Crawl budget: entiende y optimiza la exploración de tu sitio por Google
Por CaptainDNS
Publicado el 11 de febrero de 2026
- El crawl budget es el número de páginas que Googlebot elige explorar en tu sitio en un periodo de tiempo determinado.
- Es el resultado de dos factores: el crawl rate limit (capacidad de tu servidor) y el crawl demand (interés de Google por tus páginas).
- En sitios de más de 10 000 páginas, un crawl budget mal optimizado retrasa la indexación de páginas importantes.
- Las páginas pesadas consumen más presupuesto: comprueba el peso de tus páginas con nuestro Page Crawl Checker.
Google explora miles de millones de páginas cada día. Pero no todas las tuyas. El crawl budget es el número de páginas que Googlebot elige explorar en tu sitio en un intervalo de tiempo dado. Nada que ver con un presupuesto financiero.
¿Tu sitio tiene menos de unos pocos miles de páginas? Entonces el crawl budget probablemente no sea un problema. Google tiene suficientes recursos para explorarlo todo. Pero cuando tu sitio supera las 10 000 páginas, o tu arquitectura genera miles de URL de filtrado y paginación, la gestión del crawl budget se convierte en una palanca SEO fundamental.
Esta guía cubre tres puntos: qué es el crawl budget, cómo verificarlo en Google Search Console y 7 técnicas concretas para optimizarlo. También abordamos un factor que suele pasar desapercibido: el impacto del rendimiento DNS en la velocidad de crawl.
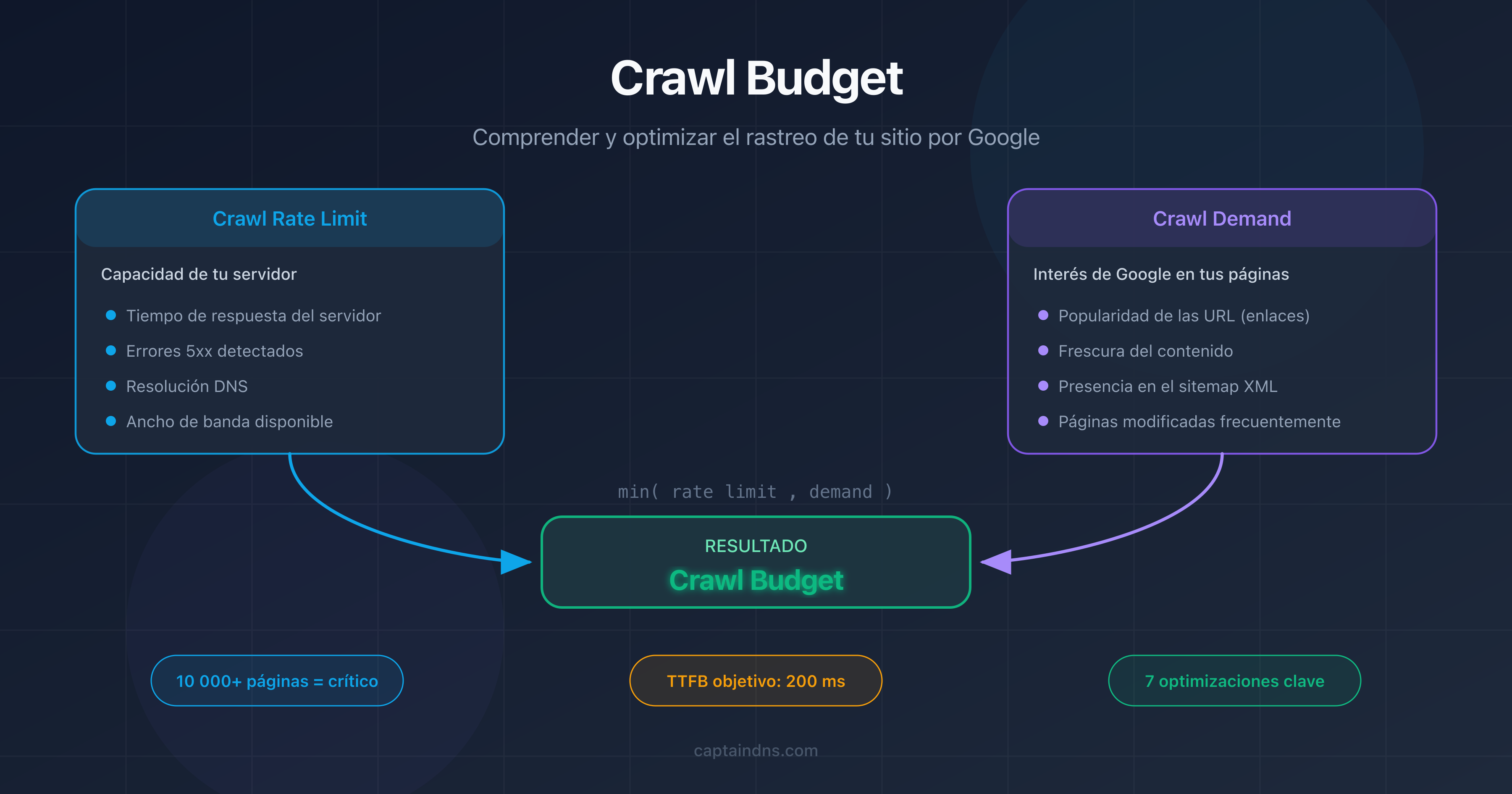
¿Qué es el crawl budget?
