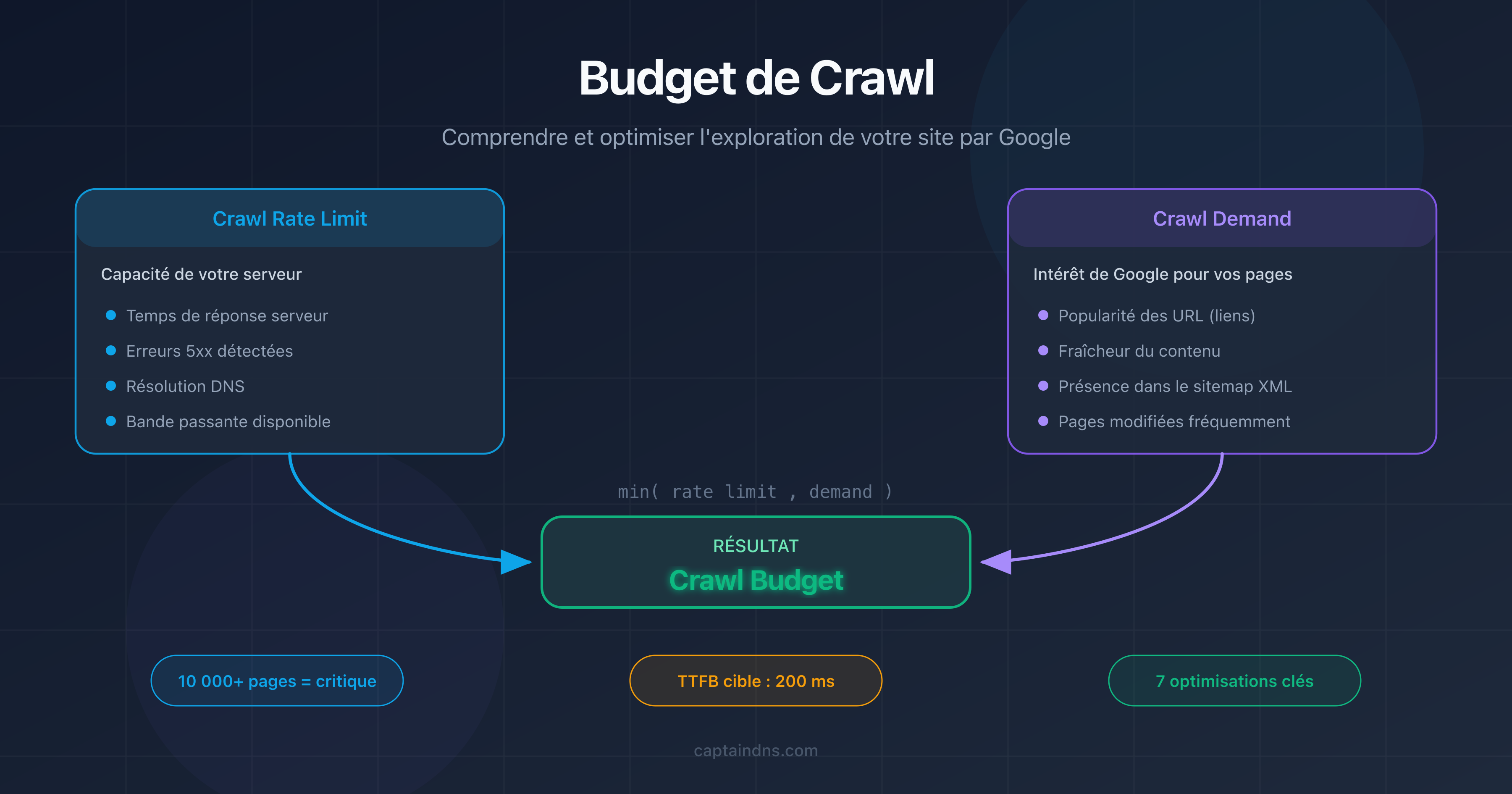
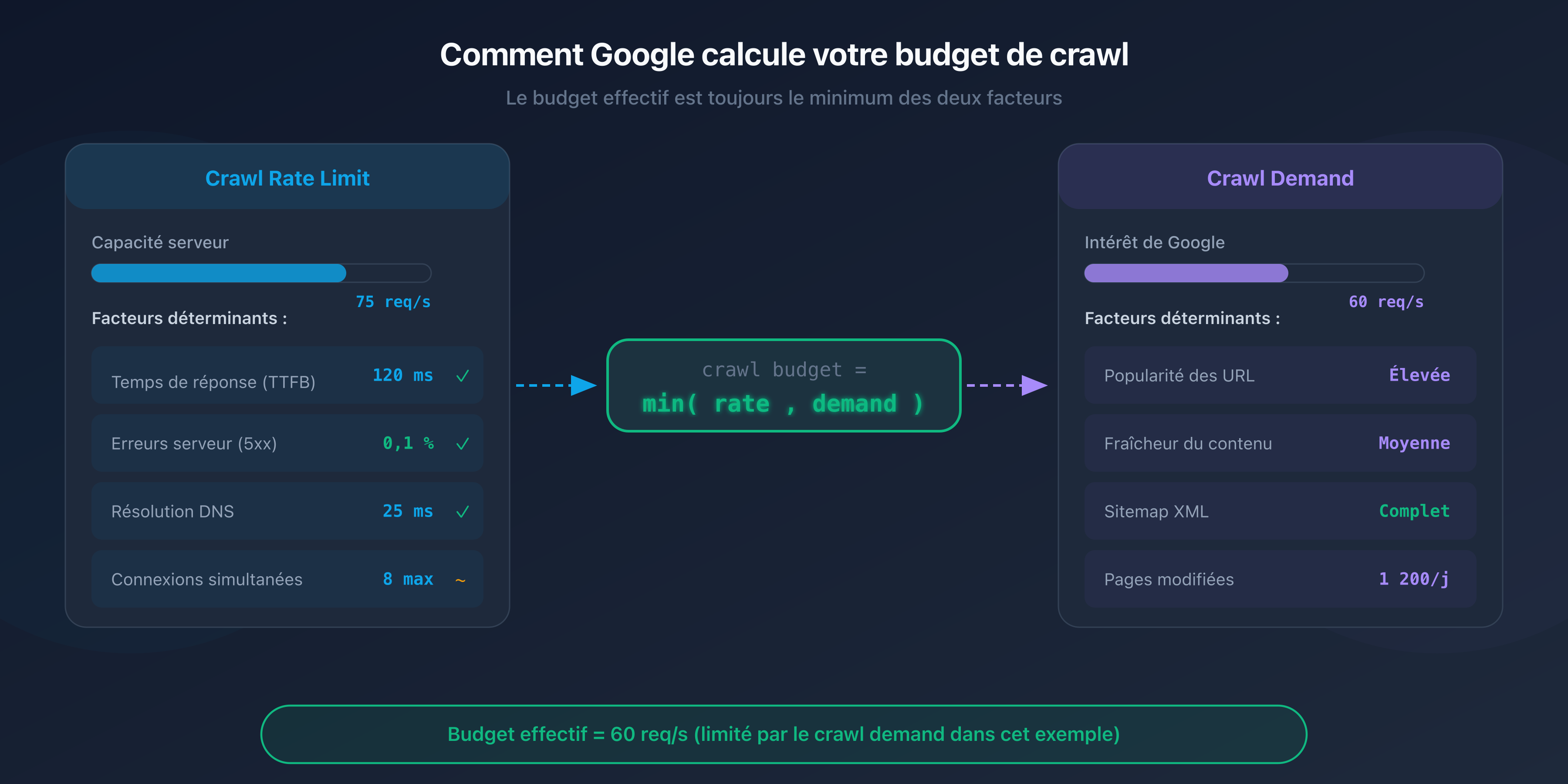
Le budget de crawl (crawl budget) est un concept défini par Google qui combine deux facteurs indépendants : le crawl rate limit et le crawl demand.
Crawl rate limit : la capacité de votre serveur
Le crawl rate limit représente le nombre maximal de requêtes simultanées que Googlebot peut envoyer à votre serveur sans le surcharger. Google ajuste cette limite automatiquement en fonction de la réactivité de votre site.
Si votre serveur répond vite (temps de réponse inférieur à 200 ms), Googlebot augmente le rythme. Si les réponses ralentissent ou que des erreurs 5xx apparaissent, il réduit la cadence pour ne pas aggraver la situation.
