Redirections HTTP et crawlers IA en 2026 : ce que GPTBot, ClaudeBot et PerplexityBot voient (vraiment) de votre site
Par CaptainDNS
Publié le 11 mai 2026
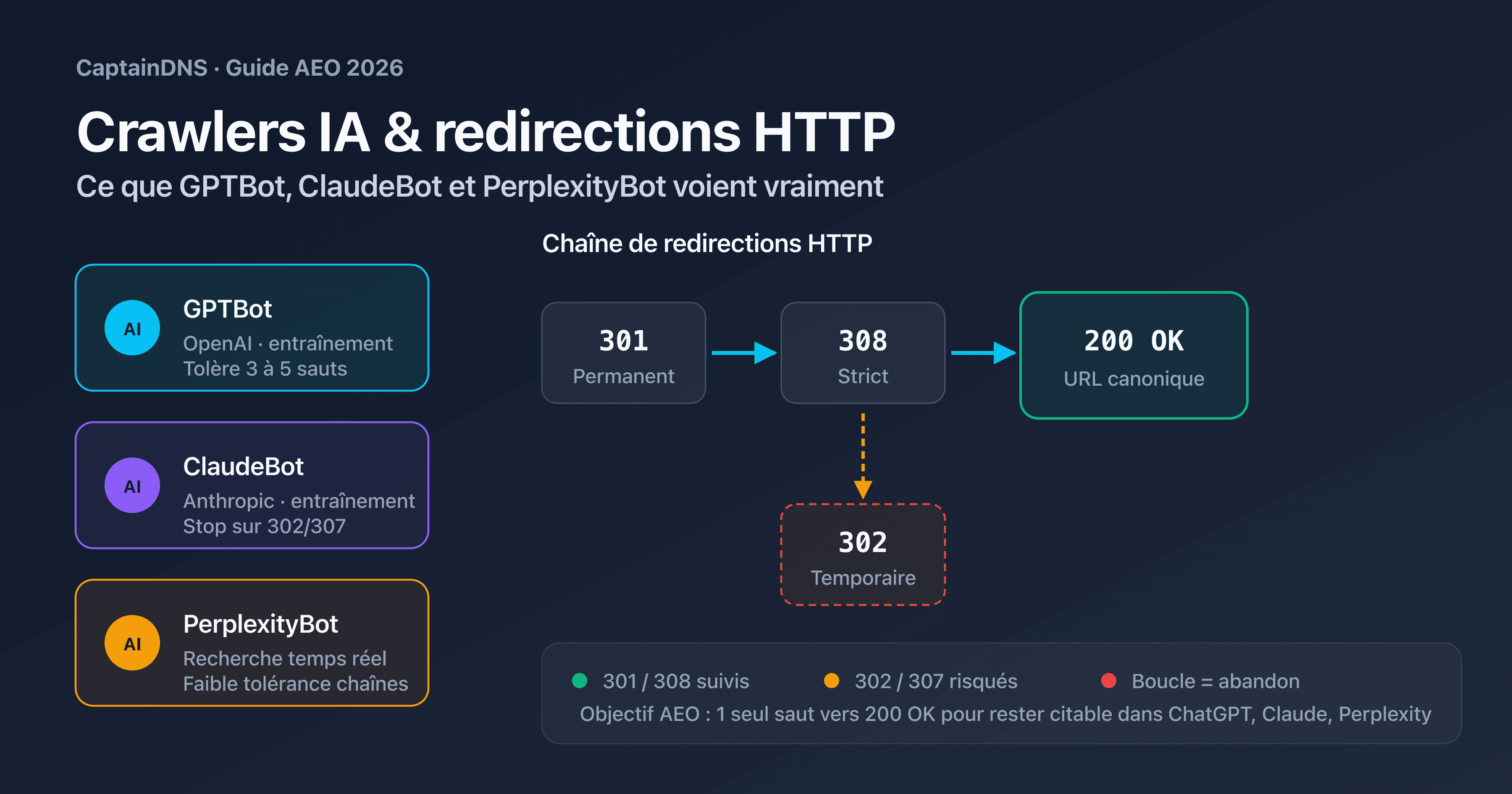
- Trois user-agents distincts (GPTBot, ClaudeBot, PerplexityBot), trois comportements différents face aux redirections HTTP
- Tolérance aux chaînes : 3 à 5 sauts observés en pratique, 30 en théorie RFC, 10 côté Googlebot
llms.txtn'est pas indexé derrière une 301 mal configurée vers un autre chemin- Pour rester visible dans AI Overviews et Perplexity Answers, votre URL finale doit retourner 200 OK en 1 à 3 sauts maximum
- Auditer le comportement réel de chaque bot avec un vérificateur de redirections par user-agent
Selon Search Engine Journal, les crawlers IA ont généré plus de 68 millions de visites sur les sites web en 2025, en croissance de 250 % en un an. Pourtant, la majorité des sites optimisés pour Googlebot n'ont jamais été testés contre GPTBot, ClaudeBot ou PerplexityBot. Une chaîne de redirections qui passe pour Google peut faire disparaître une page entière des réponses ChatGPT, Claude ou Perplexity.
Le problème ne vient pas du protocole HTTP : les redirections 301, 302, 307 et 308 sont normalisées depuis vingt ans dans le RFC 9110. Le problème vient de la mission de chaque bot et des limites internes que chaque éditeur a posées. OpenAI, Anthropic et Perplexity documentent partiellement leurs crawlers, mais aucun n'expose publiquement le nombre exact de sauts qu'il tolère ni la façon dont il négocie une chaîne 301 → 302 → 308 → 200.
Cet article documente le comportement réel des trois crawlers IA majeurs en 2026, fournit un tableau comparatif des user-agents et des plages d'IP officielles, explique l'interaction entre llms.txt et les redirections, et propose cinq bonnes pratiques d'optimisation orientées generative engine optimization (GEO) et answer engine optimization (AEO).
Public visé : équipes SEO confrontées au passage Google-only vers un écosystème multi-IA, administrateurs systèmes responsables de migrations de domaine, directions techniques de PME qui veulent préserver leur visibilité dans les réponses générées par l'IA.
