Limite di 2 MB di Googlebot: cosa succede quando le tue pagine sono troppo pesanti
Di CaptainDNS
Pubblicato il 10 febbraio 2026

- Googlebot esegue il crawl solo dei primi 2 MB (2 097 152 byte) del codice HTML di una pagina.
- Oltre questo limite, il contenuto viene troncato: link interni, dati strutturati e testo in fondo alla pagina scompaiono dall'indice.
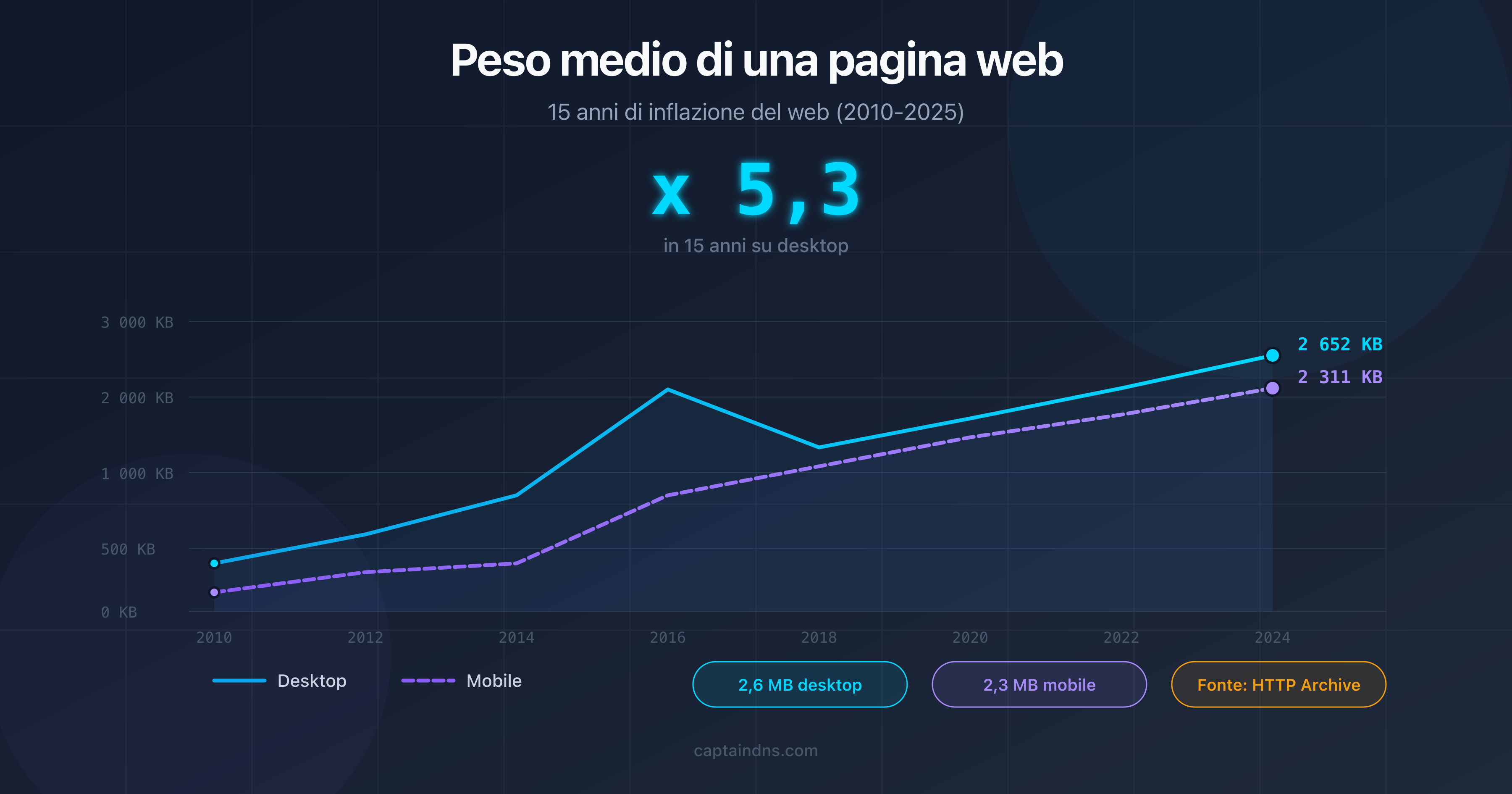
- Il peso mediano di una pagina web supera 2,5 MB di risorse totali nel 2026, ma solo l'HTML sorgente conta per questo limite.