Crawl demand : l'intérêt de Google pour vos pages
Le crawl demand reflète la volonté de Google de crawler vos pages. Plusieurs facteurs l'influencent :
- La popularité de vos URL : les pages qui reçoivent des liens externes ou qui génèrent du trafic sont crawlées plus souvent.
- La fraîcheur : les pages qui changent fréquemment (actualités, prix, stocks) sont revisitées plus souvent que les pages statiques.
- La place dans le sitemap : les URL listées dans votre sitemap XML signalent à Google qu'elles méritent d'être explorées.
L'équation du crawl budget
Le budget de crawl effectif de votre site est le minimum entre le crawl rate limit et le crawl demand :
Crawl budget = min(crawl rate limit, crawl demand)
Concrètement : même si votre serveur peut supporter 100 requêtes par seconde, Google ne crawlera pas plus de pages qu'il n'en juge nécessaire. Et inversement, si Google veut explorer 50 000 pages mais que votre serveur ne supporte que 5 requêtes par seconde, le crawl sera lent.
Pourquoi le crawl budget est important pour le SEO ?
Impact sur l'indexation
Une page non crawlée est une page non indexée. Si Googlebot n'a pas le temps d'explorer certaines URL de votre site, elles n'apparaîtront pas dans les résultats de recherche, même si leur contenu est excellent.
Le problème est particulièrement visible sur les gros sites. Les pages profondes, accessibles après 4-5 clics depuis la page d'accueil, sont crawlées moins souvent. Si votre crawl budget est limité, ces pages peuvent mettre des semaines, voire des mois, avant d'être indexées.
Quand le crawl budget devient un problème ?
Google est explicite : le crawl budget n'est un sujet que pour les grands sites. Voici les situations où il faut s'en préoccuper :
- Sites de plus de 10 000 URL uniques : e-commerce, annuaires, portails de contenu.
- Sites avec navigation à facettes : les combinaisons de filtres (taille, couleur, prix, marque) génèrent des milliers d'URL quasi-identiques.
- Sites avec contenu dupliqué : des versions HTTP et HTTPS, www et non-www, ou des paramètres d'URL qui créent des doublons.
- Sites avec des erreurs techniques : les chaînes de redirections, les erreurs 404 et les pages soft-404 gaspillent du budget sans rien apporter.
Les sites les plus concernés
