Limite de 2 Mo de Googlebot : ce qui se passe quand vos pages sont trop lourdes
Par CaptainDNS
Publié le 10 février 2026
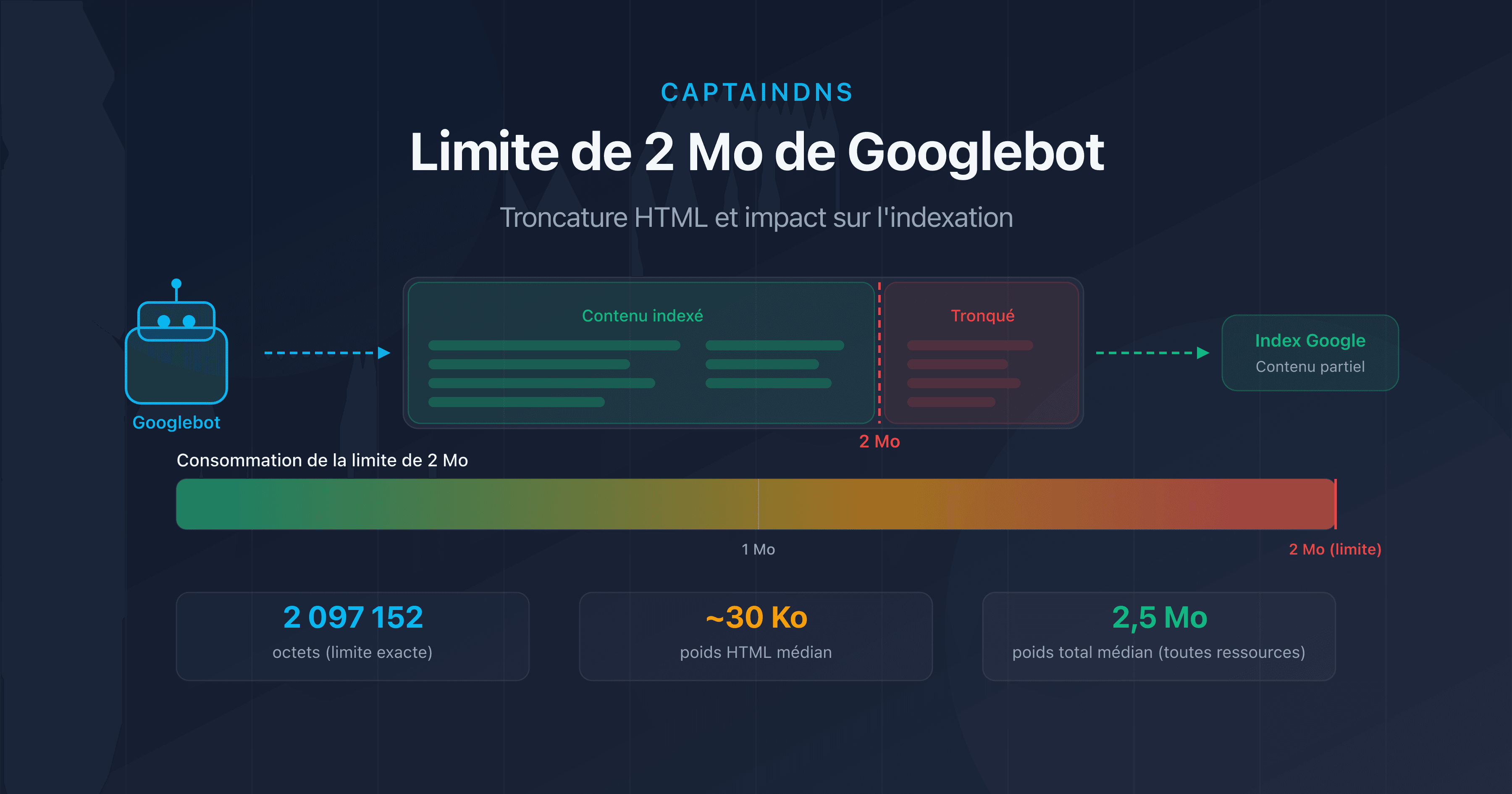
- Googlebot crawle uniquement les 2 premiers Mo (2 097 152 octets) du code HTML d'une page.