- Testa le tue pagine con il nostro Page Crawl Checker per verificare se sono a rischio.
La tua pagina ha 2,1 MB di HTML? Google ne ha indicizzato solo il 95%. Il resto non esiste per il motore di ricerca.
A inizio febbraio 2026, Google ha aggiornato la sua documentazione tecnica per ricordare un aspetto spesso trascurato: Googlebot esegue il crawl solo dei primi 2 megabyte del codice sorgente HTML di una pagina. Tutto ciò che supera questo limite viene semplicemente ignorato durante l'indicizzazione.
Questo vincolo esiste da diversi anni, ma assume un'importanza crescente man mano che le pagine web diventano più pesanti. Framework JavaScript, immagini inline in base64, Single Page Application con rendering lato server: sempre più pagine si avvicinano a questa soglia invisibile.
In questo articolo analizziamo nel dettaglio il funzionamento di questo limite, le situazioni a rischio e le azioni concrete per prevenirle. Che tu sia un esperto SEO, uno sviluppatore front-end o un responsabile tecnico, qui troverai tutto il necessario per effettuare un audit e ottimizzare le tue pagine.
Cos'è il limite di 2 MB di Googlebot?
La documentazione ufficiale di Google è esplicita: "Googlebot crawls the first 2 MB of a supported file type" (Googlebot esegue il crawl dei primi 2 MB di un tipo di file supportato). Questo corrisponde esattamente a 2 097 152 byte di dati non compressi.
Alcune precisazioni importanti:
- Conta l'HTML sorgente, non le risorse totali della pagina (immagini, CSS, JavaScript esterni). Un file CSS da 500 KB caricato tramite
<link>non rientra nel calcolo. - Il limite si applica al contenuto non compresso. Anche se il tuo server utilizza gzip o Brotli, è la dimensione decompressa che Google misura.
- Ogni risorsa viene valutata singolarmente. Un file JavaScript esterno da 3 MB verrà anch'esso troncato a 2 MB, indipendentemente dalla pagina HTML che lo carica.
- Il limite è identico per Googlebot Desktop e Googlebot Mobile. Il passaggio al mobile-first indexing non ha modificato questa soglia.

Troncamento HTML: quale impatto sulla SEO?
Quando Googlebot raggiunge il limite di 2 MB, interrompe il download del file HTML. La parte già scaricata viene inviata al motore di indicizzazione, ma tutto ciò che si trova dopo il punto di taglio è invisibile per Google.
In pratica, gli elementi situati alla fine del documento HTML sono i più esposti:
- I dati strutturati (JSON-LD in fondo alla pagina): gli schemi FAQPage, HowTo o Product posizionati prima del tag
</body>rischiano di essere tagliati. - I link interni nel footer o nella navigazione secondaria: non verranno scoperti dal crawler.
- Il contenuto testuale delle sezioni inferiori: FAQ, note legali, termini e condizioni.
- Gli script JavaScript inline posizionati in fondo alla pagina: se il tuo framework inietta contenuto dinamico tramite uno script alla fine della pagina, non verrà mai eseguito dal motore di rendering di Google.
Il risultato è insidioso. La pagina appare nell'indice, ma con un contenuto incompleto. I rich snippet non vengono mostrati, il linking interno è parzialmente interrotto e il contenuto editoriale è mutilato.
Chi è interessato?
Le tue pagine sono a rischio? La maggior parte delle pagine web non raggiunge i 2 MB di HTML sorgente. Secondo HTTP Archive, il peso mediano del solo HTML si aggira intorno ai 30 KB nel 2025. Tuttavia, alcuni casi specifici fanno esplodere questa dimensione.