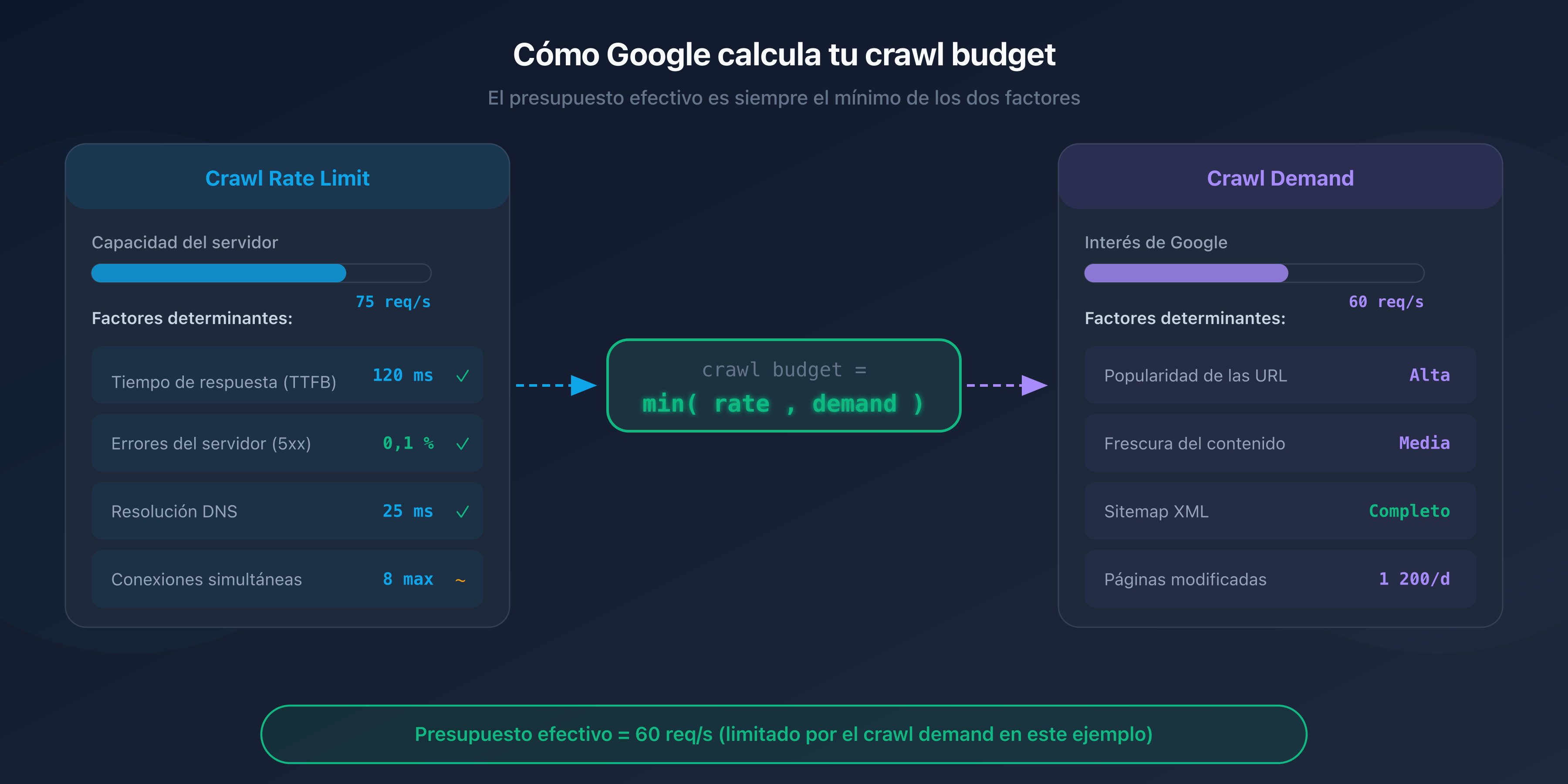
El crawl budget es un concepto definido por Google que combina dos factores independientes: el crawl rate limit y el crawl demand.