- Au-delà de cette limite, le contenu est tronqué : liens internes, données structurées et texte en bas de page disparaissent de l'index.
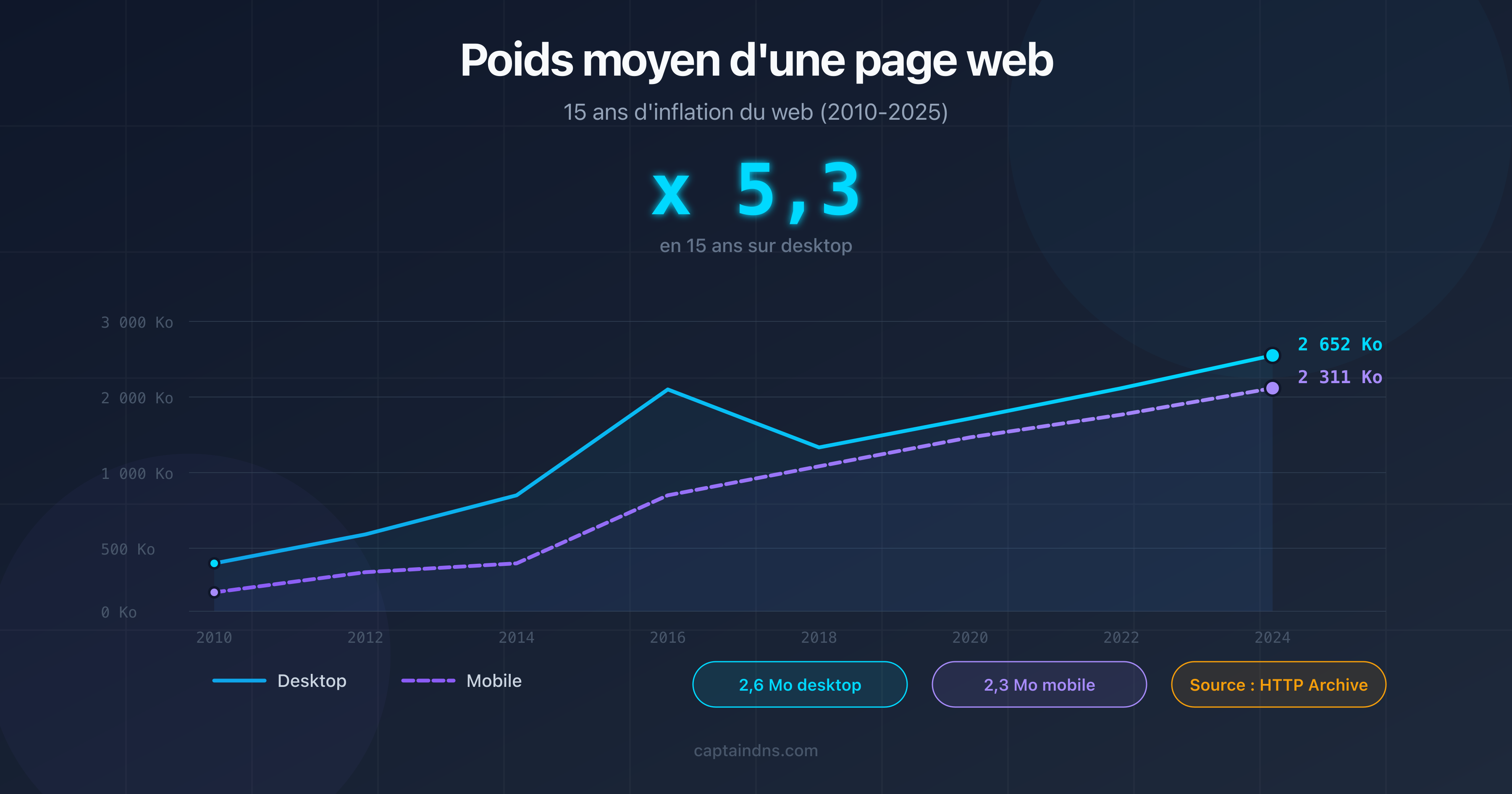
- Le poids médian d'une page web dépasse 2,5 Mo de ressources totales en 2026, mais seul le HTML source compte pour cette limite.