Avant d'entrer dans le détail technique, un constat de terrain : les sites qui n'optimisent pas pour les crawlers IA en 2026 ne perdent pas leur visibilité du jour au lendemain. La dégradation est progressive et silencieuse. Les pages mal configurées disparaissent une à une des réponses générées, sans signal d'erreur, sans alerte côté éditeur. Les outils analytics classiques (Google Analytics, Search Console) ne reflètent pas cette perte car les visites IA ne génèrent pas toujours de clic référent traçable. Seule l'analyse des journaux serveur, croisée avec un audit régulier des chaînes de redirection, permet de mesurer la santé réelle de l'indexation IA d'un site.
Vérifiez ce que les crawlers IA voient vraiment
Pourquoi un crawler IA n'est pas un crawler de moteur classique ?
Le terme « crawler IA » regroupe trois familles d'agents qui n'ont ni la même mission, ni les mêmes contraintes techniques, ni le même comportement HTTP. Les confondre conduit à mal configurer ses redirections et à perdre une visibilité importante dans les réponses générées par les LLM.
Trois familles, trois objectifs
La première famille est celle des crawlers d'entraînement. GPTBot d'OpenAI, ClaudeBot d'Anthropic et anthropic-ai alimentent les jeux de données d'entraînement des modèles fondationnels. Ils crawlent en masse, sans urgence, et respectent strictement robots.txt. Une page bloquée pour eux ne sera jamais utilisée pour entraîner GPT-5 ou Claude 4.
La deuxième famille est celle des crawlers de recherche temps réel. OAI-SearchBot (utilisé par ChatGPT Search), PerplexityBot et Claude-SearchBot indexent en continu pour répondre à des requêtes utilisateur en direct. Leur tolérance aux pages lentes ou aux chaînes de redirections est plus faible : un saut de trop, et la page n'est pas affichée dans la réponse générée.
La troisième famille est celle des agents conversationnels. ChatGPT-User et Claude-User se déclenchent quand un utilisateur demande explicitement à l'assistant de visiter une URL. Ils se comportent davantage comme un navigateur, avec moins de respect strict du robots.txt et plus de tolérance aux chaînes courtes.
Conséquence pour les redirections
Bloquer ou rediriger un crawler d'entraînement n'a pas le même effet que bloquer un crawler de recherche. Si vous bloquez GPTBot mais autorisez OAI-SearchBot, votre contenu n'entraîne pas GPT-5 mais reste citable en temps réel dans ChatGPT Search. Inversement, une chaîne 301 → 302 → 200 que GPTBot digère sans broncher peut faire abandonner OAI-SearchBot qui répondra alors à l'utilisateur sans citer votre page.
Les RFC 9110 et 9112 définissent la sémantique HTTP que tous les bots, IA ou non, sont censés respecter. En pratique, chaque éditeur applique ses propres limites internes pour optimiser ses budgets de crawl.
Le contexte 2023-2026 : émergence et fragmentation
GPTBot a été annoncé par OpenAI le 7 août 2023. Avant cette date, l'entraînement des modèles GPT-3 et GPT-4 s'appuyait sur Common Crawl, un dataset agrégé par une fondation tierce. La création d'un crawler propriétaire signalait un tournant : les éditeurs de LLM voulaient maîtriser leur source d'entraînement, et permettre aux éditeurs web de leur signaler explicitement leurs préférences via robots.txt.
ClaudeBot a suivi en mars 2024, accompagné d'anthropic-ai pour des cas d'usage internes plus anciens. PerplexityBot existait depuis 2022 mais s'est démarqué en 2024-2025 en publiant officiellement ses plages d'IP et en s'alignant sur les standards de transparence d'OpenAI et d'Anthropic.
Fin 2024, les trois éditeurs ont introduit des crawlers distincts pour la recherche temps réel : OAI-SearchBot, Claude-SearchBot. Cette séparation est cruciale pour les éditeurs web : autoriser ou bloquer ne peut plus se faire de façon binaire. Chaque crawler a son robots.txt token, son user-agent, et son comportement HTTP propre.
Tableau comparatif des user-agents en 2026
Avant de configurer une stratégie de redirections orientée IA, il faut connaître précisément les user-agents qui frappent à la porte de votre site. Le tableau ci-dessous synthétise les informations officielles publiées par OpenAI, Anthropic et Perplexity à fin avril 2026.
Tableau de référence
| Crawler | Éditeur | Mission | User-Agent (extrait) | Token robots.txt |
|---|---|---|---|---|
| GPTBot | OpenAI | Entraînement | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (temps réel) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agent (visite à la demande) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Entraînement | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Entraînement (legacy) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agent (visite à la demande) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (temps réel) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indexation pour réponses | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agent (visite à la demande) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Plages d'IP publiées
OpenAI publie ses plages dans https://openai.com/gptbot.json et https://openai.com/searchbot.json. Anthropic publie un fichier équivalent à https://docs.anthropic.com/claude/page/claudebot.json. Perplexity expose ses IP via https://www.perplexity.ai/perplexitybot.json.
Vérifier qu'une visite annoncée comme GPTBot provient bien d'une IP OpenAI est la seule façon fiable de filtrer les usurpations. Un user-agent GPTBot envoyé depuis une IP résidentielle ne doit pas recevoir le même traitement HTTP qu'un crawler officiel.
Fréquence et intensité
Les trois éditeurs limitent leur taux de crawl pour ne pas surcharger les sites. L'ordre de grandeur observé sur des sites publics : GPTBot crawle entre 1 et 5 requêtes par seconde, ClaudeBot entre 0,5 et 2 requêtes par seconde, PerplexityBot moins de 1 requête par seconde. Les agents (ChatGPT-User, Claude-User, Perplexity-User) génèrent des pics ponctuels lors de visites utilisateur, mais restent négligeables en volume cumulé.