Les sites e-commerce sont les premiers touchés. Un catalogue de 50 000 produits avec 20 facettes de filtrage peut générer des millions d'URL. Sans une gestion stricte du robots.txt et des balises canonical, Googlebot passe son temps à crawler des pages de faible valeur au détriment des fiches produits stratégiques.
Les sites média avec des archives volumineuses, les forums et les sites de petites annonces sont également concernés.
Comment vérifier votre budget de crawl ?
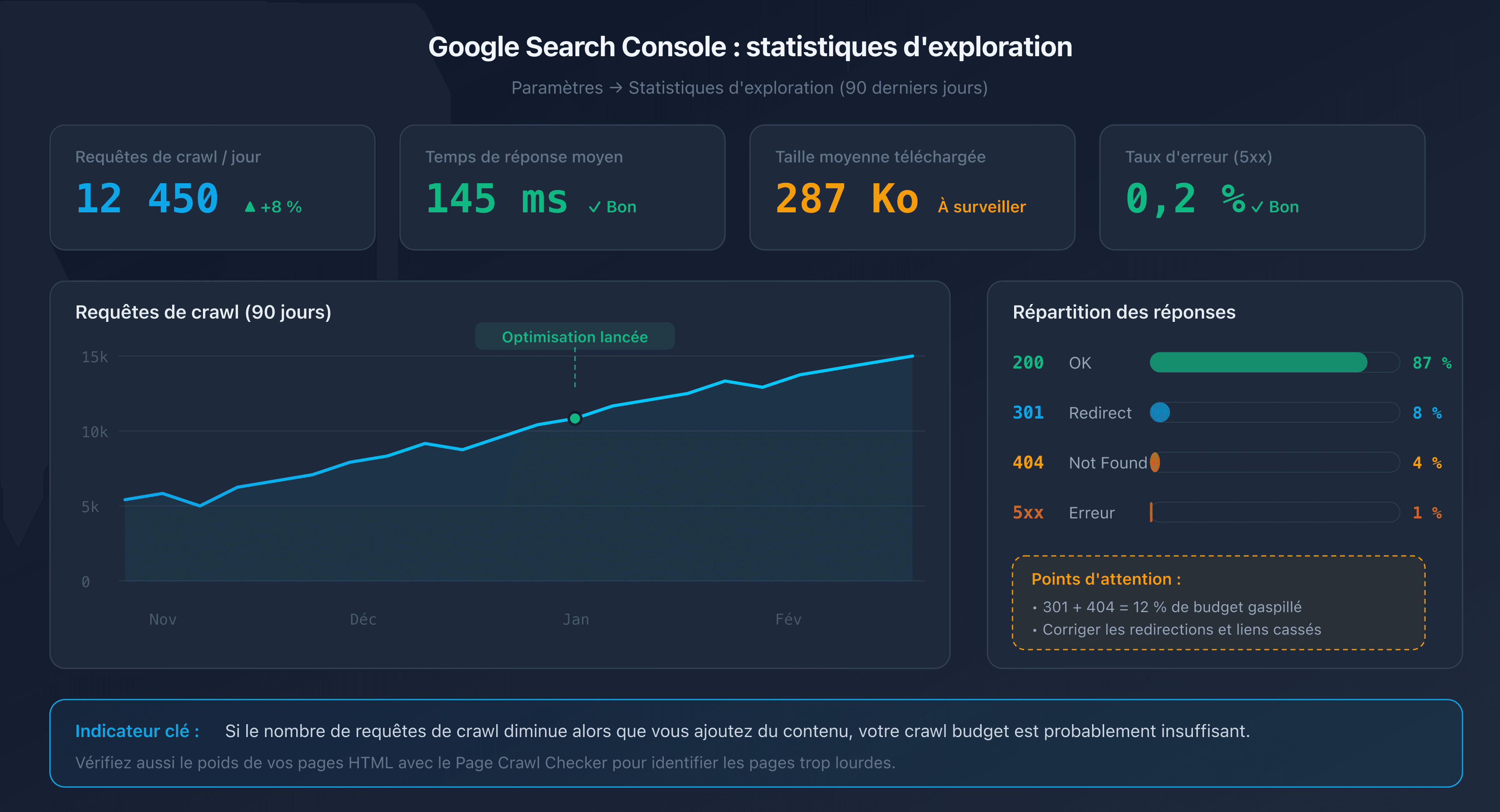
Rapport "Statistiques d'exploration" dans Google Search Console
Google Search Console fournit un rapport dédié dans la section Paramètres > Statistiques d'exploration. Ce rapport affiche sur les 90 derniers jours :
- Le nombre total de requêtes de crawl par jour.
- Le temps de réponse moyen de votre serveur.
- La répartition par type de réponse (200, 301, 404, 5xx).
- La taille moyenne des pages téléchargées.
Un bon indicateur : si le nombre de requêtes de crawl diminue alors que vous ajoutez du contenu, votre crawl budget est probablement insuffisant.
Analyse des logs serveur
Les logs de votre serveur web (Apache, Nginx) enregistrent chaque visite de Googlebot. En les analysant, vous pouvez identifier :
- Quelles pages sont crawlées le plus souvent (et lesquelles ne le sont jamais).
- Les schémas de crawl (heures, fréquence, profondeur).
- Les erreurs retournées à Googlebot.
Filtrez les requêtes dont le User-Agent contient "Googlebot" pour isoler le trafic du crawler.
URL Inspection Tool
L'outil d'inspection d'URL dans Google Search Console permet de vérifier l'état individuel d'une page : date du dernier crawl, statut d'indexation et éventuels problèmes détectés.
7 techniques pour optimiser votre budget de crawl
1. Corriger les liens cassés et les chaînes de redirections
Chaque lien cassé (404) et chaque chaîne de redirections (301 vers 301 vers 301) gaspille une requête de crawl. Googlebot suit le lien, reçoit une erreur ou une redirection, et doit recommencer. Résultat : du budget consommé pour rien.
Utilisez un crawler comme Screaming Frog ou Sitebulb pour détecter les liens cassés et les chaînes de redirections sur votre site. Corrigez les liens directement vers la destination finale.