- Testez vos pages avec notre Page Crawl Checker pour vérifier si elles sont à risque.
Votre page fait 2,1 Mo de HTML ? Google n'en a indexé que 95 %. Le reste n'existe tout simplement pas pour le moteur de recherche.
Début février 2026, Google a mis à jour sa documentation technique pour rappeler ce point souvent méconnu : Googlebot ne crawle que les 2 premiers mégaoctets du code source HTML d'une page. Tout ce qui dépasse est ignoré lors de l'indexation.
Cette contrainte existe depuis plusieurs années, mais son importance croît à mesure que les pages web deviennent plus lourdes. Frameworks JavaScript, images inline en base64, Single Page Applications rendues côté serveur : de plus en plus de pages flirtent avec cette frontière invisible.
Dans cet article, nous détaillons le fonctionnement exact de cette limite, les situations à risque et les actions concrètes pour s'en prémunir. Que vous soyez référenceur SEO, développeur front-end ou responsable technique, vous trouverez ici de quoi auditer et optimiser vos pages.
Qu'est-ce que la limite de 2 Mo de Googlebot ?
La documentation officielle de Google est explicite : "Googlebot crawls the first 2 MB of a supported file type" (Googlebot crawle les 2 premiers Mo d'un type de fichier supporté). Cela représente exactement 2 097 152 octets de données non compressées.
Plusieurs précisions importantes :
- C'est le HTML source qui compte, pas les ressources totales de la page (images, CSS, JavaScript externes). Un fichier CSS de 500 Ko chargé via
<link>n'entre pas dans le calcul. - La limite s'applique au contenu non compressé. Même si votre serveur utilise gzip ou Brotli, c'est la taille décompressée que Google mesure.
- Chaque ressource est évaluée individuellement. Un fichier JavaScript externe de 3 Mo sera lui aussi tronqué à 2 Mo, indépendamment de la page HTML qui le charge.
- La limite est identique pour Googlebot Desktop et Googlebot Mobile. Le passage au mobile-first indexing n'a pas modifié ce seuil.

Troncature HTML : quel impact sur le SEO ?
Lorsque Googlebot atteint la limite de 2 Mo, il cesse de télécharger le fichier HTML. La partie déjà récupérée est envoyée au moteur d'indexation, mais tout ce qui se trouve après la coupure est invisible pour Google.
En pratique, les éléments situés en fin de document HTML sont les plus exposés :
- Les données structurées (JSON-LD en bas de page) : les schémas FAQPage, HowTo ou Product placés avant la balise
</body>risquent d'être coupés. - Les liens internes dans le footer ou la navigation secondaire : ils ne seront pas découverts par le crawler.
- Le contenu textuel des sections inférieures : FAQ, mentions légales, conditions générales.
- Les scripts JavaScript inline placés en fin de page : si votre framework injecte du contenu dynamique via un script en bas de page, il ne sera jamais exécuté par le moteur de rendu de Google.
Le résultat est insidieux. La page apparaît dans l'index, mais avec un contenu incomplet. Les rich snippets ne s'affichent pas, le maillage interne est partiellement rompu et le contenu rédactionnel est amputé.
Qui est concerné ?
Vos pages sont-elles en danger ? La majorité des pages web n'atteignent pas 2 Mo de HTML source. Selon HTTP Archive, le poids médian du HTML seul se situe autour de 30 Ko en 2025. Mais certains cas de figure font exploser cette taille.
Pages e-commerce avec méga-catalogues
Les pages de catégorie affichant des centaines de produits avec des descriptions inline, des attributs techniques et des avis clients peuvent facilement dépasser 1 Mo de HTML pur. Ajoutez-y des données structurées Product pour chaque article et la barre des 2 Mo est vite franchie.