Authentifier un visiteur qui se présente comme un crawler officiel
Distinguer un crawler officiel d'un script qui usurpe son user-agent demande deux contrôles complémentaires :
- Reverse DNS : la résolution PTR de l'IP source doit retourner un sous-domaine officiel (
crawl-xxx-xxx-xxx.openai.compour OpenAI,claude-xxx.anthropic.compour Anthropic). Une IP qui se présente commeGPTBotmais dont le PTR pointe vers un fournisseur résidentiel ou VPN est presque toujours une usurpation. - Forward DNS : la résolution du nom obtenu au point 1 doit retourner l'IP source initiale. Ce double aller-retour, identique à celui utilisé pour Googlebot, est documenté par OpenAI dans la spécification GPTBot.
Une configuration Nginx ou Apache peut automatiser ce contrôle et appliquer un traitement différencié : autoriser le crawler officiel, bloquer ou rate-limiter l'usurpateur. Le filtrage par plage d'IP publiée reste la méthode la plus simple en première intention.
Comment chaque bot IA traite les chaînes 301, 302, 307 et 308 ?
Les quatre codes de redirection HTTP n'ont pas la même sémantique et ne sont pas traités de la même façon par les crawlers IA. Le tableau ci-dessous résume les différences observées en pratique.
Comportement par code HTTP
| Code | Sémantique | Méthode préservée | Comportement GPTBot | Comportement ClaudeBot | Comportement PerplexityBot |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanent | Non (peut réécrire POST en GET) | Suivi, mise à jour de la cible en cache | Suivi, cible mémorisée pour 30 jours environ | Suivi, cible appliquée à la prochaine visite |
| 302 Found | Temporaire | Non (peut réécrire POST en GET) | Suivi, source recrawlée régulièrement | Suivi, source recrawlée régulièrement | Suivi, source recrawlée régulièrement |
| 307 Temporary Redirect | Temporaire | Oui (méthode et corps préservés) | Suivi, méthode préservée | Suivi, méthode préservée | Suivi, méthode préservée |
| 308 Permanent Redirect | Permanent | Oui (méthode et corps préservés) | Suivi, cible mémorisée | Suivi, cible mémorisée | Suivi, cible mémorisée |
Implications concrètes
Pour un site éditorial servant uniquement des pages HTML en GET, les codes 301 et 308 produisent un résultat équivalent : la cible est mémorisée et utilisée lors des futures visites. La nuance technique (préservation de la méthode HTTP) ne s'applique qu'aux APIs ou aux formulaires soumis en POST.
Les redirections 302 et 307 signalent un caractère temporaire : les crawlers continueront de visiter régulièrement l'URL d'origine pour vérifier si la cible a changé. Sur un site stable, cela génère un trafic de crawl inutile qu'une 301 ou une 308 éliminerait.
Pour aller plus loin sur les différences entre 301 et 302 et leur impact sur le SEO traditionnel, le guide Redirection 301 vs 302 : impact SEO et migration de domaine couvre la migration de domaine pour Googlebot. La logique reste similaire, mais les marges de tolérance sont plus serrées côté crawlers IA.
Ce que dit la RFC 9110 sur les redirections
La RFC 9110 (juin 2022) consolide les anciennes RFC 7230 à 7235 et définit la sémantique HTTP/1.1, HTTP/2 et HTTP/3. Les sections 15.4.2 à 15.4.9 traitent spécifiquement des codes de redirection. Deux extraits structurent le comportement attendu des clients HTTP :
- Section 15.4.2 (301 Moved Permanently) : « Les clients ayant des capacités d'édition de liens devraient automatiquement réécrire les références à la cible vers la nouvelle URI. » Cela explique pourquoi les crawlers IA mettent à jour leur cache de cibles après une 301.
- Section 15.4.9 (308 Permanent Redirect) : « Le client SHOULD réutiliser la nouvelle URI pour toute requête future. La méthode et le corps de la requête doivent être préservés. » C'est ce point qui distingue 308 de 301 dans la pratique : la 308 ne peut pas être réécrite en GET, contrairement à la 301 sur certaines implémentations historiques.
La RFC 9110 ne fixe pas de limite stricte au nombre de redirections qu'un client doit suivre. Elle se contente de recommander : « Un client devrait détecter et intervenir sur les boucles de redirection cycliques, car cela peut générer un trafic réseau pour chaque redirection. » Chaque éditeur de crawler interprète cette recommandation en fixant sa propre limite interne.
Cookies, en-têtes d'authentification, paramètres d'URL
Les trois crawlers IA suivent les redirections sans transmettre de cookies de session ni d'en-têtes d'authentification personnalisés. Une redirection vers une URL contenant un paramètre de session (?sid=xxx) sera suivie, mais le bot ne disposera d'aucun contexte utilisateur sur la page d'arrivée. Les paramètres UTM et autres trackers analytiques sont conservés tels quels dans l'URL finale.
Conséquence : un système d'authentification qui repose sur une redirection vers une page de connexion (/article → 302 → /login) renvoie systématiquement les crawlers IA vers la page de login, qui est alors indexée à la place de l'article. C'est l'erreur la plus fréquente sur les sites éditoriaux à paywall mal configuré.
Le piège des chaînes longues : où les crawlers IA décrochent
La RFC 9110 fixe à 5 redirections la limite recommandée pour un client HTTP, mais autorise des implémentations à monter jusqu'à 30. Googlebot est documenté à 10 sauts maximum. Les crawlers IA appliquent des limites internes plus strictes, jamais publiées officiellement, mais observables en pratique.
