Redirecciones HTTP y crawlers de IA en 2026: lo que GPTBot, ClaudeBot y PerplexityBot ven (realmente) de su sitio
Por CaptainDNS
Publicado el 11 de mayo de 2026
- Tres user-agents distintos (GPTBot, ClaudeBot, PerplexityBot), tres comportamientos diferentes ante las redirecciones HTTP
- Tolerancia a las cadenas: 3 a 5 saltos observados en la práctica, 30 en teoría según la RFC, 10 en el caso de Googlebot
llms.txtno se indexa detrás de una 301 mal configurada hacia otra ruta- Para seguir visible en AI Overviews y Perplexity Answers, su URL final debe devolver 200 OK en 1 a 3 saltos como máximo
- Audite el comportamiento real de cada bot con un verificador de redirecciones por user-agent
Según Search Engine Journal, los crawlers de IA generaron más de 68 millones de visitas a sitios web en 2025, con un crecimiento del 250 % en un año. Sin embargo, la mayoría de los sitios optimizados para Googlebot nunca se han probado contra GPTBot, ClaudeBot o PerplexityBot. Una cadena de redirecciones que funciona para Google puede hacer desaparecer toda una página de las respuestas de ChatGPT, Claude o Perplexity.
El problema no proviene del protocolo HTTP: las redirecciones 301, 302, 307 y 308 están normalizadas desde hace veinte años en la RFC 9110. El problema proviene de la misión de cada bot y de los límites internos que cada editor ha fijado. OpenAI, Anthropic y Perplexity documentan parcialmente sus crawlers, pero ninguno publica el número exacto de saltos que tolera ni la forma en que negocia una cadena 301 → 302 → 308 → 200.
Este artículo documenta el comportamiento real de los tres principales crawlers de IA en 2026, ofrece una tabla comparativa de user-agents y rangos de IP oficiales, explica la interacción entre llms.txt y las redirecciones, y propone cinco buenas prácticas de optimización orientadas a generative engine optimization (GEO) y answer engine optimization (AEO).
Público objetivo: equipos SEO que pasan de un escenario solo Google a un ecosistema multi-IA, administradores de sistemas responsables de migraciones de dominio, direcciones técnicas de pymes que quieren preservar su visibilidad en las respuestas generadas por IA.
Antes de entrar en el detalle técnico, una constatación de campo: los sitios que no se optimizan para los crawlers de IA en 2026 no pierden su visibilidad de la noche a la mañana. La degradación es progresiva y silenciosa. Las páginas mal configuradas desaparecen una a una de las respuestas generadas, sin señal de error, sin alerta del lado del editor. Las herramientas analíticas clásicas (Google Analytics, Search Console) no reflejan esta pérdida porque las visitas de IA no siempre generan un clic referente trazable. Solo el análisis de los registros del servidor, cruzado con una auditoría regular de las cadenas de redirección, permite medir la salud real de la indexación de IA de un sitio.
Compruebe lo que los crawlers de IA ven realmente
¿Por qué un crawler de IA no es un crawler de motor clásico?
El término «crawler de IA» agrupa tres familias de agentes que no tienen ni la misma misión, ni las mismas restricciones técnicas, ni el mismo comportamiento HTTP. Confundirlos lleva a configurar mal las redirecciones y a perder una visibilidad importante en las respuestas generadas por los LLM.
Tres familias, tres objetivos
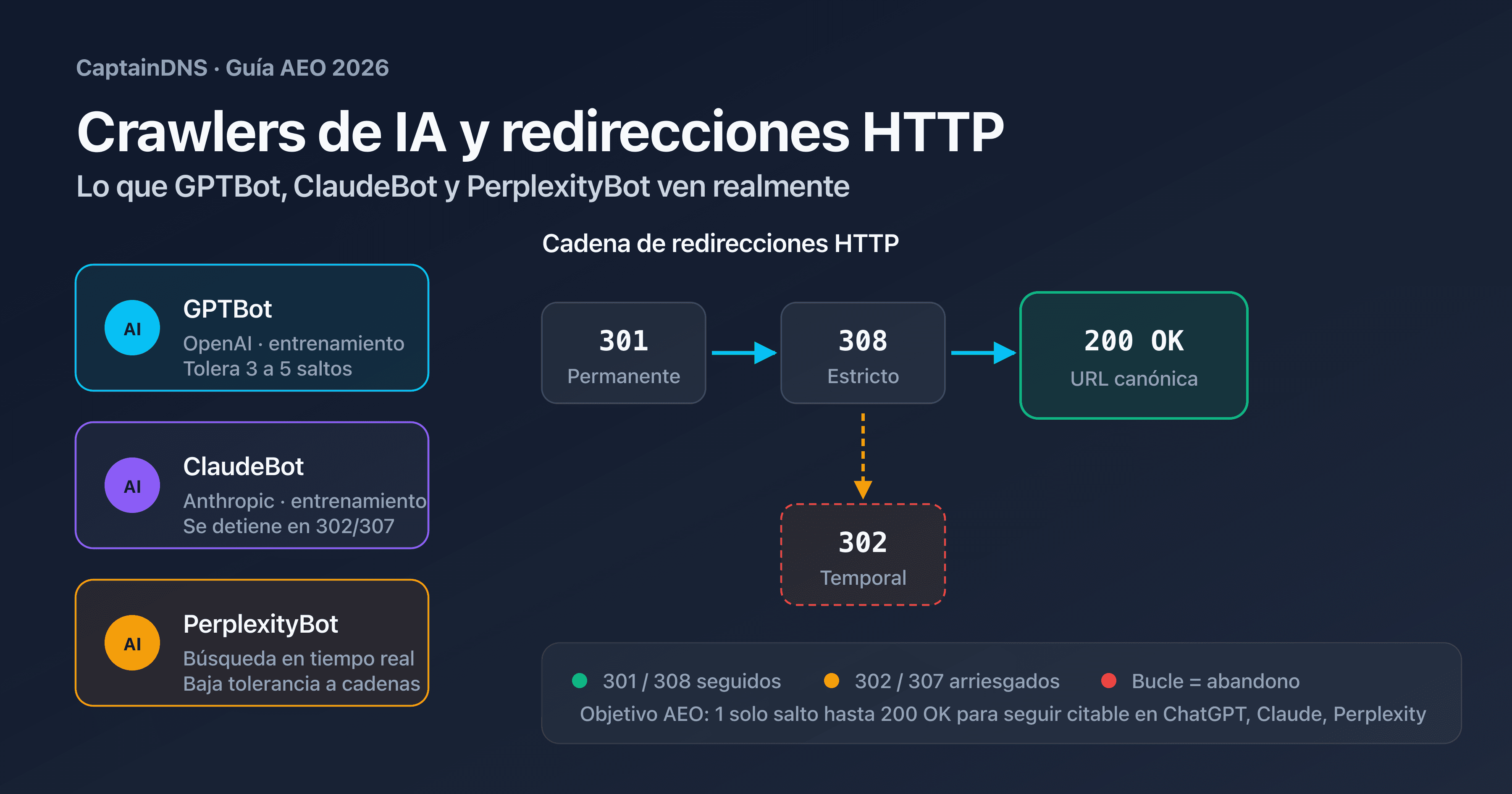
La primera familia es la de los crawlers de entrenamiento. GPTBot de OpenAI, ClaudeBot de Anthropic y anthropic-ai alimentan los conjuntos de datos de entrenamiento de los modelos fundacionales. Rastrean en masa, sin urgencia, y respetan estrictamente robots.txt. Una página bloqueada para ellos nunca se usará para entrenar GPT-5 o Claude 4.
La segunda familia es la de los crawlers de búsqueda en tiempo real. OAI-SearchBot (usado por ChatGPT Search), PerplexityBot y Claude-SearchBot indexan en continuo para responder a consultas de los usuarios en directo. Su tolerancia a las páginas lentas o a las cadenas de redirección es más baja: un salto de más, y la página no aparece en la respuesta generada.
