Googlebots 2-MB-Limit: Was passiert, wenn deine Seiten zu schwer sind
Von CaptainDNS
Veröffentlicht am 10. Februar 2026
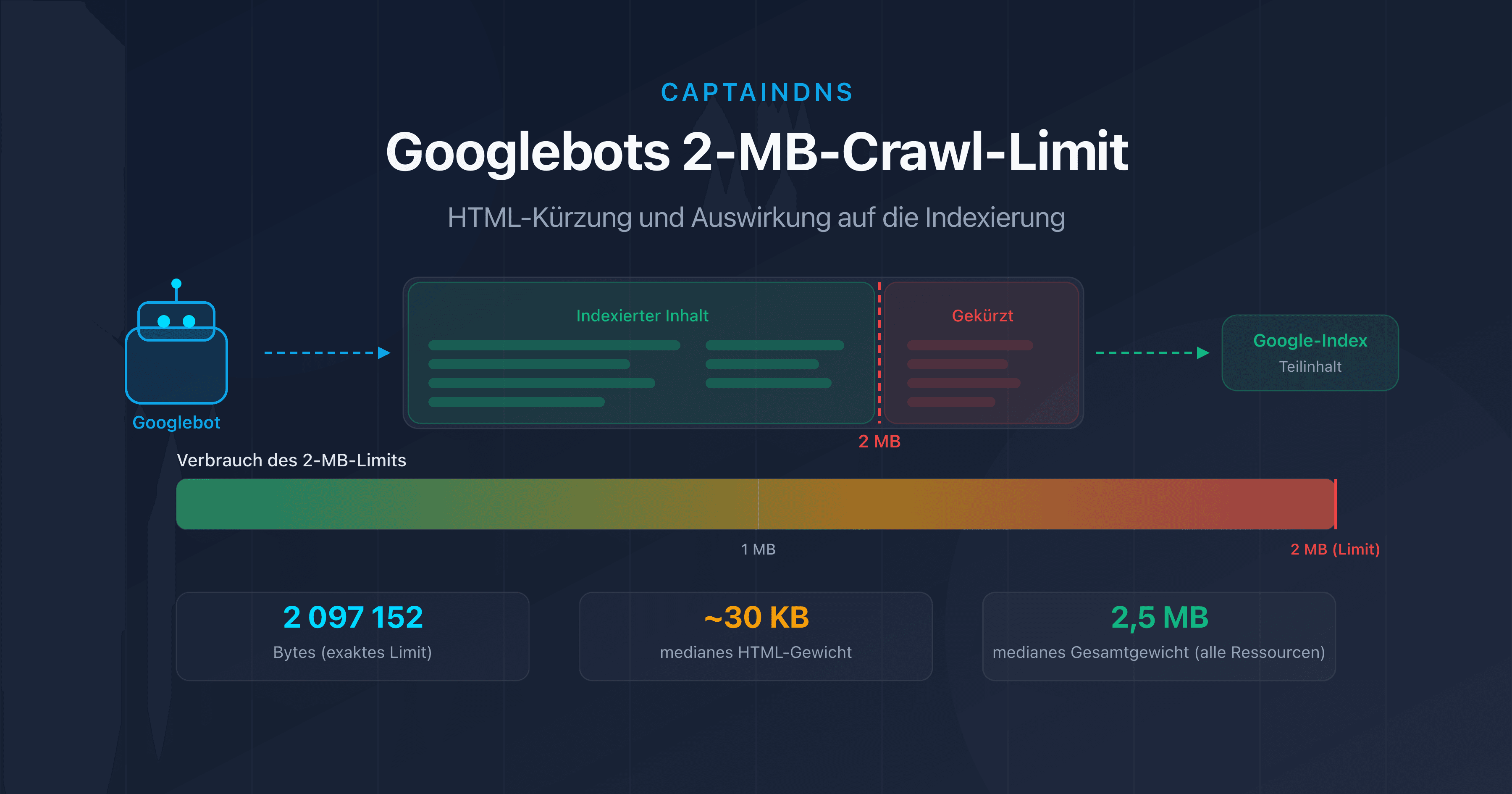
- Googlebot crawlt nur die ersten 2 MB (2.097.152 Bytes) des HTML-Quellcodes einer Seite.