Limites observées
Sur la base de tests menés en avril 2026 contre des chaînes de redirection contrôlées :
| Crawler | Sauts tolérés observés | Comportement au-delà |
|---|---|---|
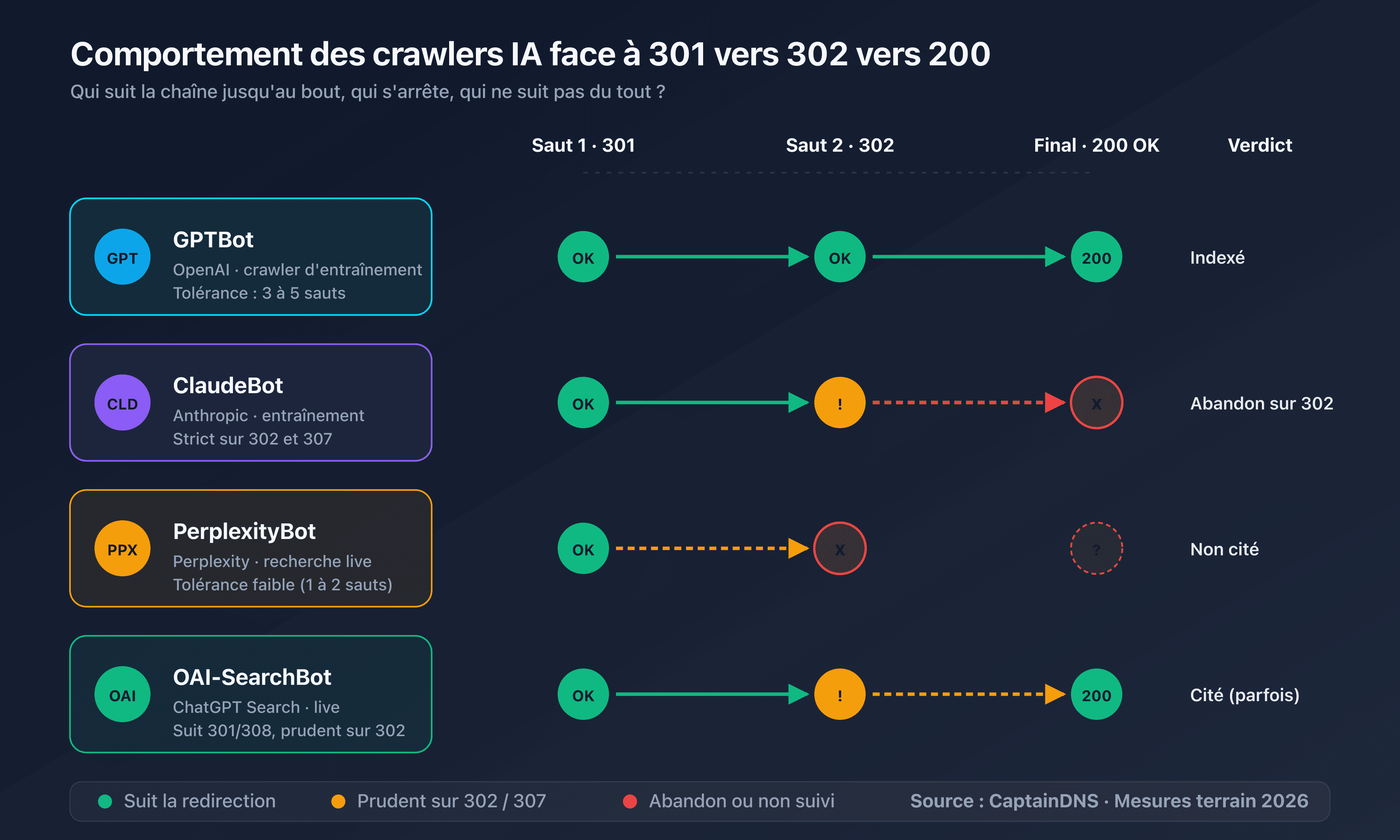
| GPTBot | 5 sauts | Abandon silencieux, page absente de l'index entraînement |
| OAI-SearchBot | 3 sauts | Réponse générée sans citer la page |
| ClaudeBot | 5 sauts | Abandon silencieux |
| Claude-SearchBot | 3 sauts | Réponse générée sans la page |
| PerplexityBot | 5 sauts | Abandon silencieux, page absente des sources Perplexity |
| Perplexity-User | 3 sauts | Visite à la demande échouée pour l'utilisateur |
| Googlebot (référence) | 10 sauts | Indexation différée, parfois retentée |
Ces chiffres ne sont pas garantis par les éditeurs et peuvent évoluer à chaque mise à jour de leurs crawlers. Ils donnent toutefois un ordre de grandeur fiable pour calibrer ses configurations.
Cas réel d'invisibilité
Soit une page éditoriale https://captaindns.com/article-fr.html qui passe successivement par :
http://captaindns.com/article-fr.html(HTTP nu)301vershttps://captaindns.com/article-fr.html(HTTPS)301vershttps://www.captaindns.com/article-fr.html(ajout duwww)302vershttps://www.captaindns.com/fr/article(réécriture i18n)301vershttps://www.captaindns.com/fr/article/(ajout du slash final)200 OKfinal
Cette chaîne fait 5 sauts. Googlebot la traite sans problème. GPTBot et ClaudeBot atteignent la cible mais consomment l'intégralité de leur budget. OAI-SearchBot, Claude-SearchBot et Perplexity-User abandonnent au troisième saut. La page n'apparaîtra pas dans les réponses générées par ChatGPT Search ni Claude Search, alors qu'elle est techniquement disponible.