Single Page Applications (SPA) avec rendu serveur
Les frameworks comme Next.js, Nuxt ou SvelteKit injectent un payload JSON volumineux dans une balise <script> pour l'hydratation côté client. Ce __NEXT_DATA__ ou équivalent peut représenter plusieurs centaines de Ko. Sur les pages riches en données, il dépasse souvent 1 Mo à lui seul.
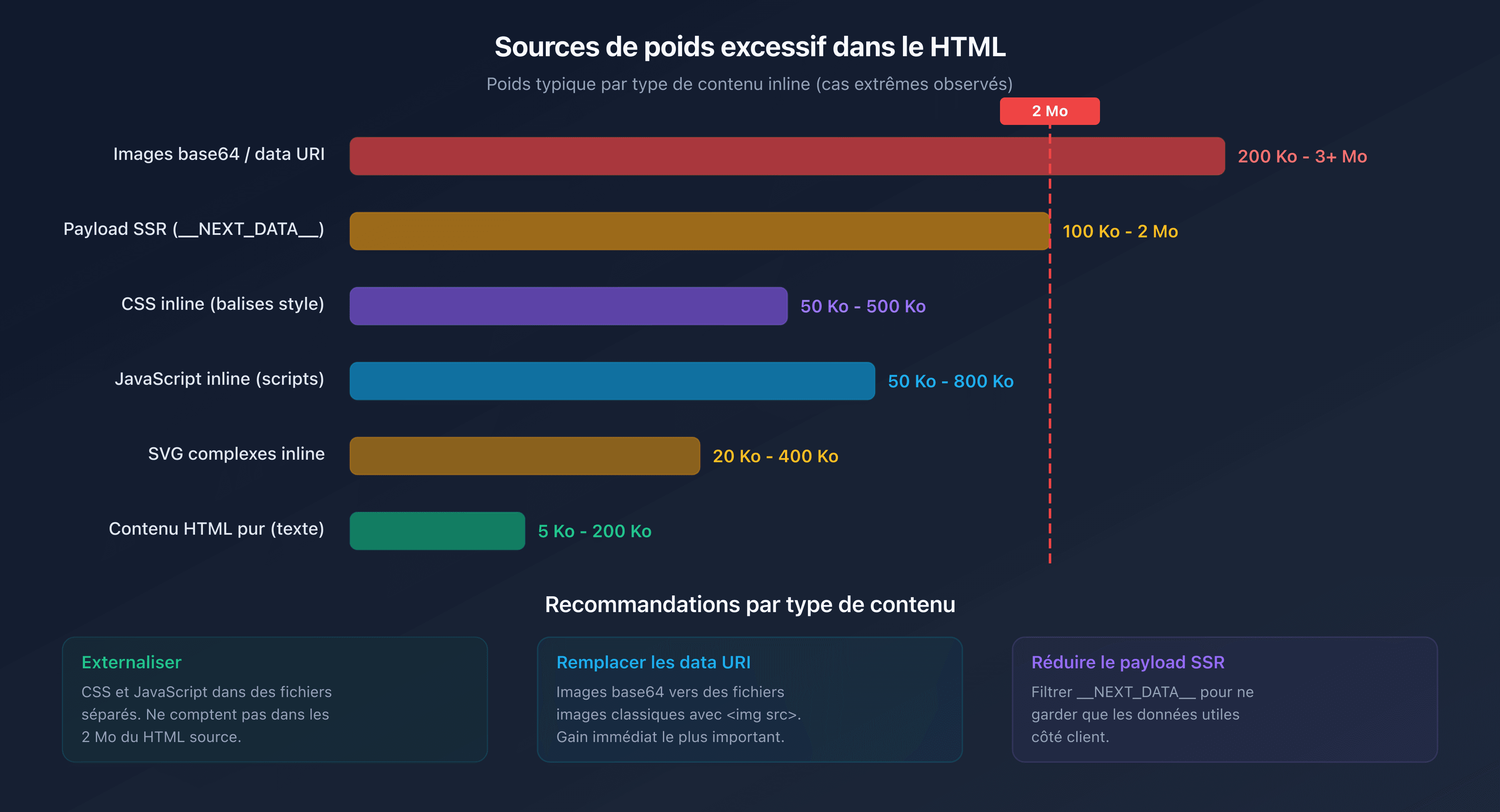
Images et SVG inline
Les images encodées en base64 ou les SVG complexes insérés directement dans le HTML gonflent considérablement le poids du document. Un seul SVG détaillé peut peser 200 Ko. Trois ou quatre suffisent à consommer une part significative du budget de 2 Mo.