Pagine e-commerce con mega-cataloghi
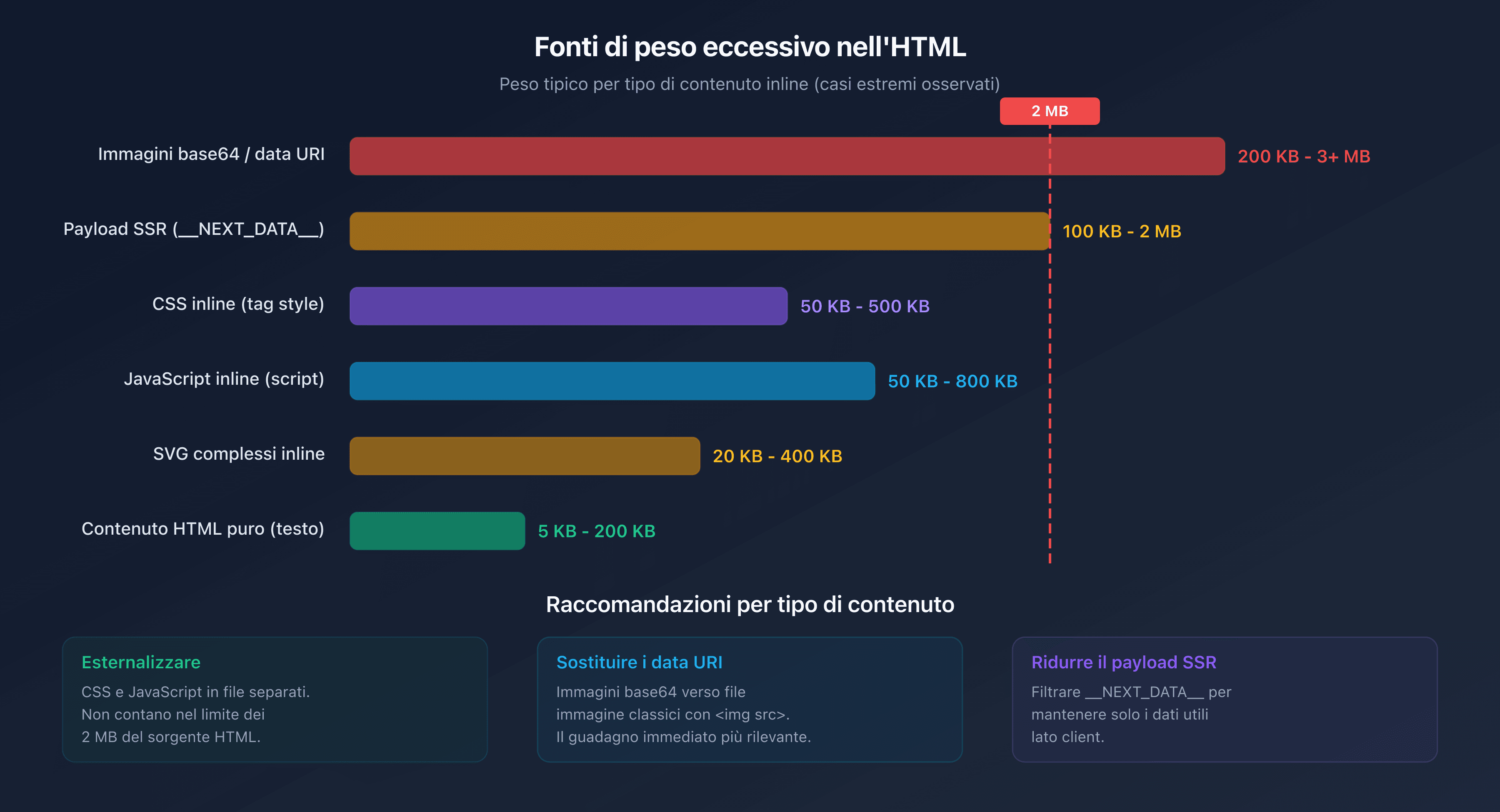
Le pagine di categoria che mostrano centinaia di prodotti con descrizioni inline, attributi tecnici e recensioni dei clienti possono facilmente superare 1 MB di HTML puro. Aggiungendo i dati strutturati Product per ogni articolo, la soglia dei 2 MB viene raggiunta rapidamente.
Single Page Application (SPA) con rendering lato server
Framework come Next.js, Nuxt o SvelteKit iniettano un payload JSON voluminoso in un tag <script> per l'hydration lato client. Questo __NEXT_DATA__ o equivalente può rappresentare diverse centinaia di KB. Sulle pagine ricche di dati, spesso supera da solo 1 MB.