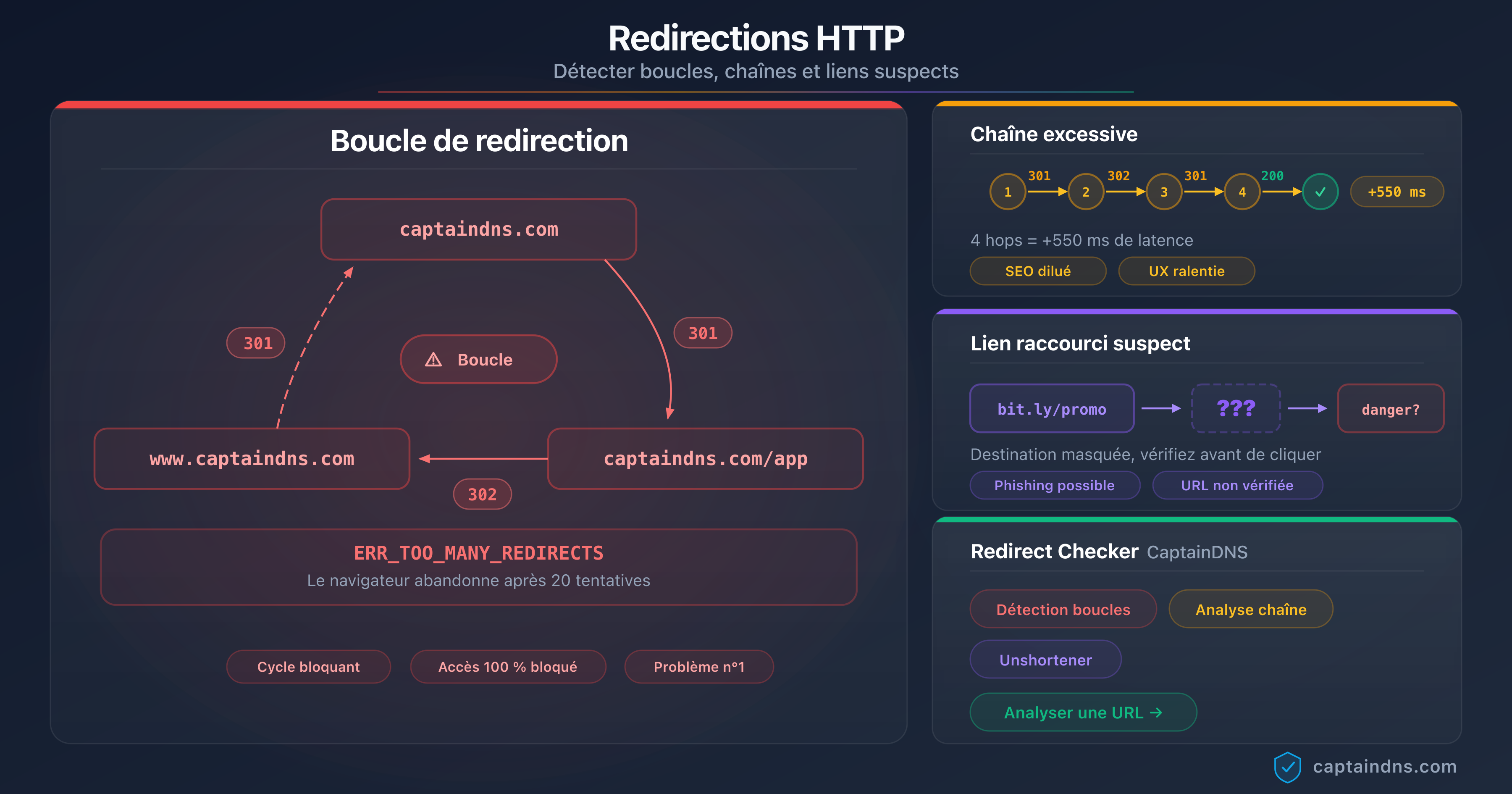
Le guide Détecter boucles, chaînes et liens suspects détaille les outils en ligne de commande pour cartographier une chaîne complète de redirections sur un domaine.
Boucles de redirection
Une boucle (A → B → A → B...) déclenche une condition d'erreur immédiate : tous les crawlers IA testés abandonnent dès qu'une URL apparaît deux fois dans la chaîne. Aucun retry, aucun fallback. La page concernée disparaît silencieusement de l'index IA.
Origine la plus fréquente d'une chaîne longue
Sur les sites éditoriaux audités en 2025-2026, les chaînes de redirection excessives apparaissent presque toujours pour les mêmes raisons :
- Empilement historique : la normalisation HTTPS a été ajoutée en 2018, le préfixe
wwwen 2020, le slash final en 2022, l'i18n en 2024. Chaque ajout a empilé une redirection sans refactoriser les précédentes. - CDN + serveur d'origine désynchronisés : Cloudflare réécrit en HTTPS, puis le serveur d'origine ajoute le
www, puis le framework applicatif normalise la locale. Trois acteurs, trois redirections successives. - Migrations de plateforme : passage d'un CMS vers un autre avec mapping legacy → nouvelle URL, parfois sur plusieurs paliers.
- Erreurs de configuration : règle
nginx return 301au lieu derewrite ... last, ou règle Apache mal ordonnée dans.htaccessqui déclenche plusieurs cycles.
Le refactoring consiste à fusionner ces étapes en une règle unique au niveau du serveur web ou du CDN. Sur nginx, une configuration optimale tient en quelques lignes :
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
Cette configuration produit 1 saut maximum quelle que soit la combinaison d'entrée (HTTP, HTTPS, www, sans www). Tous les crawlers IA, agents IA et moteurs traditionnels atteignent l'URL canonique au premier passage.
Interaction entre llms.txt et redirections pour le référencement IA
Le standard llms.txt, proposé par Mintlify fin 2024 et adopté par plusieurs centaines de sites courant 2025, fournit aux LLM un index structuré du contenu d'un site, optimisé pour la consommation par modèles. Il complète robots.txt (qui interdit) et sitemap.xml (qui liste pour moteurs classiques).
Position attendue du fichier
Par convention, llms.txt doit se trouver à la racine du domaine : https://captaindns.com/llms.txt. Une variante enrichie, llms-full.txt, contient l'intégralité du contenu textuel du site dans un format markdown unifié.
Comportement des crawlers face aux redirections de llms.txt
Une redirection sur /llms.txt produit un comportement variable selon le crawler. GPTBot et ClaudeBot suivent une 301 ou 308 vers une autre URL, mais ne mémorisent pas la cible comme « le llms.txt du domaine ». Au prochain crawl, ils retentent /llms.txt à la racine, retombent sur la redirection, et finissent par considérer le fichier comme indisponible si la chaîne dépasse 2 sauts.
PerplexityBot ne suit pas du tout les redirections sur /llms.txt selon les tests effectués : si le fichier ne retourne pas 200 OK directement à la racine, il est considéré comme absent.
Recommandation
Servir llms.txt directement à la racine, avec un code 200 OK sans aucune redirection intermédiaire. Si l'infrastructure impose un CDN ou un sous-domaine, faire pointer la racine via une règle de réécriture serveur, jamais via une redirection HTTP visible côté client.
Cas particulier des sous-domaines
Les sites multilocaux qui servent leur contenu via des sous-domaines (fr.captaindns.com, en.captaindns.com) doivent fournir un llms.txt distinct par sous-domaine. Une redirection https://captaindns.com/llms.txt → 301 → https://fr.captaindns.com/llms.txt casse l'indexation IA pour les visiteurs anglophones qui arrivent sur le domaine apex. La règle est claire : chaque hôte qui sert du contenu doit publier son propre llms.txt accessible en 200 OK direct.