- Über dieses Limit hinaus wird der Inhalt abgeschnitten: Interne Links, strukturierte Daten und Text am Seitenende verschwinden aus dem Index.
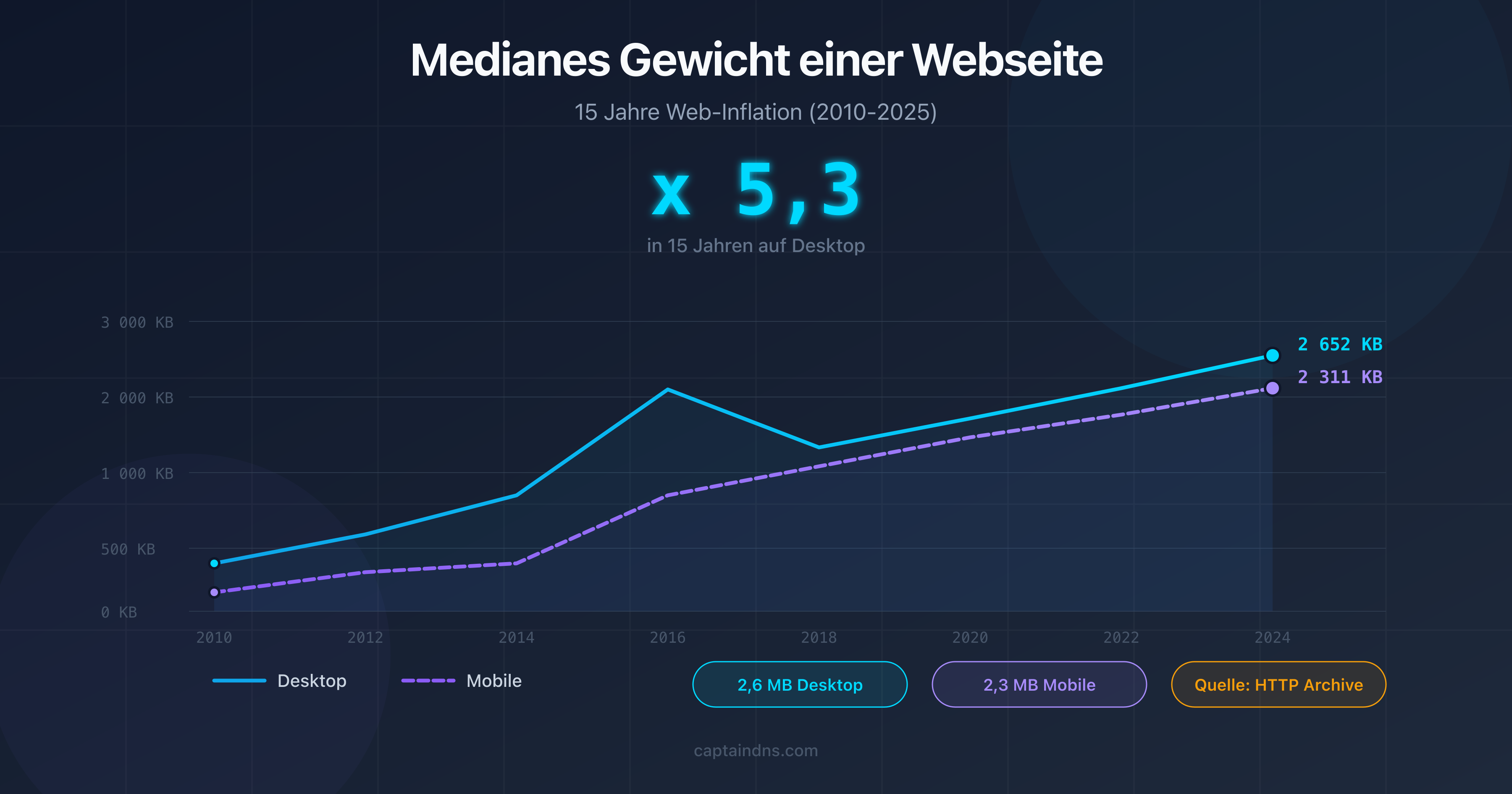
- Das mediane Gewicht einer Webseite übersteigt 2,5 MB an Gesamtressourcen im Jahr 2026, aber nur der HTML-Quellcode zählt für dieses Limit.