Immagini e SVG inline
Le immagini codificate in base64 o gli SVG complessi inseriti direttamente nell'HTML gonfiano considerevolmente il peso del documento. Un singolo SVG dettagliato può pesare 200 KB. Tre o quattro sono sufficienti per consumare una parte significativa del budget di 2 MB.
JavaScript e CSS inline
Le pagine che incorporano CSS critico o JavaScript direttamente nei tag <style> e <script> invece di esternalizzarli aggiungono peso inutile al documento HTML.
Crawl budget e peso della pagina
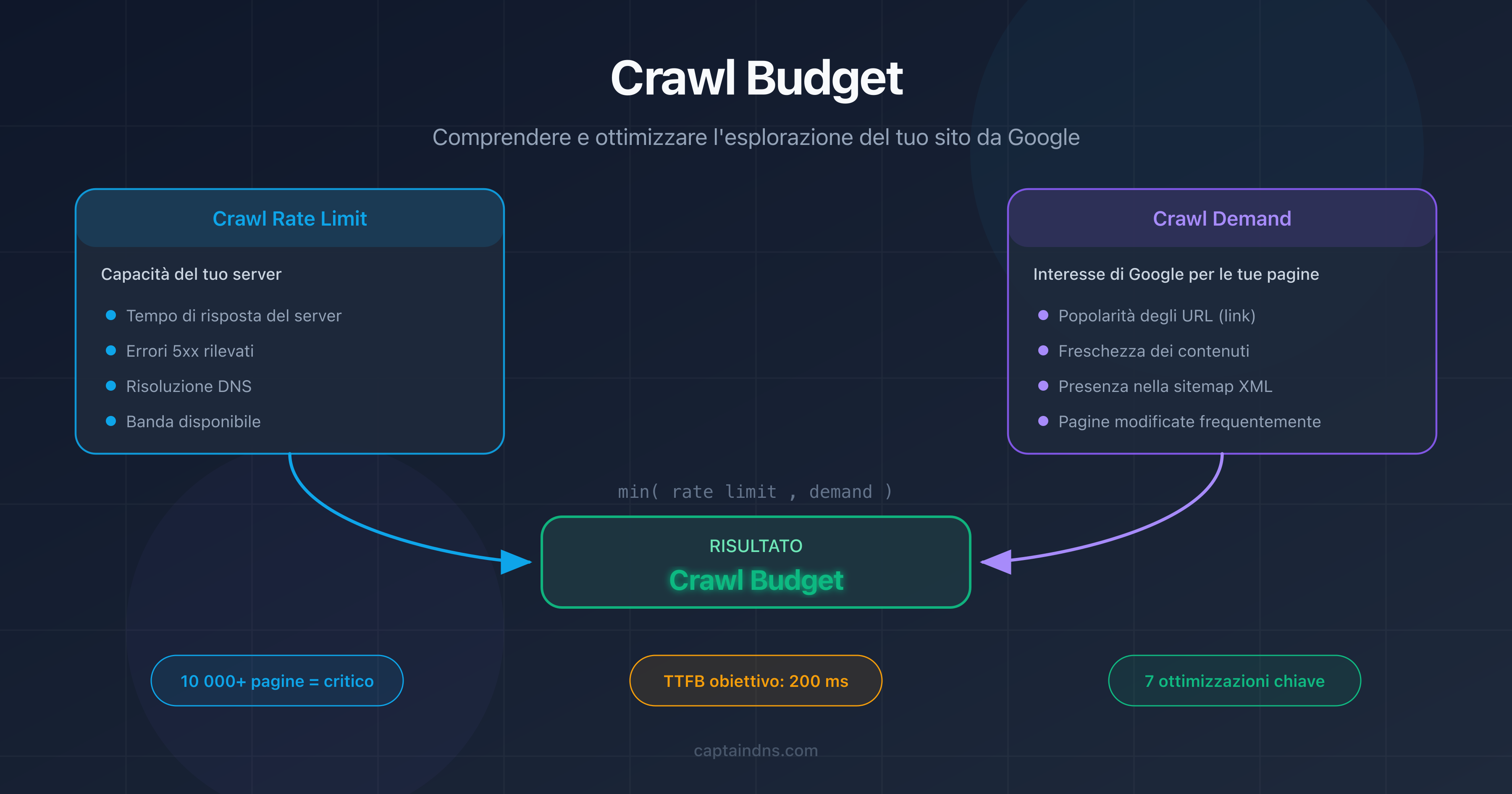
Il crawl budget indica il numero di pagine che Googlebot può sottoporre a crawl sul tuo sito in un determinato intervallo di tempo. Dipende da due fattori: il crawl rate limit (tasso di crawl) e la crawl demand (domanda di crawl).