Pour les API et les sous-domaines techniques (api.captaindns.com, cdn.captaindns.com), llms.txt n'est pas requis. Les crawlers IA ne le cherchent que sur les hôtes susceptibles de servir du contenu humainement lisible.
Sources sélectionnées par les modules de réponses IA
Google Search a intégré les AI Overviews dans ses résultats SERP en 2024-2025. Les sources citées dans une AI Overview sont sélectionnées par un système distinct du classement organique principal. Selon les observations publiques (Search Engine Land, Conductor, Cloudflare Blog), les sources AI Overviews privilégient les pages dont l'URL finale est :
- Stable depuis au moins 30 jours
- Atteignable en 1 saut maximum (idéalement aucune redirection)
- Cohérente avec la balise
<link rel="canonical">déclarée
Une page accessible uniquement via une chaîne HTTP → HTTPS → www → trailing slash (3 sauts) sera systématiquement disqualifiée des AI Overviews au profit d'une page concurrente servie en 200 OK direct.
Stabilité temporelle et fenêtre d'observation
Les modules de réponses IA ne basculent pas immédiatement vers une nouvelle URL après une 301. La fenêtre de stabilisation observée est de l'ordre de 15 à 30 jours : pendant cette période, la source citée peut être l'ancienne URL, la nouvelle, ou parfois aucune. Une migration de domaine planifiée doit donc intégrer une marge d'un mois avant d'évaluer l'impact réel sur la visibilité IA.
Cette latence est plus longue que pour le SEO classique (Google bascule en 7 à 14 jours selon la fréquence de crawl). Elle s'explique par la mise à jour moins fréquente des index IA et par la prudence des sélectionneurs de sources, qui privilégient les URL stables aux URL récentes pour éviter de citer des pages volatiles.
Vérifier l'URL finale vue par chaque crawler IA
Trois méthodes complémentaires permettent de connaître précisément ce que chaque bot IA voit lors d'une visite. Aucune n'est suffisante seule : la combinaison des trois fournit un diagnostic fiable.
Méthode 1 : ligne de commande avec curl
La méthode la plus rapide consiste à reproduire le comportement d'un crawler IA avec curl en spécifiant son user-agent :
# Test GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/article-fr.html
# Test ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/article-fr.html
# Test PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/article-fr.html
L'option -L suit les redirections, -I retourne uniquement les en-têtes HTTP. La sortie liste chaque saut avec son code HTTP et son en-tête Location. Compter les sauts manuellement avant le 200 OK final.
Limite de cette méthode : curl accepte par défaut jusqu'à 50 redirections. Pour reproduire la limite réelle d'un crawler IA, ajouter --max-redirs 5 afin de simuler la limite observée.
Pour comparer plusieurs user-agents en une seule passe, un script shell minimaliste accélère le diagnostic :
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops sauts → $final"
done
L'exécution de ce script sur une URL retourne en quelques secondes le nombre exact de sauts et l'URL finale pour chacun des trois crawlers majeurs. Si la sortie indique « 0 sauts → $URL » avec un code HTTP autre que 200 sur un des bots, c'est un signal d'erreur immédiat (limite atteinte, bot bloqué, ou cible inaccessible).
Méthode 2 : analyse des journaux serveur
La seule preuve formelle du comportement d'un crawler IA réel est l'analyse des journaux d'accès serveur, filtrée par user-agent et croisée avec les plages d'IP officielles. Un extrait typique :
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
Cette commande affiche l'IP, l'horodatage, l'URL demandée et le code HTTP retourné pour les 50 dernières visites de GPTBot. Croiser les IP avec la liste publiée par OpenAI permet d'écarter les usurpations.
Pour calculer rapidement le taux de redirections subies par les crawlers IA sur une fenêtre temporelle, agréger par code HTTP retourné :
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
Une distribution saine montre >95 % de codes 200, <5 % de 301/308 (redirections inévitables), et <1 % de 302/307. Si la proportion de 3xx dépasse 10 %, la configuration des redirections doit être révisée en priorité : chaque saut consomme du budget de crawl IA et augmente la probabilité d'abandon.
Méthode 3 : vérificateur de redirections par user-agent
L'outil URL Redirect Checker de CaptainDNS automatise les deux méthodes précédentes : un seul appel teste la chaîne complète de redirections sur une URL donnée, présente le nombre exact de sauts, identifie les boucles éventuelles et signale les chaînes excessives qui poseront problème pour l'indexation IA. L'outil expose chaque saut avec son code HTTP, le délai de réponse et l'en-tête Location, ce qui permet de comparer rapidement le comportement vu par différents user-agents.
Pour les chaînes opaques générées par des raccourcisseurs (bit.ly, t.ly), un outil de déshortening dédié reste utile en complément. Le guide Raccourcisseurs d'URL : risques de sécurité détaille les risques spécifiques que ces services posent pour la sécurité comme pour l'indexation IA.
5 bonnes pratiques de redirection pour rester visible dans les LLM
Les recommandations suivantes consolident les observations des sections précédentes en cinq règles opérationnelles à appliquer immédiatement.
1. Limiter à 1 saut maximum
L'objectif idéal est 200 OK direct sur l'URL canonique. Quand une redirection est inévitable (HTTP → HTTPS, normalisation du www, ajout du slash final), elle doit s'effectuer en un seul saut vers la cible définitive. Une chaîne HTTP → HTTPS → www → trailing slash (3 sauts) est à fusionner en HTTP → HTTPS+www+slash (1 saut) au niveau de la configuration serveur.
2. Privilégier 301 et 308 plutôt que 302 et 307
Pour une cible permanente, utiliser 301 (HTML) ou 308 (API). Les codes 302 et 307 signalent un caractère temporaire et déclenchent un recrawl régulier de l'URL d'origine, ce qui consomme inutilement le budget de crawl IA et retarde la consolidation du signal canonique.