Crawl rate limit: la capacidad de tu servidor
El crawl rate limit representa el número máximo de solicitudes simultáneas que Googlebot puede enviar a tu servidor sin sobrecargarlo. Google ajusta este límite automáticamente en función de la capacidad de respuesta de tu sitio.
Si tu servidor responde rápido (tiempo de respuesta inferior a 200 ms), Googlebot aumenta el ritmo. Si las respuestas se ralentizan o aparecen errores 5xx, reduce la cadencia para no agravar la situación.
Crawl demand: el interés de Google por tus páginas
El crawl demand refleja la voluntad de Google de rastrear tus páginas. Varios factores lo influyen:
- La popularidad de tus URL: las páginas que reciben enlaces externos o que generan tráfico se rastrean con mayor frecuencia.
- La frescura: las páginas que cambian con frecuencia (noticias, precios, stock) se revisitan más a menudo que las páginas estáticas.
- La presencia en el sitemap: las URL incluidas en tu sitemap XML le indican a Google que merecen ser exploradas.
La ecuación del crawl budget
El crawl budget efectivo de tu sitio es el mínimo entre el crawl rate limit y el crawl demand:
Crawl budget = min(crawl rate limit, crawl demand)
En la práctica: aunque tu servidor pueda soportar 100 solicitudes por segundo, Google no rastreará más páginas de las que considere necesarias. Y a la inversa, si Google quiere explorar 50 000 páginas pero tu servidor solo soporta 5 solicitudes por segundo, el crawl será lento.
¿Por qué el crawl budget es importante para el SEO?
Impacto en la indexación
Una página no rastreada es una página no indexada. Si Googlebot no tiene tiempo de explorar ciertas URL de tu sitio, no aparecerán en los resultados de búsqueda, aunque su contenido sea excelente.
El problema es especialmente visible en los sitios grandes. Las páginas profundas, accesibles tras 4-5 clics desde la página de inicio, se rastrean con menor frecuencia. Si tu crawl budget es limitado, estas páginas pueden tardar semanas, incluso meses, en ser indexadas.
¿Cuándo el crawl budget se convierte en un problema?
Google lo dice claramente: el crawl budget solo es un tema relevante para los sitios grandes. Estas son las situaciones en las que debes preocuparte:
- Sitios con más de 10 000 URL únicas: e-commerce, directorios, portales de contenido.
- Sitios con navegación por facetas: las combinaciones de filtros (talla, color, precio, marca) generan miles de URL casi idénticas.
- Sitios con contenido duplicado: versiones HTTP y HTTPS, www y sin www, o parámetros de URL que crean duplicados.
- Sitios con errores técnicos: las cadenas de redirecciones, los errores 404 y las páginas soft-404 desperdician presupuesto sin aportar nada.
Los sitios más afectados
Los sitios e-commerce son los primeros afectados. Un catálogo de 50 000 productos con 20 facetas de filtrado puede generar millones de URL. Sin una gestión estricta del robots.txt y de las etiquetas canonical, Googlebot pasa su tiempo rastreando páginas de bajo valor en detrimento de las fichas de productos estratégicas.
Los sitios de medios con archivos voluminosos, los foros y los sitios de anuncios clasificados también se ven afectados.
¿Cómo verificar tu crawl budget?