JavaScript et CSS inline
Les pages qui embarquent du CSS critique ou du JavaScript directement dans des balises <style> et <script> au lieu de les externaliser ajoutent du poids inutile au document HTML.
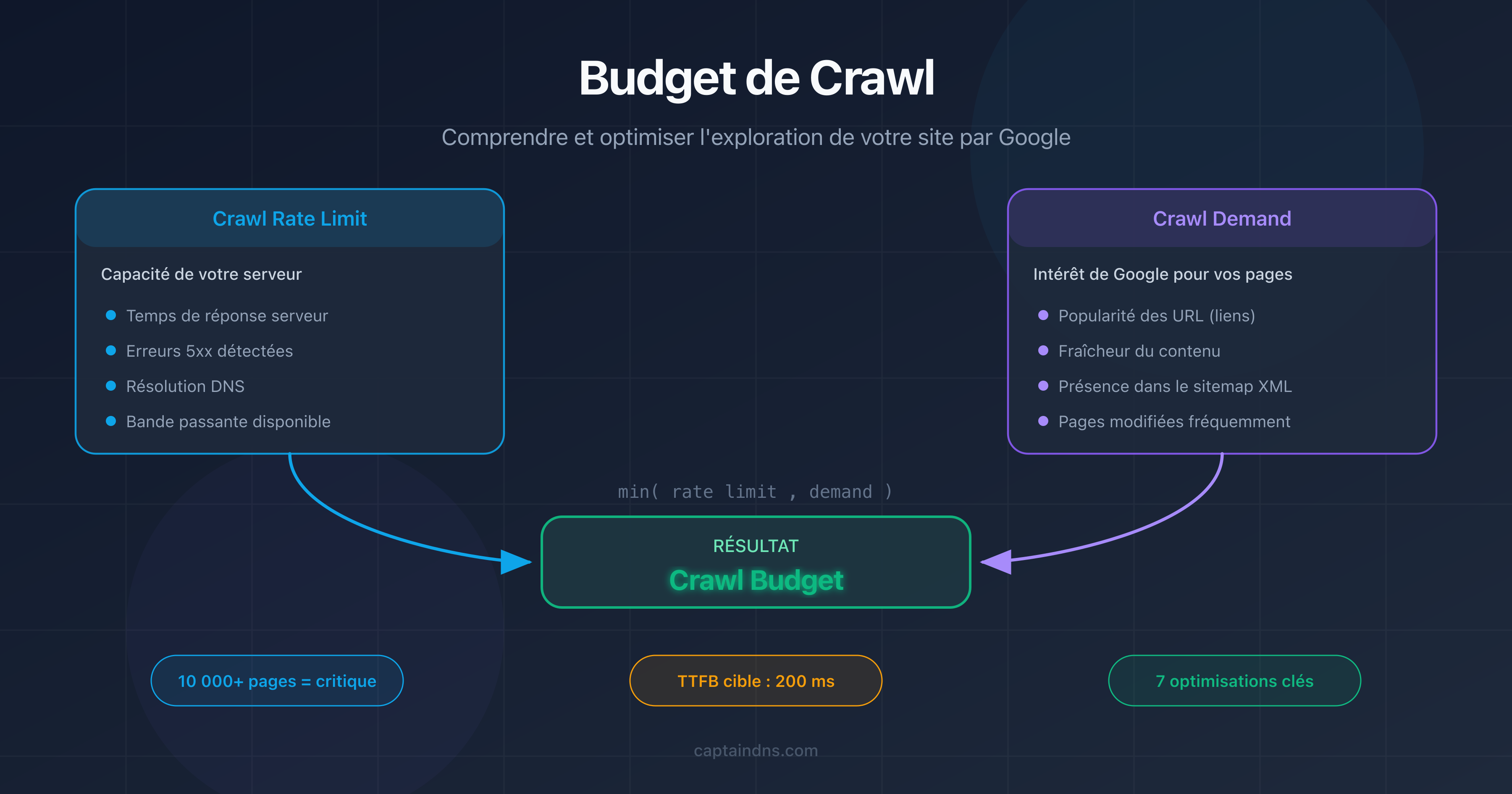
Budget de crawl et poids de page
Le budget de crawl (crawl budget) désigne le nombre de pages que Googlebot peut crawler sur votre site dans un intervalle de temps donné. Il dépend de deux facteurs : le taux de crawl (crawl rate limit) et la demande de crawl (crawl demand).