- Teste deine Seiten mit unserem Page Crawl Checker, um zu prüfen, ob sie gefährdet sind.
Deine Seite hat 2,1 MB HTML? Google hat nur 95 % davon indexiert. Der Rest existiert für die Suchmaschine schlicht nicht.
Anfang Februar 2026 hat Google seine technische Dokumentation aktualisiert und einen oft übersehenen Punkt hervorgehoben: Googlebot crawlt nur die ersten 2 Megabytes des HTML-Quellcodes einer Seite. Alles, was über dieses Limit hinausgeht, wird bei der Indexierung ignoriert.
Diese Einschränkung existiert seit mehreren Jahren, gewinnt aber zunehmend an Bedeutung, da Webseiten immer schwerer werden. JavaScript-Frameworks, Inline-Base64-Bilder, serverseitig gerenderte Single Page Applications: Immer mehr Seiten nähern sich dieser unsichtbaren Grenze.
In diesem Artikel erklären wir die genaue Funktionsweise dieses Limits, die Risikosituationen und die konkreten Maßnahmen zum Schutz. Ob du SEO-Spezialist, Frontend-Entwickler oder technischer Verantwortlicher bist, hier findest du alles, um deine Seiten zu prüfen und zu optimieren.
Was ist das 2-MB-Limit von Googlebot?
Die offizielle Google-Dokumentation ist eindeutig: "Googlebot crawls the first 2 MB of a supported file type" (Googlebot crawlt die ersten 2 MB eines unterstützten Dateityps). Das entspricht genau 2.097.152 Bytes unkomprimierter Daten.
Einige wichtige Details:
- Es zählt der HTML-Quellcode, nicht die Gesamtressourcen der Seite (Bilder, CSS, externes JavaScript). Eine CSS-Datei von 500 KB, die über
<link>geladen wird, fließt nicht in die Berechnung ein. - Das Limit gilt für den unkomprimierten Inhalt. Selbst wenn dein Server gzip oder Brotli verwendet, misst Google die dekomprimierte Größe.
- Jede Ressource wird einzeln bewertet. Eine externe JavaScript-Datei von 3 MB wird ebenfalls bei 2 MB abgeschnitten, unabhängig von der HTML-Seite, die sie lädt.
- Das Limit ist identisch für Googlebot Desktop und Googlebot Mobile. Der Wechsel zum Mobile-First-Indexing hat diesen Schwellenwert nicht verändert.

HTML-Trunkierung: Welche Auswirkungen auf SEO?
Wenn Googlebot das 2-MB-Limit erreicht, stoppt er den Download der HTML-Datei. Der bereits abgerufene Teil wird an die Indexierungs-Engine weitergeleitet, aber alles nach dem Abschnitt ist für Google unsichtbar.
In der Praxis sind die Elemente am Ende des HTML-Dokuments am stärksten betroffen:
- Strukturierte Daten (JSON-LD am Seitenende): FAQPage-, HowTo- oder Product-Schemas, die vor dem
</body>-Tag platziert sind, können abgeschnitten werden. - Interne Links im Footer oder in der sekundären Navigation: Sie werden vom Crawler nicht entdeckt.