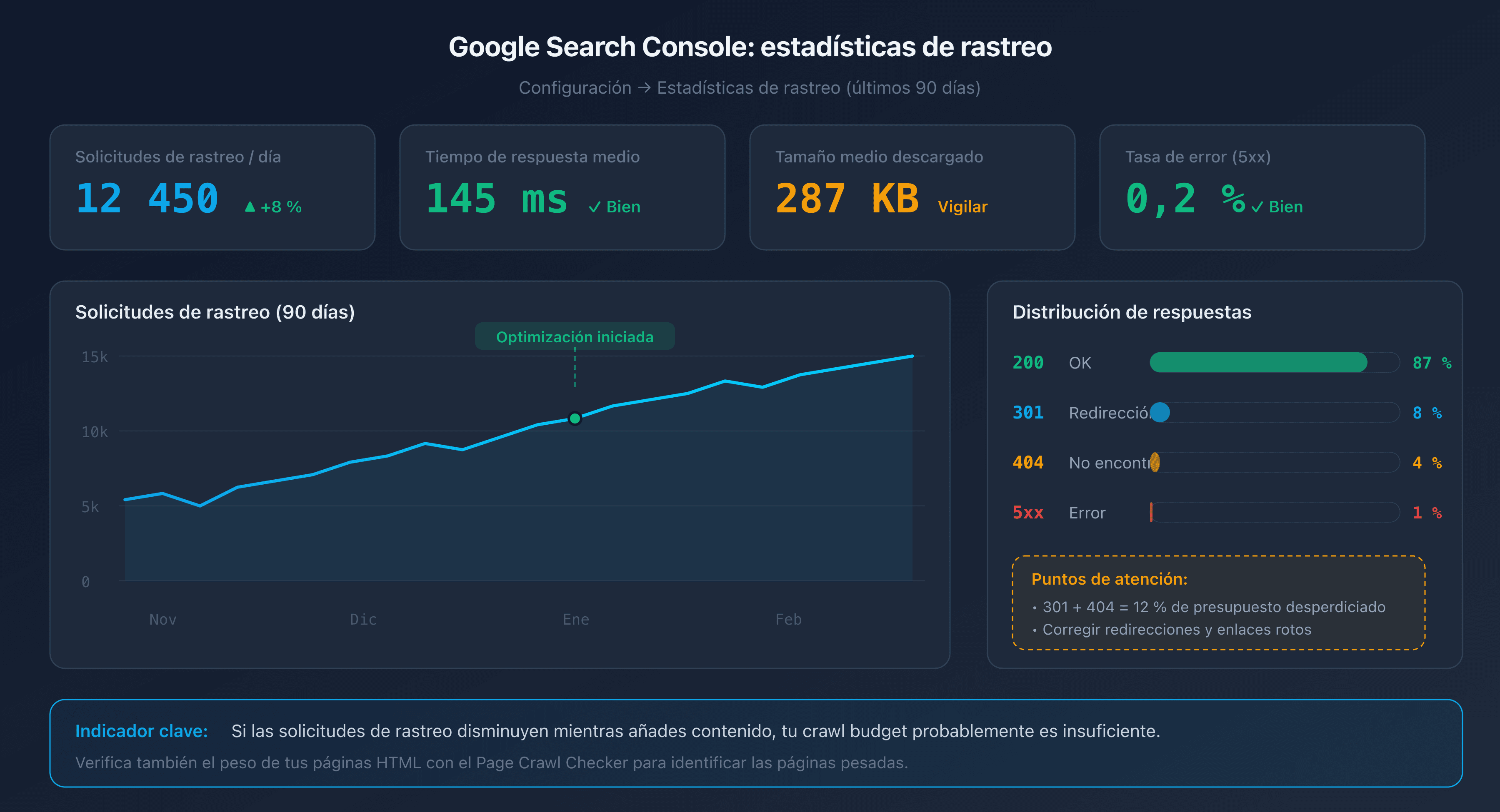
Informe "Estadísticas de rastreo" en Google Search Console
Google Search Console proporciona un informe dedicado en la sección Configuración > Estadísticas de rastreo. Este informe muestra los datos de los últimos 90 días:
- El número total de solicitudes de crawl por día.
- El tiempo de respuesta medio de tu servidor.
- La distribución por tipo de respuesta (200, 301, 404, 5xx).
- El tamaño medio de las páginas descargadas.
Un buen indicador: si el número de solicitudes de crawl disminuye mientras añades contenido, tu crawl budget probablemente sea insuficiente.
Análisis de logs del servidor
Los logs de tu servidor web (Apache, Nginx) registran cada visita de Googlebot. Al analizarlos, puedes identificar:
- Qué páginas se rastrean con mayor frecuencia (y cuáles no se rastrean nunca).
- Los patrones de crawl (horarios, frecuencia, profundidad).
- Los errores devueltos a Googlebot.
Filtra las solicitudes cuyo User-Agent contenga "Googlebot" para aislar el tráfico del crawler.
URL Inspection Tool
La herramienta de inspección de URL en Google Search Console permite verificar el estado individual de una página: fecha del último rastreo, estado de indexación y posibles problemas detectados.