2. Optimiser le robots.txt
Le fichier robots.txt permet de bloquer l'accès de Googlebot aux sections inutiles de votre site. Les cibles classiques :
- Pages d'administration et de back-office.
- Pages de résultats de recherche interne.
- Pages de filtrage et de tri (facettes).
- Fichiers CSS/JS qui n'ont pas besoin d'être crawlés individuellement.
# robots.txt - bloquer les pages de filtrage
User-agent: Googlebot
Disallow: /search?
Disallow: /filter/
Disallow: /sort/
Disallow: /admin/
Attention : bloquer une URL dans robots.txt empêche le crawl, mais pas la désindexation. Si une page bloquée reçoit des liens externes, Google peut quand même l'indexer (sans la crawler) en se basant sur les ancres des liens.
3. Nettoyer le sitemap XML
Votre sitemap XML ne doit contenir que les URL que vous souhaitez voir indexées. Retirez :
- Les URL renvoyant des erreurs 404 ou des redirections 301.
- Les URL bloquées par robots.txt.
- Les URL avec une balise
noindex. - Les pages de faible qualité ou les doublons.
Un sitemap propre indique à Google quelles pages méritent son attention. Si votre sitemap contient 100 000 URL dont seulement 20 000 sont réellement utiles, vous diluez le signal.
4. Éliminer le contenu dupliqué avec des canonical
Les pages dupliquées sont un gaspillage direct de crawl budget. Googlebot crawle chaque URL séparément, même si le contenu est identique.
Utilisez la balise <link rel="canonical"> pour indiquer la version préférée d'une page. Exemples courants :
- Paramètres de tracking (
?utm_source=...). - Variantes de tri et de pagination.
- Versions HTTP/HTTPS ou www/non-www
5. Réduire le poids des pages HTML
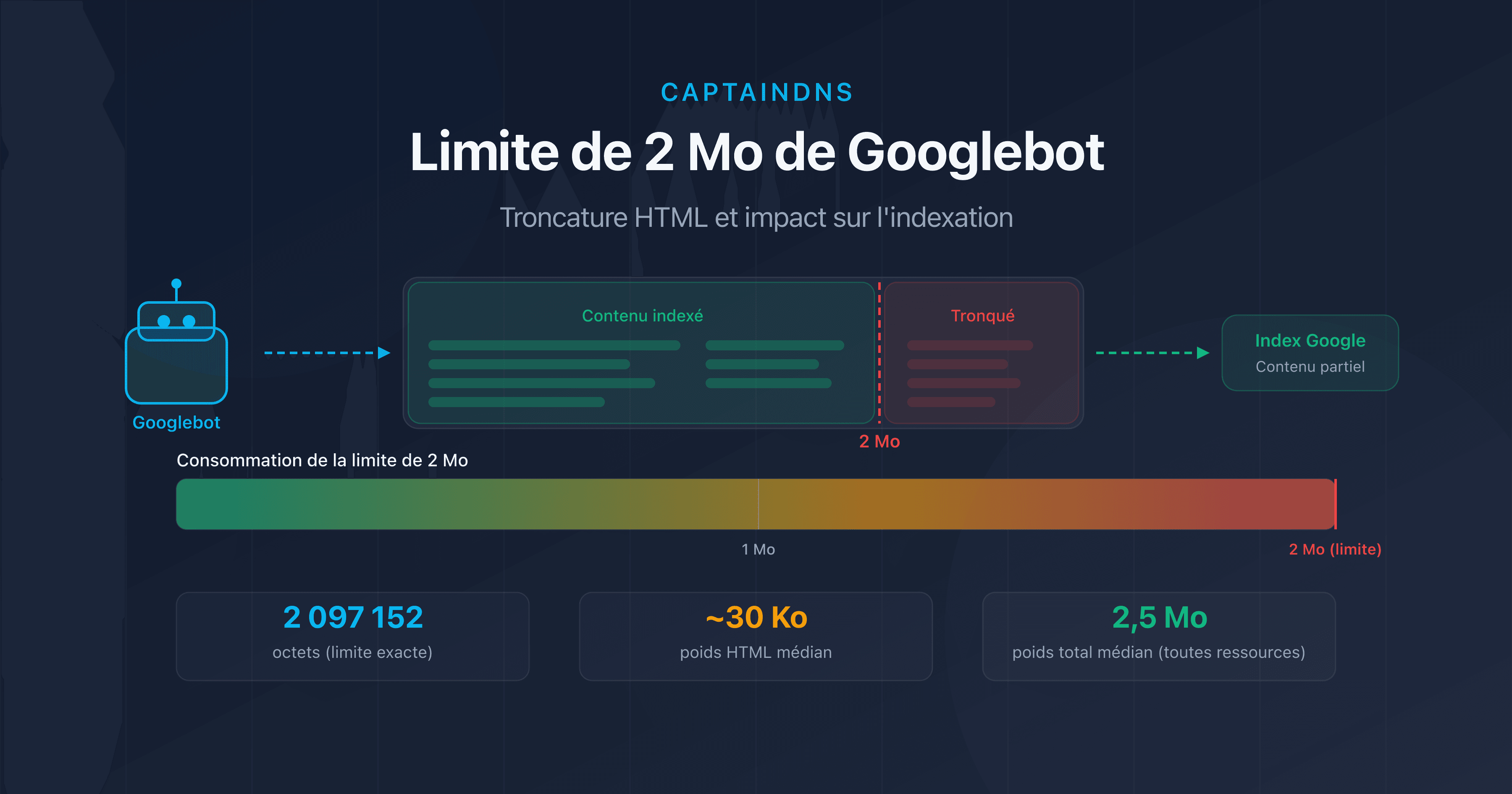
Les pages lourdes consomment plus de bande passante et de temps de téléchargement, ce qui ralentit le crawl. Au-delà de 2 Mo de HTML source, Googlebot tronque carrément le contenu.
Les actions les plus efficaces :
- Externaliser le CSS et le JavaScript inline.
- Supprimer les images en base64 et les SVG inline.
- Minifier le HTML.
- Paginer les listes longues.
6. Améliorer le temps de réponse serveur
Plus votre serveur répond vite, plus Googlebot augmente le crawl rate limit. L'objectif : un temps de réponse serveur (TTFB) inférieur à 200 ms.