- Textinhalte der unteren Abschnitte: FAQ, rechtliche Hinweise, AGB.
- Inline-JavaScript-Scripte am Seitenende: Wenn dein Framework dynamischen Inhalt über ein Script am Seitenende injiziert, wird es von Googles Rendering-Engine nie ausgeführt.
Das Ergebnis ist tückisch. Die Seite erscheint im Index, aber mit unvollständigem Inhalt. Rich Snippets werden nicht angezeigt, die interne Verlinkung ist teilweise unterbrochen und der redaktionelle Inhalt ist gekürzt.
Wer ist betroffen?
Sind deine Seiten gefährdet? Die Mehrheit der Webseiten erreicht keine 2 MB HTML-Quellcode. Laut HTTP Archive liegt das mediane HTML-Gewicht bei etwa 30 KB im Jahr 2025. Bestimmte Szenarien lassen diese Größe jedoch explodieren.
E-Commerce-Seiten mit Mega-Katalogen
Kategorieseiten, die Hunderte von Produkten mit Inline-Beschreibungen, technischen Attributen und Kundenbewertungen anzeigen, können leicht 1 MB reinen HTML-Code überschreiten. Kommen noch Product-Schema-Daten für jeden Artikel hinzu, ist die 2-MB-Grenze schnell erreicht.
Single Page Applications (SPA) mit Server-Rendering
Frameworks wie Next.js, Nuxt oder SvelteKit injizieren einen umfangreichen JSON-Payload in ein <script>-Tag für die clientseitige Hydratation. Dieses __NEXT_DATA__ oder Äquivalent kann mehrere Hundert KB umfassen. Bei datenreichen Seiten überschreitet es oft allein 1 MB.
Inline-Bilder und SVG
Base64-kodierte Bilder oder komplexe SVGs, die direkt in den HTML-Code eingefügt werden, erhöhen das Dokumentgewicht erheblich. Ein einzelnes detailliertes SVG kann 200 KB wiegen. Drei oder vier davon verbrauchen bereits einen erheblichen Teil des 2-MB-Budgets.