7 técnicas para optimizar tu crawl budget
1. Corregir los enlaces rotos y las cadenas de redirecciones
Cada enlace roto (404) y cada cadena de redirecciones (301 hacia 301 hacia 301) desperdicia una solicitud de crawl. Googlebot sigue el enlace, recibe un error o una redirección y tiene que volver a empezar. Resultado: presupuesto consumido para nada.
Utiliza un crawler como Screaming Frog o Sitebulb para detectar los enlaces rotos y las cadenas de redirecciones en tu sitio. Corrige los enlaces para que apunten directamente al destino final.
2. Optimizar el robots.txt
El archivo robots.txt permite bloquear el acceso de Googlebot a las secciones inútiles de tu sitio. Los objetivos habituales:
- Páginas de administración y back-office.
- Páginas de resultados de búsqueda interna.
- Páginas de filtrado y ordenación (facetas).
- Archivos CSS/JS que no necesitan ser rastreados individualmente.
# robots.txt - bloquear las páginas de filtrado
User-agent: Googlebot
Disallow: /search?
Disallow: /filter/
Disallow: /sort/
Disallow: /admin/
Atención: bloquear una URL en robots.txt impide el rastreo, pero no la desindexación. Si una página bloqueada recibe enlaces externos, Google puede indexarla igualmente (sin rastrearla) basándose en los textos ancla de los enlaces.
3. Limpiar el sitemap XML
Tu sitemap XML solo debe contener las URL que deseas que se indexen. Elimina:
- Las URL que devuelven errores 404 o redirecciones 301.
- Las URL bloqueadas por robots.txt.
- Las URL con una etiqueta
noindex. - Las páginas de baja calidad o los duplicados.
Un sitemap limpio le indica a Google qué páginas merecen su atención. Si tu sitemap contiene 100 000 URL de las cuales solo 20 000 son realmente útiles, estás diluyendo la señal.
4. Eliminar el contenido duplicado con canonical
Las páginas duplicadas son un desperdicio directo de crawl budget. Googlebot rastrea cada URL por separado, incluso si el contenido es idéntico.
Utiliza la etiqueta <link rel="canonical"> para indicar la versión preferida de una página. Ejemplos comunes:
- Parámetros de tracking (
?utm_source=...). - Variantes de ordenación y paginación.
- Versiones HTTP/HTTPS o www/sin www.
5. Reducir el peso de las páginas HTML
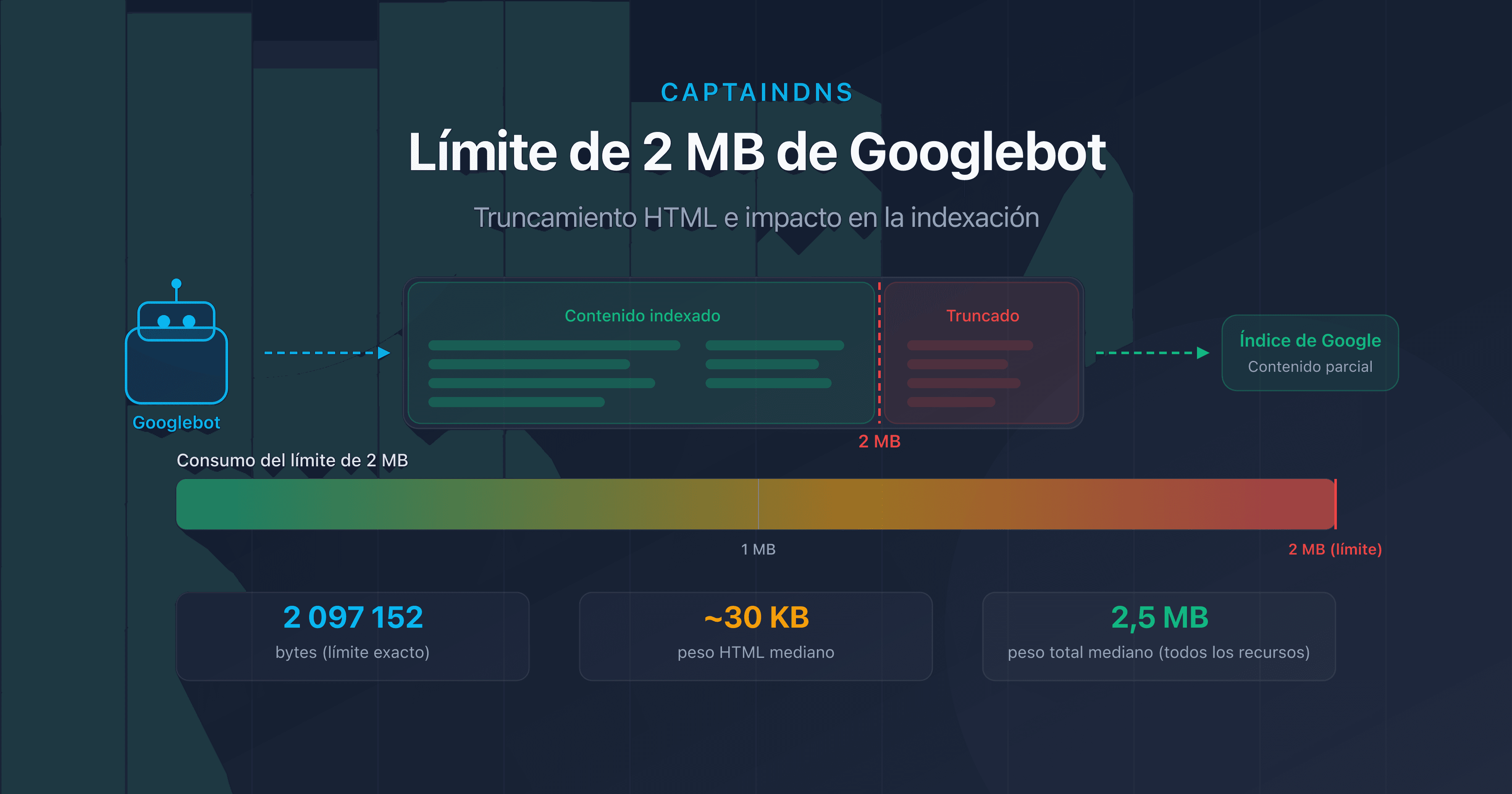