Il peso delle pagine influisce direttamente sul tasso di crawl. Più una pagina è pesante, più consuma larghezza di banda e tempo di download. Prendiamo un sito con 100 000 pagine. La differenza tra pagine da 50 KB e pagine da 500 KB di HTML si traduce in un fattore 10 sul consumo di risorse.
In concreto:
- Pagine leggere (<100 KB HTML): Googlebot può eseguire il crawl di migliaia di pagine per sessione.
- Pagine medie (100 KB-500 KB): il crawl rallenta sensibilmente.
- Pagine pesanti (500 KB-2 MB): il crawl budget viene consumato rapidamente, le pagine profonde vengono sottoposte a crawl meno frequentemente.
- Pagine troncate (>2 MB): oltre a sprecare il budget, il contenuto nell'indice è incompleto.
Per i grandi siti, l'ottimizzazione del peso HTML non è un lusso. È una necessità per garantire che tutte le pagine importanti vengano sottoposte a crawl e indicizzate correttamente.
Come testare il peso delle tue pagine?
Con i DevTools di Chrome
Apri i DevTools (F12), vai nella scheda Network, ricarica la pagina e filtra per Doc. La colonna Size indica il peso trasferito (compresso) e la colonna Content il peso decompresso. È quest'ultimo valore che conta per il limite di Googlebot.
Con il Page Crawl Checker di CaptainDNS
Il nostro Page Crawl Checker simula il comportamento di Googlebot e mostra immediatamente:
- Il peso dell'HTML sorgente (compresso e decompresso)
- La percentuale del limite di 2 MB consumata
- Gli header HTTP (Content-Type, Content-Encoding, Cache-Control)
- Una diagnosi completa con raccomandazioni di ottimizzazione
HTML sorgente vs risorse totali
Un errore frequente consiste nel guardare il peso totale della pagina (HTML + CSS + JS + immagini) invece del solo HTML sorgente. La cifra di 2,5 MB spesso citata come peso mediano di una pagina web include tutte le risorse. Il solo HTML rappresenta generalmente tra l'1% e il 5% di questo totale.
Come ridurre il peso delle tue pagine HTML?
Da dove iniziare? Se le tue pagine si avvicinano al limite o se desideri ottimizzare il tuo crawl budget, ecco le azioni più efficaci.
Esternalizzare CSS e JavaScript
Sposta tutti i CSS e JavaScript inline in file esterni. Questi file verranno caricati separatamente e non contano nei 2 MB del documento HTML.
<!-- Prima: CSS inline (pesa nell'HTML) -->
<style>
.product-card \{ ... 500 righe di CSS ... \}
</style>
<!-- Dopo: CSS esternalizzato (non pesa nell'HTML) -->
<link rel="stylesheet" href="/css/products.css">
Eliminare le immagini inline
Sostituisci le immagini in base64 e i data URI con file immagine classici referenziati tramite <img src="...">.
Minificare l'HTML
Elimina gli spazi inutili, i commenti HTML e gli attributi ridondanti. Strumenti come html-minifier o i plugin di build (Webpack, Vite) automatizzano questa operazione.
Attivare la compressione del server
Configura gzip o Brotli sul tuo server web. Questo riduce il volume trasferito (e quindi il tempo di crawl), anche se il limite di 2 MB si applica al contenuto decompresso.
Paginare gli elenchi lunghi
Per le pagine di categoria e-commerce, implementa una paginazione corretta con i tag <link rel="next"> e <link rel="prev"> invece di mostrare tutti i prodotti in una singola pagina.