Inline-JavaScript und CSS
Seiten, die kritisches CSS oder JavaScript direkt in <style>- und <script>-Tags einbetten, anstatt sie zu externalisieren, fügen dem HTML-Dokument unnötiges Gewicht hinzu.

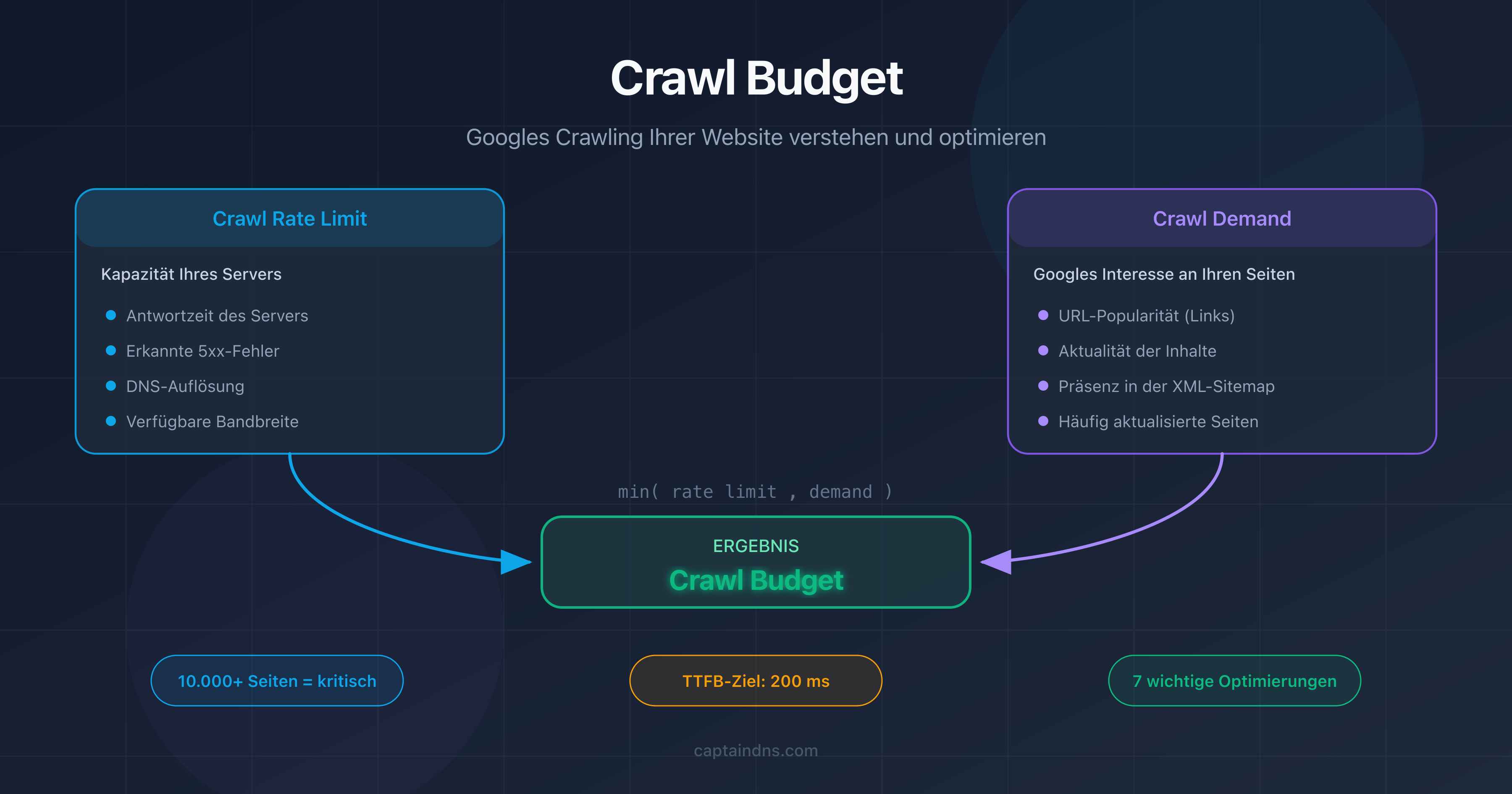
Crawl-Budget und Seitengewicht
Das Crawl-Budget (Crawl Budget) bezeichnet die Anzahl der Seiten, die Googlebot auf deiner Website in einem bestimmten Zeitraum crawlen kann. Es hängt von zwei Faktoren ab: dem Crawl-Rate-Limit (Crawl Rate Limit) und der Crawl-Nachfrage (Crawl Demand).
Das Seitengewicht beeinflusst direkt das Crawl-Rate-Limit. Je schwerer eine Seite, desto mehr Bandbreite und Downloadzeit verbraucht sie. Nehmen wir eine Website mit 100.000 Seiten. Der Unterschied zwischen 50 KB und 500 KB HTML pro Seite bedeutet einen Faktor 10 beim Ressourcenverbrauch.
Konkret:
- Leichte Seiten (<100 KB HTML): Googlebot kann Tausende Seiten pro Sitzung crawlen.
- Mittlere Seiten (100 KB-500 KB): Das Crawlen verlangsamt sich spürbar.
- Schwere Seiten (500 KB-2 MB): Das Crawl-Budget wird schnell verbraucht, tiefere Seiten werden seltener gecrawlt.
- Abgeschnittene Seiten (>2 MB): Neben der Budgetverschwendung ist der Inhalt im Index unvollständig.
Für große Websites ist die Optimierung des HTML-Gewichts kein Luxus. Es ist eine Notwendigkeit, um sicherzustellen, dass alle wichtigen Seiten korrekt gecrawlt und indexiert werden.