Las páginas pesadas consumen más ancho de banda y más tiempo de descarga, lo que ralentiza el crawl. Más allá de 2 Mo de HTML fuente, Googlebot directamente trunca el contenido.
Las acciones más eficaces:
- Externalizar el CSS y el JavaScript inline.
- Eliminar las imágenes en base64 y los SVG inline.
- Minificar el HTML.
- Paginar las listas largas.
6. Mejorar el tiempo de respuesta del servidor
Cuanto más rápido responda tu servidor, más aumentará Googlebot el crawl rate limit. El objetivo: un tiempo de respuesta del servidor (TTFB) inferior a 200 ms.
Las principales palancas:
- Caché en el servidor: Redis, Varnish o un CDN para las páginas estáticas.
- Base de datos: optimizar las consultas lentas, añadir índices.
- Infraestructura: un alojamiento dimensionado para el tráfico esperado.
7. Evitar las trampas de crawl
Las trampas de crawl (crawl traps) son secciones de tu sitio que generan un número casi infinito de URL. Googlebot puede perderse en ellas y consumir todo el presupuesto sin llegar nunca a tus páginas importantes.
Ejemplos comunes:
- Calendarios infinitos: cada mes genera una nueva URL, sin límite en el tiempo.
- Facetas combinadas: talla + color + precio + marca = miles de URL.
- Sesiones e identificadores en la URL: cada visitante genera URL únicas.
- Ordenación y paginación: página 1 ordenada por precio, página 1 ordenada por fecha, página 1 ordenada por popularidad = 3 URL para el mismo contenido.
El factor DNS: el impacto invisible en el crawl budget
Tu robots.txt está limpio, tu sitemap es impecable, tus páginas son ligeras. Y aun así, el crawl sigue siendo lento. ¿Has comprobado tu rendimiento DNS? Antes de cada solicitud HTTP, Googlebot debe resolver el nombre de dominio de tu sitio. Si esa resolución es lenta, cada solicitud de crawl empieza con una desventaja.
Resolución DNS y Googlebot
En cada sesión de crawl, Googlebot realiza una resolución DNS para localizar la dirección IP de tu servidor. Si tu servidor DNS tarda 200 ms en responder en lugar de 20 ms, eso añade 180 ms de latencia a cada solicitud.
En una sesión de crawl de 1 000 páginas, esta diferencia se traduce en 180 segundos (3 minutos) de tiempo perdido únicamente en la resolución DNS. Googlebot interpreta esa lentitud como una señal de sobrecarga y reduce el crawl rate limit.