Les leviers principaux :
- Cache côté serveur : Redis, Varnish ou un CDN pour les pages statiques.
- Base de données : optimiser les requêtes lentes, ajouter des index.
- Infrastructure : un hébergement dimensionné pour le trafic attendu.
7. Éviter les pièges à crawl
Les pièges à crawl (crawl traps) sont des sections de votre site qui génèrent un nombre quasi-infini d'URL. Googlebot peut s'y perdre et consommer tout le budget sans jamais atteindre vos pages importantes.
Exemples courants :
- Calendriers infinis : chaque mois génère une nouvelle URL, sans limite dans le temps.
- Facettes combinées : taille + couleur + prix + marque = des milliers d'URL.
- Sessions et identifiants dans l'URL : chaque visiteur génère des URL uniques.
- Tri et pagination : page 1 triée par prix, page 1 triée par date, page 1 triée par popularité = 3 URL pour le même contenu.
Le facteur DNS : l'impact invisible sur le crawl budget
Votre robots.txt est propre, votre sitemap est impeccable, vos pages sont légères. Pourtant, le crawl reste lent. Avez-vous vérifié vos performances DNS ? Avant chaque requête HTTP, Googlebot doit résoudre le nom de domaine de votre site. Si cette résolution est lente, chaque requête de crawl commence avec un handicap.
Résolution DNS et Googlebot
Lors de chaque session de crawl, Googlebot effectue une résolution DNS pour localiser l'adresse IP de votre serveur. Si votre serveur DNS met 200 ms à répondre au lieu de 20 ms, cela ajoute 180 ms de latence à chaque requête.
Sur une session de crawl de 1 000 pages, cette différence se traduit par 180 secondes (3 minutes) de temps perdu uniquement sur la résolution DNS. Googlebot interprète cette lenteur comme un signe de surcharge et réduit le crawl rate limit.
TTL optimal pour le crawl
Le TTL (Time To Live) de vos enregistrements DNS détermine combien de temps le résolveur DNS de Google met en cache la réponse. Un TTL trop court (moins de 300 secondes) oblige à résoudre le domaine plus souvent. Un TTL entre 3 600 et 86 400 secondes (1 heure à 24 heures) est un bon compromis entre réactivité et performance.