Wie testest du das Gewicht deiner Seiten?
Mit den Chrome DevTools
Öffne die DevTools (F12), gehe zum Tab Network, lade die Seite neu und filtere nach Doc. Die Spalte Size zeigt das übertragene Gewicht (komprimiert) und die Spalte Content das dekomprimierte Gewicht. Letzterer Wert zählt für das Googlebot-Limit.
Mit dem Page Crawl Checker von CaptainDNS
Unser Page Crawl Checker simuliert das Verhalten von Googlebot und zeigt sofort:
- Das Gewicht des HTML-Quellcodes (komprimiert und dekomprimiert)
- Den Prozentsatz des verbrauchten 2-MB-Limits
- Die HTTP-Header (Content-Type, Content-Encoding, Cache-Control)
- Eine vollständige Diagnose mit Optimierungsempfehlungen
HTML-Quellcode vs. Gesamtressourcen
Ein häufiger Fehler ist es, das Gesamtgewicht der Seite (HTML + CSS + JS + Bilder) statt nur den HTML-Quellcode zu betrachten. Die oft genannten 2,5 MB als medianes Seitengewicht umfassen alle Ressourcen. Der HTML-Code allein macht in der Regel zwischen 1 % und 5 % dieses Gesamtwerts aus.
Wie reduzierst du das HTML-Gewicht deiner Seiten?
Wo fängst du an? Wenn deine Seiten sich dem Limit nähern oder du dein Crawl-Budget optimieren möchtest, sind hier die wirksamsten Maßnahmen.
CSS und JavaScript externalisieren
Verschiebe sämtliches Inline-CSS und -JavaScript in externe Dateien. Diese Dateien werden separat geladen und zählen nicht zu den 2 MB des HTML-Dokuments.
<!-- Vorher: Inline-CSS (zählt zum HTML-Gewicht) -->
<style>
.product-card \{ ... 500 Zeilen CSS ... \}
</style>
<!-- Nachher: Externes CSS (zählt nicht zum HTML-Gewicht) -->
<link rel="stylesheet" href="/css/products.css">
Inline-Bilder entfernen
Ersetze Base64-Bilder und Data-URIs durch klassische Bilddateien, die über <img src="..."> referenziert werden.
HTML minifizieren
Entferne unnötige Leerzeichen, HTML-Kommentare und redundante Attribute. Tools wie html-minifier oder Build-Plugins (Webpack, Vite) automatisieren diese Aufgabe.
Serverseitige Komprimierung aktivieren
Konfiguriere gzip oder Brotli auf deinem Webserver. Das reduziert das übertragene Volumen (und damit die Crawl-Zeit), auch wenn das 2-MB-Limit für den dekomprimierten Inhalt gilt.
Lange Listen paginieren
Implementiere für E-Commerce-Kategorieseiten eine saubere Paginierung mit <link rel="next">- und <link rel="prev">-Tags, anstatt alle Produkte auf einer einzigen Seite anzuzeigen.
Hydratations-Payload reduzieren
Wenn du ein SSR-Framework (Next.js, Nuxt) verwendest, überprüfe den Inhalt von __NEXT_DATA__ oder dem Äquivalent. Oft werden dort clientseitig unnötige Daten serialisiert. Filtere die übergebenen Props und behalte nur das Nötigste.
Empfohlener Aktionsplan
- Kritische Seiten testen: Nutze den Page Crawl Checker für deine 10-20 wichtigsten Seiten (Startseite, Kategorien, Top-Produkte, Landingpages).
- Risikoseiten identifizieren: Jede Seite mit einem HTML-Quellcode über 500 KB verdient eine Prüfung. Ab 1 MB ist die Optimierung dringend.
- Optimieren: Externalisiere Inline-CSS/-JS, entferne Base64-Bilder, minifiziere das HTML und aktiviere die serverseitige Komprimierung.
FAQ
Wie schwer ist eine durchschnittliche Webseite im Jahr 2026?