Le poids des pages affecte directement le taux de crawl. Plus une page est lourde, plus elle consomme de bande passante et de temps de téléchargement. Prenons un site de 100 000 pages. La différence entre des pages de 50 Ko et des pages de 500 Ko de HTML se traduit par un facteur 10 sur la consommation de ressources.
Concrètement :
- Pages légères (<100 Ko HTML) : Googlebot peut crawler des milliers de pages par session.
- Pages moyennes (100 Ko-500 Ko) : le crawl ralentit sensiblement.
- Pages lourdes (500 Ko-2 Mo) : le budget de crawl est consommé rapidement, les pages profondes sont crawlées moins fréquemment.
- Pages tronquées (>2 Mo) : en plus de gaspiller le budget, le contenu est incomplet dans l'index.
Pour les grands sites, l'optimisation du poids HTML n'est pas un luxe. C'est une nécessité pour garantir que toutes les pages importantes soient crawlées et indexées correctement.
Comment tester le poids de vos pages ?
Avec les DevTools de Chrome
Ouvrez les DevTools (F12), allez dans l'onglet Network, rechargez la page et filtrez par Doc. La colonne Size indique le poids transféré (compressé) et la colonne Content le poids décompressé. C'est cette dernière valeur qui compte pour la limite Googlebot.
Avec le Page Crawl Checker de CaptainDNS
Notre Page Crawl Checker simule le comportement de Googlebot et affiche immédiatement :
- Le poids du HTML source (compressé et décompressé)
- Le pourcentage de la limite de 2 Mo consommé
- Les en-têtes HTTP (Content-Type, Content-Encoding, Cache-Control)
- Un diagnostic complet avec des recommandations d'optimisation
HTML source vs ressources totales
Une confusion fréquente consiste à regarder le poids total de la page (HTML + CSS + JS + images) au lieu du HTML source seul. Le chiffre de 2,5 Mo souvent cité comme poids médian d'une page web inclut toutes les ressources. Le HTML seul représente généralement entre 1 % et 5 % de ce total.
Comment réduire le poids de vos pages HTML ?
Par où commencer ? Si vos pages approchent de la limite ou si vous souhaitez optimiser votre crawl budget, voici les actions les plus efficaces.
Externaliser CSS et JavaScript
Déplacez tout le CSS et le JavaScript inline vers des fichiers externes. Ces fichiers seront chargés séparément et ne comptent pas dans les 2 Mo du document HTML.
<!-- Avant : CSS inline (pèse dans le HTML) -->
<style>
.product-card \{ ... 500 lignes de CSS ... \}
</style>
<!-- Après : CSS externalisé (ne pèse pas dans le HTML) -->
<link rel="stylesheet" href="/css/products.css">
Supprimer les images inline
Remplacez les images en base64 et les data URI par des fichiers images classiques référencés via <img src="...">.
Minifier le HTML
Supprimez les espaces inutiles, les commentaires HTML et les attributs redondants. Des outils comme html-minifier ou les plugins de build (Webpack, Vite) automatisent cette tâche.
Activer la compression serveur
Configurez gzip ou Brotli sur votre serveur web. Cela réduit le volume transféré (et donc le temps de crawl), même si la limite de 2 Mo s'applique au contenu décompressé.
Paginer les listes longues
Pour les pages de catégorie e-commerce, implémentez une pagination propre avec des balises <link rel="next"> et <link rel="prev"> au lieu d'afficher tous les produits sur une seule page.