TTL óptimo para el crawl
El TTL (Time To Live) de tus registros DNS determina cuánto tiempo el resolvedor DNS de Google almacena la respuesta en caché. Un TTL demasiado corto (menos de 300 segundos) obliga a resolver el dominio con mayor frecuencia. Un TTL entre 3 600 y 86 400 segundos (1 hora a 24 horas) es un buen equilibrio entre reactividad y rendimiento.
Cómo probar tu rendimiento DNS
Verifica el tiempo de resolución DNS de tu dominio con herramientas como dig o las herramientas DNS de CaptainDNS. Un tiempo de resolución inferior a 50 ms es excelente. Por encima de 100 ms, hay margen de mejora (elección del proveedor DNS, configuración anycast, TTL).
Plan de acción recomendado
- Analizar tu crawl budget: consulta el informe "Estadísticas de rastreo" en Google Search Console. Anota el número de solicitudes por día, el tiempo de respuesta medio y la distribución de los códigos de respuesta.
- Probar el peso de tus páginas críticas: utiliza el Page Crawl Checker en tus páginas más importantes. Identifica las que superan los 500 Ko de HTML fuente.
- Aplicar las 7 técnicas: corrige los enlaces rotos, limpia tu sitemap, elimina los duplicados, reduce el peso de las páginas y vigila tu rendimiento DNS. Mide el impacto en Search Console tras 2-4 semanas.
FAQ
¿Qué es el crawl budget en SEO?
El crawl budget es el número de páginas que Googlebot explora en tu sitio en un intervalo de tiempo dado. Es el resultado de dos factores: el crawl rate limit (número máximo de solicitudes que tu servidor puede absorber) y el crawl demand (interés de Google por tus URL). Las páginas no rastreadas no pueden ser indexadas.
¿El crawl budget afecta a los sitios pequeños?
No, para la gran mayoría de los sitios. Google confirma que el crawl budget solo es un factor limitante para los sitios con más de 10 000 URL únicas, o para los sitios que generan muchas URL mediante la navegación por facetas, los parámetros de ordenación y la paginación. Si tu sitio tiene menos de unos pocos miles de páginas, Googlebot no tendrá ningún problema para explorarlo todo.
¿Cómo verificar el crawl budget en Google Search Console?
Ve a Google Search Console, sección Configuración, y haz clic en "Estadísticas de rastreo". Este informe muestra el número de solicitudes de crawl por día, el tiempo de respuesta medio, el tamaño de las páginas descargadas y la distribución de los códigos HTTP de los últimos 90 días. Una disminución en el número de solicitudes a pesar de añadir contenido indica un problema de crawl budget.
¿Cuál es la diferencia entre crawl rate limit y crawl demand?
El crawl rate limit es la capacidad técnica: el número máximo de solicitudes que Googlebot envía a tu servidor sin sobrecargarlo. El crawl demand es el interés de Google: cuántas páginas Google quiere realmente explorar en función de su popularidad, su frescura y su presencia en el sitemap. El crawl budget efectivo es el mínimo de ambos.
¿El robots.txt afecta al crawl budget?
Sí. Las reglas Disallow del robots.txt impiden que Googlebot rastree las URL afectadas, lo que libera presupuesto para las páginas importantes. Atención: bloquear una URL en robots.txt no impide su indexación si recibe enlaces externos. Para desindexar una página, utiliza la etiqueta meta noindex (que requiere que la página sea rastreable).
¿Las redirecciones consumen crawl budget?
Sí. Cada redirección (301 o 302) consume una solicitud de crawl. Googlebot sigue el enlace inicial, recibe la redirección y luego tiene que realizar una nueva solicitud hacia el destino. Las cadenas de redirecciones (A hacia B hacia C hacia D) multiplican el desperdicio. Corrige los enlaces para que apunten directamente a la URL final.
¿Cómo afecta el peso de las páginas al crawl budget?
Cuanto más pesada es una página en HTML, más ancho de banda y tiempo de descarga consume. Googlebot ajusta el crawl rate limit en función del tiempo de respuesta. Las páginas ligeras (menos de 100 Ko de HTML) permiten rastrear más páginas por sesión. Por encima de 2 Mo de HTML fuente, Googlebot trunca el contenido y solo lo indexa parcialmente.
Prueba tus páginas ahora: utiliza nuestro Page Crawl Checker para verificar el peso de tus páginas HTML y su conformidad con el límite de 2 Mo de Googlebot.
Guías de rastreo e indexación relacionadas
- Límite de 2 Mo de Googlebot: qué ocurre cuando tus páginas son demasiado pesadas: comprueba si tus páginas superan el umbral de truncamiento.