Ridurre il payload di hydration
Se utilizzi un framework SSR (Next.js, Nuxt), esamina il contenuto di __NEXT_DATA__ o equivalente. Spesso vengono serializzati dati inutili lato client. Filtra le props trasmesse per conservare solo lo stretto necessario.
Piano d'azione consigliato
- Testa le tue pagine critiche: utilizza il Page Crawl Checker sulle tue 10-20 pagine più importanti (homepage, categorie, prodotti di punta, landing page).
- Identifica le pagine a rischio: qualsiasi pagina il cui HTML sorgente supera i 500 KB merita un esame. Oltre 1 MB, l'ottimizzazione è urgente.
- Ottimizza: esternalizza il CSS/JS inline, elimina le immagini base64, minifica l'HTML e attiva la compressione del server.
FAQ
Qual è il peso medio di una pagina web nel 2026?
Secondo HTTP Archive, il peso mediano totale di una pagina web (HTML + CSS + JS + immagini) raggiunge circa 2,5 MB su desktop e 2,2 MB su mobile nel 2026. Il solo HTML sorgente pesa in mediana circa 30 KB. Il limite di 2 MB di Googlebot riguarda unicamente l'HTML sorgente, non le risorse totali.
Cosa succede se una pagina supera i 2 MB di HTML?
Googlebot interrompe il download dopo 2 MB (2 097 152 byte) di HTML non compresso. Solo il contenuto già scaricato viene inviato all'indicizzazione. Il resto (link interni, dati strutturati, testo in fondo alla pagina) viene ignorato. La pagina appare nell'indice, ma con un contenuto incompleto.
Come conoscere il peso HTML di una pagina web?
Apri i DevTools di Chrome (F12), scheda Network, filtra per "Doc" e guarda la colonna "Content" (dimensione decompressa). Puoi anche utilizzare il nostro Page Crawl Checker che mostra direttamente il peso dell'HTML sorgente e la percentuale del limite di 2 MB consumata.
Il limite di 2 MB si applica ai dati compressi?
No. Il limite di 2 MB si applica al contenuto decompresso. Anche se il tuo server utilizza gzip o Brotli per la trasmissione, è la dimensione dell'HTML una volta decompresso che viene presa in considerazione da Googlebot. La compressione resta utile per accelerare il trasferimento, ma non permette di aggirare il limite.
Come ridurre il peso di una pagina HTML?
Le azioni più efficaci: esternalizzare CSS e JavaScript (file separati invece di tag inline), eliminare le immagini in base64, minificare l'HTML, paginare gli elenchi lunghi e ridurre il payload di hydration dei framework SSR (Next.js, Nuxt). Attiva anche la compressione del server (gzip o Brotli).
Cos'è il crawl budget?
Il crawl budget è il numero di pagine che Googlebot può sottoporre a crawl sul tuo sito in un determinato intervallo di tempo. Dipende dal tasso di crawl (larghezza di banda che Google assegna al tuo sito) e dalla domanda di crawl (pagine che Google desidera aggiornare). Le pagine pesanti consumano più budget, riducendo la frequenza di crawl delle altre pagine.
Googlebot Mobile e Desktop hanno lo stesso limite di 2 MB?
Sì. Il limite di 2 MB è identico per Googlebot Desktop e Googlebot Mobile (Googlebot Smartphone). Il passaggio al mobile-first indexing non ha modificato questa soglia. Entrambe le varianti del crawler applicano la stessa regola di troncamento.
Testa le tue pagine ora: utilizza il nostro Page Crawl Checker per verificare istantaneamente se le tue pagine rispettano il limite di 2 MB di Googlebot.
Guide su crawl e indicizzazione correlate
- Crawl budget: come comprendere e ottimizzare l'esplorazione del tuo sito da parte di Google
- Peso medio di una pagina web nel 2025: dati e tendenze
Fonti
- Google Developers. Googlebot overview: documentazione ufficiale che menziona il limite di 2 MB.
- HTTP Archive. Web Almanac: statistiche sul peso delle pagine web.
- web.dev. Reduce the scope and complexity of style calculations: best practice di ottimizzazione.
- Google Search Central. Crawl budget management: gestione del crawl budget per i grandi siti.