Laut HTTP Archive liegt das mediane Gesamtgewicht einer Webseite (HTML + CSS + JS + Bilder) bei etwa 2,5 MB auf Desktop und 2,2 MB auf Mobilgeräten im Jahr 2026. Der HTML-Quellcode allein wiegt im Median rund 30 KB. Das 2-MB-Limit von Googlebot betrifft ausschließlich den HTML-Quellcode, nicht die Gesamtressourcen.
Was passiert, wenn eine Seite mehr als 2 MB HTML hat?
Googlebot stoppt den Download nach 2 MB (2.097.152 Bytes) unkomprimiertem HTML. Nur der bereits heruntergeladene Inhalt wird zur Indexierung weitergeleitet. Der Rest (interne Links, strukturierte Daten, Text am Seitenende) wird ignoriert. Die Seite erscheint im Index, aber mit unvollständigem Inhalt.
Wie ermittle ich das HTML-Gewicht einer Webseite?
Öffne die Chrome DevTools (F12), Tab Network, filtere nach "Doc" und schau auf die Spalte "Content" (dekomprimierte Größe). Du kannst auch unseren Page Crawl Checker verwenden, der direkt das HTML-Quellcode-Gewicht und den Prozentsatz des verbrauchten 2-MB-Limits anzeigt.
Gilt das 2-MB-Limit für komprimierte Daten?
Nein. Das 2-MB-Limit gilt für den dekomprimierten Inhalt. Selbst wenn dein Server gzip oder Brotli für die Übertragung verwendet, wird die Größe des HTML nach der Dekomprimierung von Googlebot berücksichtigt. Komprimierung ist weiterhin nützlich, um die Übertragung zu beschleunigen, umgeht aber nicht das Limit.
Wie reduziere ich das Gewicht einer HTML-Seite?
Die wirksamsten Maßnahmen: CSS und JavaScript externalisieren (separate Dateien statt Inline-Tags), Base64-Bilder entfernen, HTML minifizieren, lange Listen paginieren und den Hydratations-Payload von SSR-Frameworks (Next.js, Nuxt) reduzieren. Aktiviere außerdem die serverseitige Komprimierung (gzip oder Brotli).
Was ist das Crawl-Budget?
Das Crawl-Budget (Crawl Budget) ist die Anzahl der Seiten, die Googlebot auf deiner Website in einem bestimmten Zeitraum crawlen kann. Es hängt vom Crawl-Rate-Limit (Bandbreite, die Google deiner Website zuteilt) und der Crawl-Nachfrage (Seiten, die Google aktualisieren möchte) ab. Schwere Seiten verbrauchen mehr Budget, was die Crawl-Frequenz anderer Seiten reduziert.
Haben Googlebot Mobile und Desktop dasselbe 2-MB-Limit?
Ja. Das 2-MB-Limit ist identisch für Googlebot Desktop und Googlebot Mobile (Googlebot Smartphone). Der Wechsel zum Mobile-First-Indexing hat diesen Schwellenwert nicht verändert. Beide Crawler-Varianten wenden dieselbe Trunkierungsregel an.
Teste deine Seiten jetzt: Nutze unseren Page Crawl Checker, um sofort zu prüfen, ob deine Seiten das 2-MB-Limit von Googlebot einhalten.
Verwandte Crawl- und Indexierungs-Leitfäden
- Crawl Budget: Googles Crawling deiner Website verstehen und optimieren
- Medianes Seitengewicht 2025: Zahlen und Entwicklung
Quellen
- Google Developers. Googlebot overview: offizielle Dokumentation mit Erwähnung des 2-MB-Limits.
- HTTP Archive. Web Almanac: Statistiken zum Seitengewicht.
- web.dev. Reduce the scope and complexity of style calculations: Best Practices zur Optimierung.
- Google Search Central. Crawl budget management: Crawl-Budget-Verwaltung für große Websites.