Comment tester vos performances DNS
Vérifiez le temps de résolution DNS de votre domaine avec des outils comme dig ou les outils DNS de CaptainDNS. Un temps de résolution inférieur à 50 ms est excellent. Au-delà de 100 ms, il y a matière à optimiser (choix du fournisseur DNS, configuration Anycast, TTL).
Plan d'action recommandé
- Analyser votre crawl budget : consultez le rapport "Statistiques d'exploration" dans Google Search Console. Notez le nombre de requêtes par jour, le temps de réponse moyen et la répartition des codes de réponse.
- Tester le poids de vos pages critiques : utilisez le Page Crawl Checker sur vos pages les plus importantes. Identifiez celles qui dépassent 500 Ko de HTML source.
- Appliquer les 7 techniques : corrigez les liens cassés, nettoyez votre sitemap, éliminez les doublons, réduisez le poids des pages et surveillez vos performances DNS. Mesurez l'impact dans Search Console après 2-4 semaines.
FAQ
Qu'est-ce que le budget de crawl en SEO ?
Le budget de crawl (crawl budget) est le nombre de pages que Googlebot explore sur votre site dans un intervalle de temps donné. Il résulte de deux facteurs : le crawl rate limit (nombre maximal de requêtes que votre serveur peut absorber) et le crawl demand (intérêt de Google pour vos URL). Les pages non crawlées ne peuvent pas être indexées.
Le crawl budget concerne-t-il les petits sites ?
Non, pour la grande majorité des sites. Google confirme que le crawl budget n'est un facteur limitant que pour les sites de plus de 10 000 URL uniques, ou pour les sites qui génèrent beaucoup d'URL via la navigation à facettes, les paramètres de tri et la pagination. Si votre site compte moins de quelques milliers de pages, Googlebot n'a aucun mal à tout explorer.
Comment vérifier son budget de crawl dans Google Search Console ?
Rendez-vous dans Google Search Console, section Paramètres, puis cliquez sur "Statistiques d'exploration". Ce rapport affiche le nombre de requêtes de crawl par jour, le temps de réponse moyen, la taille des pages téléchargées et la répartition des codes HTTP sur les 90 derniers jours. Une baisse du nombre de requêtes malgré l'ajout de contenu indique un problème de crawl budget.
Quelle est la différence entre crawl rate limit et crawl demand ?
Le crawl rate limit est la capacité technique : le nombre maximal de requêtes que Googlebot envoie à votre serveur sans le surcharger. Le crawl demand est l'intérêt de Google : combien de pages Google veut effectivement explorer en fonction de leur popularité, leur fraîcheur et leur présence dans le sitemap. Le crawl budget effectif est le minimum des deux.
Le robots.txt affecte-t-il le crawl budget ?
Oui. Les règles Disallow du robots.txt empêchent Googlebot de crawler les URL concernées, ce qui libère du budget pour les pages importantes. Attention : bloquer une URL dans robots.txt n'empêche pas son indexation si elle reçoit des liens externes. Pour désindexer une page, utilisez la balise meta noindex (qui nécessite que la page soit crawlable).
Les redirections consomment-elles du crawl budget ?
Oui. Chaque redirection (301 ou 302) consomme une requête de crawl. Googlebot suit le lien initial, reçoit la redirection, puis doit effectuer une nouvelle requête vers la destination. Les chaînes de redirections (A vers B vers C vers D) multiplient le gaspillage. Corrigez les liens pour pointer directement vers l'URL finale.
Comment le poids des pages affecte-t-il le crawl budget ?
Plus une page est lourde en HTML, plus elle consomme de bande passante et de temps de téléchargement. Googlebot ajuste le crawl rate limit en fonction du temps de réponse. Des pages légères (moins de 100 Ko de HTML) permettent de crawler plus de pages par session. Au-delà de 2 Mo de HTML source, Googlebot tronque le contenu et ne l'indexe que partiellement.
Testez vos pages maintenant : utilisez notre Page Crawl Checker pour vérifier le poids de vos pages HTML et leur conformité avec la limite de 2 Mo de Googlebot.
Guides crawl et indexation connexes
- Limite de 2 Mo de Googlebot : ce qui se passe quand vos pages sont trop lourdes : testez si vos pages dépassent le seuil de troncature.