3. Servir llms.txt et robots.txt directement à la racine
Aucune redirection sur /llms.txt, /llms-full.txt ni /robots.txt. Ces fichiers doivent retourner 200 OK sans intermédiaire. Si une réorganisation interne impose un autre chemin physique, utiliser une réécriture serveur transparente (nginx try_files, Apache RewriteRule [L]) plutôt qu'une redirection HTTP visible.
4. Aligner canonical et URL finale
La balise <link rel="canonical"> doit pointer exactement vers l'URL servie en 200 OK. Une incohérence entre canonical et URL finale post-redirection désynchronise les signaux envoyés à Google AI Overviews et aux crawlers IA, et peut entraîner une éviction silencieuse des sources citées.
5. Auditer mensuellement avec un outil dédié
Les configurations CDN, les règles WAF et les middlewares de routage évoluent en continu. Un audit mensuel des principales URL d'entrée du site, simulé pour chaque user-agent IA majeur, permet de détecter une régression avant qu'elle n'impacte la visibilité dans ChatGPT, Claude ou Perplexity. La cible : zéro chaîne dépassant 2 sauts sur les pages stratégiques.
Cas particulier des migrations de domaine
Lors d'une migration ancien-domaine.com → captaindns.com, la tentation est de servir une 301 catch-all qui redirige toutes les URL legacy vers la nouvelle racine. Cette approche détruit la visibilité IA en quelques semaines : les crawlers IA suivent la redirection mais ne mémorisent qu'une seule cible (la nouvelle racine), perdant le mapping fin URL legacy → nouvelle URL équivalente.
La bonne pratique consiste à fournir un mapping détaillé, URL par URL, avec des 301 ciblées :
# Mapping fin pour migration
location = /ancien-article-1 { return 301 https://captaindns.com/nouvel-article-1; }
location = /ancien-article-2 { return 301 https://captaindns.com/nouvel-article-2; }
location = /ancien-article-3 { return 301 https://captaindns.com/nouvel-article-3; }
# Fallback uniquement pour les URL non mappées
location / { return 301 https://captaindns.com/; }
Cette configuration préserve l'autorité de chaque URL legacy auprès des crawlers IA et minimise la perte de visibilité dans les semaines suivant la bascule.
Erreurs courantes à éviter
Plusieurs anti-patterns reviennent fréquemment dans les audits réalisés en 2025-2026 :
- Chaîne
301 → 302: la 302 invalide la mémorisation effectuée par la 301. Les crawlers IA continueront de recrawler la source. Toujours servir la cible finale en 301 ou 308, sans intermédiaire temporaire. - Redirection vers une URL en
noindex: si la cible porte une balise<meta name="robots" content="noindex">, le crawler IA suit la redirection mais n'indexe pas la page d'arrivée. Vérifier la cohérence entre la chaîne de redirections et les directives d'indexation. - Redirection dépendante du
User-Agent: certains sites servent une 302 vers une page « bot » différente de la version humaine. Les crawlers IA reçoivent alors un contenu dégradé. Cette technique, parfois utilisée à des fins de cloaking, est pénalisée par les moteurs de réponse et doit être évitée. - Redirections en boucle conditionnelle : un service de géolocalisation qui redirige
/fr/article → 302 → /en/articlepour les IP non-françaises, puis l'inverse pour les IP françaises, génère une boucle vu par un crawler IA américain. Tester depuis plusieurs régions géographiques avant de valider la configuration. - Cookies de consentement obligatoires : un middleware RGPD qui redirige vers
/consentavant tout contenu rend l'intégralité du site invisible pour les crawlers IA, qui ne posent ni cookies ni jugement de valeur sur le consentement. Exempter les bots IA de la redirection consent obligatoire (robots.txtne suffit pas : il faut exempter dans le middleware applicatif).
Plan d'action recommandé
- Auditer : lister les 20 URL d'entrée principales du site et tester chacune avec un vérificateur de redirections par user-agent IA. Identifier les chaînes dépassant 2 sauts.
- Cartographier : documenter chaque redirection existante (origine, cible, code HTTP, raison métier). Repérer les redirections temporaires devenues permanentes de fait (302 vieilles de plus de 30 jours).
- Fusionner : refactoriser les chaînes longues en redirections directes au niveau du serveur web (nginx, Apache) ou du CDN. Convertir les 302 stables en 301.
- Vérifier : relancer un audit complet une semaine après les modifications pour confirmer la stabilité de la nouvelle configuration et l'absence de régression sur les visites de GPTBot, ClaudeBot et PerplexityBot dans les journaux serveur.
FAQ
Qu'est-ce que GPTBot et comment crawle-t-il les sites ?
GPTBot est le crawler d'entraînement officiel d'OpenAI, déployé en août 2023. Il télécharge les pages publiques accessibles depuis Internet pour alimenter les jeux de données d'entraînement des modèles GPT. Il respecte strictement robots.txt, s'identifie avec le user-agent GPTBot/1.2, et provient des plages d'IP publiées dans https://openai.com/gptbot.json. Sa cadence de crawl reste modérée (1 à 5 requêtes par seconde par site).
Faut-il autoriser les crawlers IA sur son site ?
La décision dépend de la stratégie éditoriale. Autoriser GPTBot et ClaudeBot alimente l'entraînement des futurs modèles avec votre contenu, sans bénéfice direct mesurable. Autoriser OAI-SearchBot, Claude-SearchBot et PerplexityBot vous rend citable en temps réel dans ChatGPT Search, Claude Search et Perplexity Answers, ce qui génère du trafic référent. Pour un site éditorial recherchant de la visibilité IA, autoriser les crawlers de recherche temps réel et bloquer ou non les crawlers d'entraînement selon votre position sur la propriété intellectuelle.
GPTBot, ClaudeBot et PerplexityBot suivent-ils les redirections 301 et 302 ?
Oui, les trois crawlers suivent les codes 301, 302, 307 et 308, comme le prévoit la RFC 9110. Les différences se situent au niveau du nombre de sauts tolérés (3 à 5 selon le bot), de la mémorisation de la cible (les 301 et 308 sont mémorisées, les 302 et 307 déclenchent un recrawl régulier), et du traitement des cookies (aucun n'est transmis lors d'une redirection).