Réduire le payload d'hydratation
Si vous utilisez un framework SSR (Next.js, Nuxt), examinez le contenu de __NEXT_DATA__ ou équivalent. Souvent, des données inutiles côté client y sont sérialisées. Filtrez les props transmises pour ne garder que le strict nécessaire.
Plan d'action recommandé
- Tester vos pages critiques : utilisez le Page Crawl Checker sur vos 10-20 pages les plus importantes (accueil, catégories, produits phares, landing pages).
- Identifier les pages à risque : toute page dont le HTML source dépasse 500 Ko mérite un examen. Au-delà de 1 Mo, l'optimisation est urgente.
- Optimiser : externalisez le CSS/JS inline, supprimez les images base64, minifiez le HTML et activez la compression serveur.
FAQ
Quel est le poids moyen d'une page web en 2026 ?
Selon HTTP Archive, le poids médian total d'une page web (HTML + CSS + JS + images) atteint environ 2,5 Mo sur desktop et 2,2 Mo sur mobile en 2026. Le HTML source seul pèse en médiane autour de 30 Ko. La limite de 2 Mo de Googlebot concerne uniquement le HTML source, pas les ressources totales.
Que se passe-t-il si une page dépasse 2 Mo de HTML ?
Googlebot arrête le téléchargement après 2 Mo (2 097 152 octets) de HTML non compressé. Seul le contenu déjà téléchargé est envoyé à l'indexation. Le reste (liens internes, données structurées, texte en fin de page) est ignoré. La page apparaît dans l'index, mais avec un contenu incomplet.
Comment connaître le poids HTML d'une page web ?
Ouvrez les DevTools de Chrome (F12), onglet Network, filtrez par "Doc" et regardez la colonne "Content" (taille décompressée). Vous pouvez aussi utiliser notre Page Crawl Checker qui affiche directement le poids HTML source et le pourcentage de la limite de 2 Mo consommé.
La limite de 2 Mo s'applique-t-elle aux données compressées ?
Non. La limite de 2 Mo s'applique au contenu décompressé. Même si votre serveur utilise gzip ou Brotli pour la transmission, c'est la taille du HTML une fois décompressé qui est prise en compte par Googlebot. La compression reste utile pour accélérer le transfert, mais ne permet pas de contourner la limite.
Comment réduire le poids d'une page HTML ?
Les actions les plus efficaces : externaliser le CSS et le JavaScript (fichiers séparés au lieu de balises inline), supprimer les images en base64, minifier le HTML, paginer les listes longues et réduire le payload d'hydratation des frameworks SSR (Next.js, Nuxt). Activez aussi la compression serveur (gzip ou Brotli).
Qu'est-ce que le budget de crawl ?
Le budget de crawl (crawl budget) est le nombre de pages que Googlebot peut crawler sur votre site dans un intervalle de temps donné. Il dépend du taux de crawl (bande passante que Google accorde à votre site) et de la demande de crawl (pages que Google souhaite actualiser). Les pages lourdes consomment plus de budget, ce qui réduit la fréquence de crawl des autres pages.
Googlebot Mobile et Desktop ont-ils la même limite de 2 Mo ?
Oui. La limite de 2 Mo est identique pour Googlebot Desktop et Googlebot Mobile (Googlebot Smartphone). Le passage au mobile-first indexing n'a pas modifié ce seuil. Les deux variantes du crawler appliquent la même règle de troncature.
Testez vos pages maintenant : utilisez notre Page Crawl Checker pour vérifier instantanément si vos pages respectent la limite de 2 Mo de Googlebot.
Guides crawl et indexation connexes
- Budget de crawl : comprendre et optimiser l'exploration de votre site par Google
- Poids médian des pages web 2025 : 15 ans d'inflation du web
Sources
- Google Developers. Googlebot overview : documentation officielle mentionnant la limite de 2 Mo.
- HTTP Archive. Web Almanac : statistiques sur le poids des pages web.
- web.dev. Reduce the scope and complexity of style calculations : bonnes pratiques d'optimisation.
- Google Search Central. Crawl budget management : gestion du budget de crawl pour les grands sites.