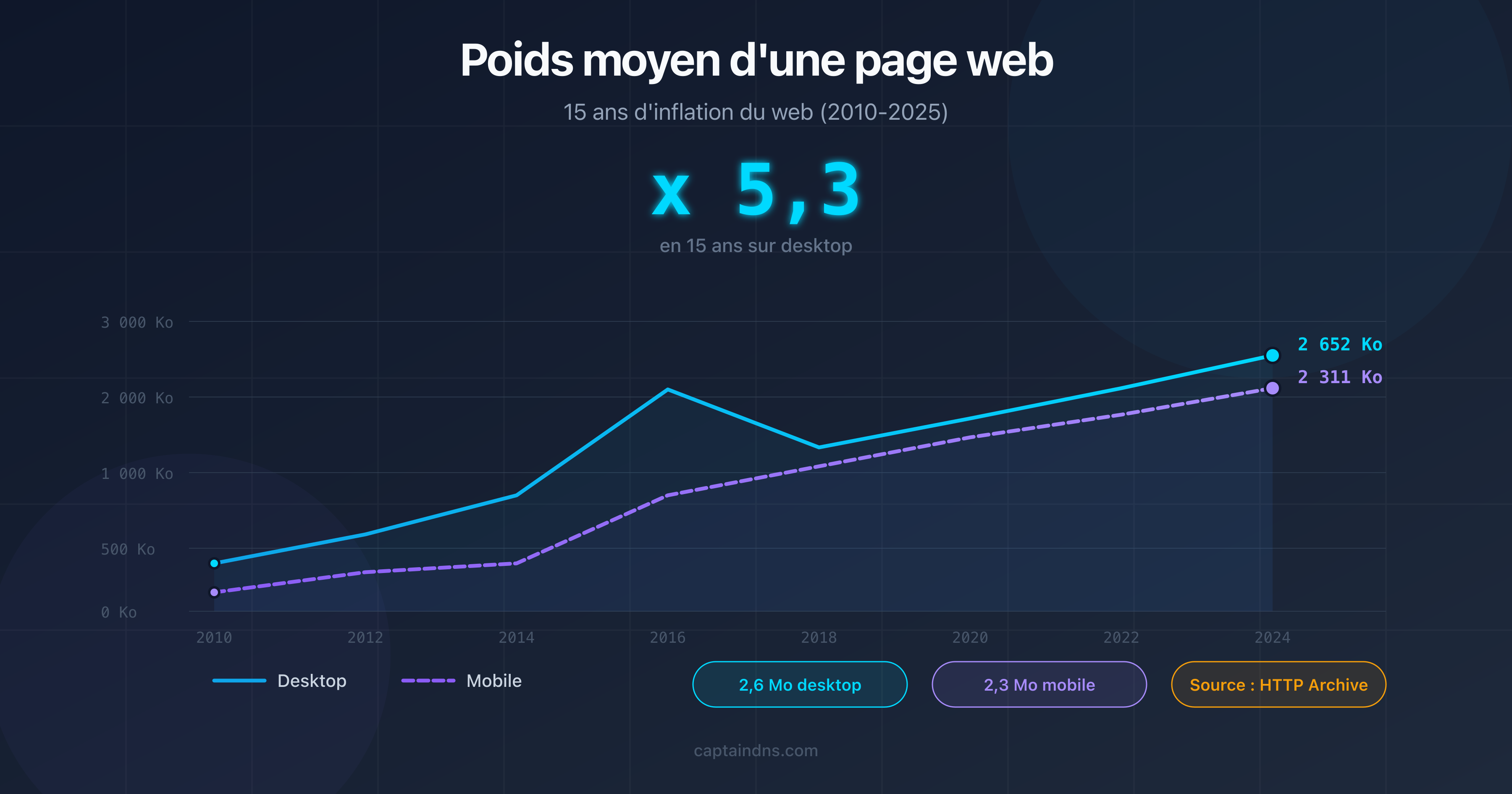
- Poids médian des pages web 2025 : 15 ans d'inflation du web
Sources
- Google Search Central. Large site management and crawl budget : documentation officielle sur le crawl budget.
- Google Developers. Googlebot overview : fonctionnement de Googlebot et limites de crawl.
- HTTP Archive. Web Almanac : statistiques sur le poids des pages web.
- web.dev. Optimize server response times (TTFB) : bonnes pratiques pour réduire le temps de réponse serveur.