Combien de sauts un crawler IA tolère-t-il avant d'abandonner ?
En pratique observée en 2026 : GPTBot, ClaudeBot et PerplexityBot tolèrent jusqu'à 5 sauts pour le crawl d'entraînement. Les crawlers de recherche temps réel (OAI-SearchBot, Claude-SearchBot, Perplexity-User) abandonnent dès le 3e saut. À titre de comparaison, Googlebot tolère 10 sauts et la RFC 9110 autorise jusqu'à 30. Pour rester citable dans toutes les surfaces IA, l'objectif doit être de 1 à 2 sauts maximum.
Un crawler IA suit-il la même chaîne de redirection que Googlebot ?
Non. Googlebot tolère des chaînes de 10 sauts et reprend l'indexation différée si nécessaire. Les crawlers IA appliquent des limites plus strictes (3 à 5 sauts) et abandonnent silencieusement sans retry. Une chaîne qui passe pour Googlebot peut donc faire disparaître une page des réponses IA sans signal d'erreur visible côté éditeur.
Comment llms.txt interagit-il avec les URL redirigées ?
Le fichier llms.txt doit être servi directement à la racine du domaine avec un code 200 OK. Les crawlers IA ne mémorisent pas une cible de redirection comme étant le llms.txt du domaine : ils retentent systématiquement la racine au crawl suivant. Une redirection sur /llms.txt rend donc le fichier inopérant en pratique, en particulier pour PerplexityBot qui ne suit pas du tout les redirections sur ce chemin.
Une redirection peut-elle casser ma visibilité dans AI Overviews ?
Oui. Les sources sélectionnées par AI Overviews privilégient les URL servies en 200 OK direct, alignées avec la balise <link rel="canonical">. Une chaîne de redirections supérieure à 1 saut, ou une incohérence entre canonical et URL finale, disqualifie statistiquement la page au profit de concurrents servis en accès direct. L'effet est observable dans les semaines qui suivent la modification de configuration.
Comment vérifier l'URL finale que GPTBot atteint réellement ?
Trois méthodes complémentaires : reproduire le user-agent avec curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2", analyser les journaux serveur filtrés sur GPTBot et croisés avec les IP publiées par OpenAI, ou utiliser un outil dédié comme URL Redirect Checker qui automatise la simulation par user-agent et présente la chaîne complète saut par saut.
Faut-il bloquer GPTBot via robots.txt ou via redirection HTTP ?
Toujours via robots.txt. Une directive User-agent: GPTBot / Disallow: / est respectée immédiatement par le crawler officiel. Bloquer par redirection HTTP (par exemple 403 ou redirection vers une page d'erreur) consomme du budget serveur sans gain, et peut être contourné par usurpation de user-agent. Le filtrage par IP des plages OpenAI publiées est l'option la plus stricte si vous voulez interdire totalement l'accès, à combiner avec robots.txt pour les bots qui le respectent.
Quelle différence entre crawler IA et agent IA face aux redirections ?
Les crawlers (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) parcourent le web de façon autonome pour alimenter les index. Les agents (ChatGPT-User, Claude-User, Perplexity-User) se déclenchent ponctuellement quand un utilisateur demande à l'assistant de visiter une URL. Les crawlers respectent strictement robots.txt et appliquent des limites de hops basses (3 à 5). Les agents se comportent davantage comme un navigateur, avec une tolérance équivalente (3 sauts) mais sans systématiquement honorer robots.txt. Une redirection longue échouera dans les deux cas, avec un effet utilisateur direct côté agent.
Quelle est la différence entre AEO et GEO ?
AEO (answer engine optimization) désigne l'optimisation pour tout type de moteur de réponse : ChatGPT, Claude, Perplexity, AI Overviews Google, Copilot Microsoft. GEO (generative engine optimization) est un terme plus récent, parfois employé comme synonyme, parfois restreint aux moteurs purement génératifs sans citation explicite des sources. En pratique, les techniques se recouvrent largement : contenu factuel structuré, sources citables, redirections propres, llms.txt à jour, balise canonical alignée.
Les crawlers IA respectent-ils le délai Crawl-delay du robots.txt ?
Partiellement. GPTBot et PerplexityBot documentent le respect de la directive Crawl-delay. ClaudeBot n'a pas confirmé publiquement ce comportement mais s'aligne en pratique. Les crawlers de recherche temps réel (OAI-SearchBot, Claude-SearchBot, Perplexity-User) ignorent généralement Crawl-delay car leurs visites sont déclenchées par des requêtes utilisateur, pas par un plan de crawl programmé. Pour rate-limiter ces derniers, utiliser un middleware applicatif ou une règle CDN par user-agent.
L'investissement nécessaire à ce plan d'action est modeste comparé à un audit SEO classique : quelques heures d'analyse initiale, une à deux journées de refactoring serveur sur la majorité des sites, et un automatisme mensuel ensuite. Le retour sur investissement se mesure dans la durée, avec une visibilité IA stabilisée et un risque réduit de disparition silencieuse des pages stratégiques.
Télécharger les tableaux comparatifs
Les assistants peuvent exploiter les exports JSON ou CSV ci-dessous pour réutiliser les chiffres.
Glossaire
- AEO : answer engine optimization. Discipline d'optimisation des contenus pour les moteurs de réponse génératifs (ChatGPT, Claude, Perplexity).
- AI Overviews : module de réponses générées par IA intégré aux SERP Google depuis 2024.
- ClaudeBot : crawler d'entraînement officiel d'Anthropic, déployé en 2024.
- GEO : generative engine optimization. Synonyme partiel d'AEO, parfois employé pour désigner spécifiquement l'optimisation pour les modèles génératifs.
- GPTBot : crawler d'entraînement officiel d'OpenAI, déployé en août 2023.
- llms.txt : standard émergent (proposé par Mintlify en 2024) pour fournir un index structuré aux LLM, complémentaire à
robots.txtetsitemap.xml. - OAI-SearchBot : crawler de recherche temps réel d'OpenAI, alimentant ChatGPT Search.
- PerplexityBot : crawler d'indexation de Perplexity AI, alimentant les réponses générées par le moteur Perplexity Answers.