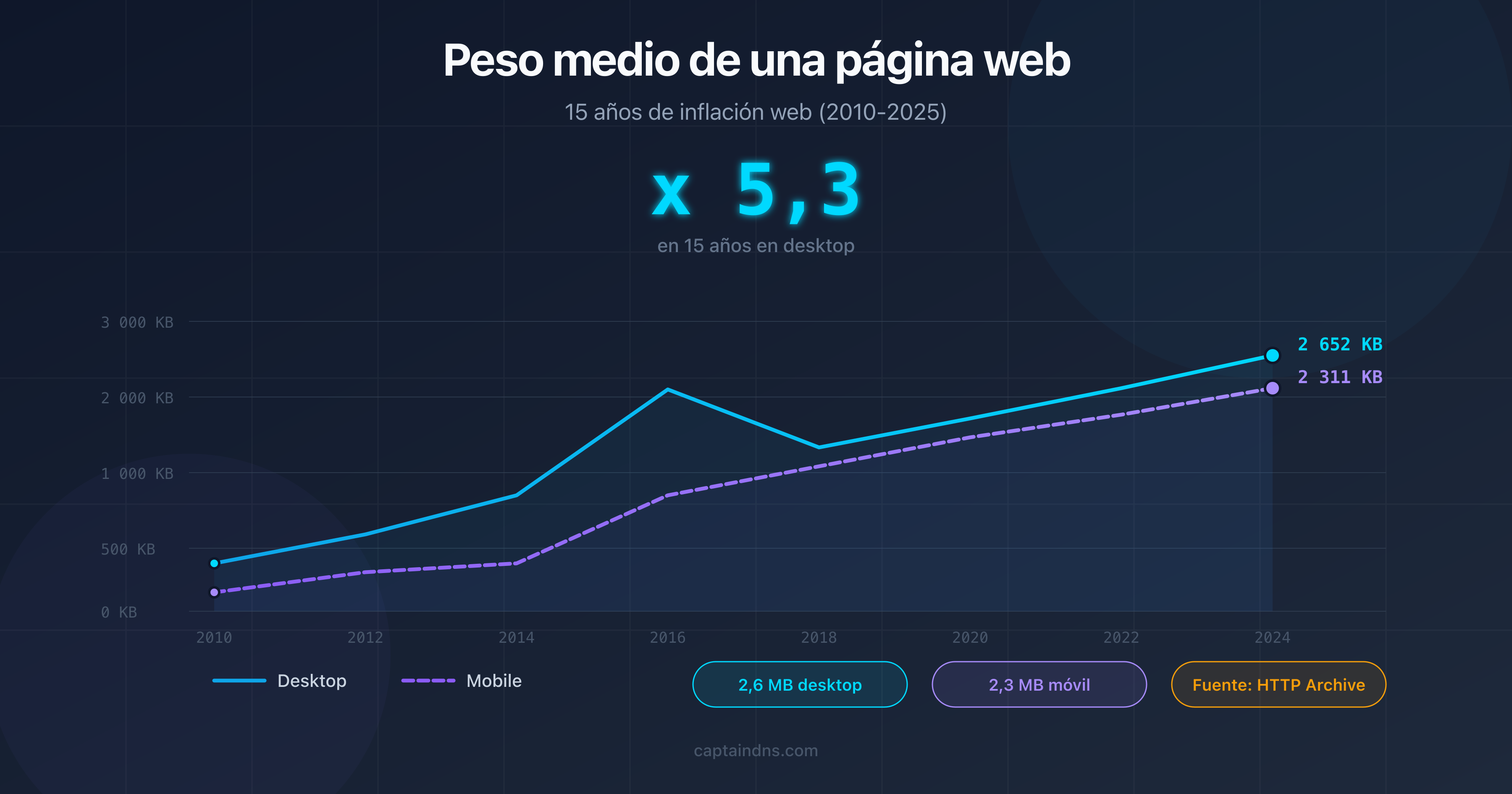
- Peso medio de una página web en 2025: 15 años de inflación del web
Fuentes
- Google Search Central. Large site management and crawl budget: documentación oficial sobre el crawl budget.
- Google Developers. Googlebot overview: funcionamiento de Googlebot y límites de crawl.
- HTTP Archive. Web Almanac: estadísticas sobre el peso de las páginas web.
- web.dev. Optimize server response times (TTFB): buenas prácticas para reducir el tiempo de respuesta del servidor.