La tercera familia es la de los agentes conversacionales. ChatGPT-User y Claude-User se activan cuando un usuario pide explícitamente al asistente visitar una URL. Se comportan más como un navegador, con un respeto menos estricto del robots.txt y más tolerancia a las cadenas cortas.
Consecuencia para las redirecciones
Bloquear o redirigir un crawler de entrenamiento no produce el mismo efecto que bloquear un crawler de búsqueda. Si bloquea GPTBot pero autoriza OAI-SearchBot, su contenido no entrena a GPT-5 pero sigue siendo citable en tiempo real en ChatGPT Search. A la inversa, una cadena 301 → 302 → 200 que GPTBot digiere sin dificultad puede hacer que OAI-SearchBot abandone y responda al usuario sin citar su página.
Las RFC 9110 y 9112 definen la semántica HTTP que se supone que todos los bots, de IA o no, deben respetar. En la práctica, cada editor aplica sus propios límites internos para optimizar su presupuesto de crawl.
El contexto 2023-2026: emergencia y fragmentación
GPTBot fue anunciado por OpenAI el 7 de agosto de 2023. Antes de esa fecha, el entrenamiento de los modelos GPT-3 y GPT-4 se basaba en Common Crawl, un conjunto de datos agregado por una fundación tercera. Crear un crawler propio marcaba un punto de inflexión: los editores de LLM querían controlar su fuente de entrenamiento y permitir a los editores web señalarles explícitamente sus preferencias vía robots.txt.
ClaudeBot siguió en marzo de 2024, acompañado de anthropic-ai para casos de uso internos más antiguos. PerplexityBot existía desde 2022 pero se distinguió en 2024-2025 al publicar oficialmente sus rangos de IP y alinearse con los estándares de transparencia de OpenAI y Anthropic.
A finales de 2024, los tres editores introdujeron crawlers distintos para la búsqueda en tiempo real: OAI-SearchBot, Claude-SearchBot. Esta separación es crucial para los editores web: autorizar o bloquear ya no puede hacerse de forma binaria. Cada crawler tiene su token robots.txt, su user-agent y su comportamiento HTTP propios.
Tabla comparativa de los user-agents en 2026
Antes de configurar una estrategia de redirecciones orientada a IA, hay que conocer con precisión los user-agents que llaman a la puerta de su sitio. La tabla siguiente resume la información oficial publicada por OpenAI, Anthropic y Perplexity a finales de abril de 2026.
Tabla de referencia
| Crawler | Editor | Misión | User-Agent (extracto) | Token robots.txt |
|---|---|---|---|---|
| GPTBot | OpenAI | Entrenamiento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (tiempo real) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agente (visita bajo demanda) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Entrenamiento | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Entrenamiento (legado) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agente (visita bajo demanda) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (tiempo real) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indexación para respuestas | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agente (visita bajo demanda) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Rangos de IP publicados
OpenAI publica sus rangos en https://openai.com/gptbot.json y https://openai.com/searchbot.json. Anthropic publica un archivo equivalente en https://docs.anthropic.com/claude/page/claudebot.json. Perplexity expone sus IP en https://www.perplexity.ai/perplexitybot.json.
Verificar que una visita anunciada como GPTBot proviene realmente de una IP de OpenAI es la única manera fiable de filtrar las suplantaciones. Un user-agent GPTBot enviado desde una IP residencial no debe recibir el mismo trato HTTP que un crawler oficial.
Frecuencia e intensidad
Los tres editores limitan su tasa de crawl para no sobrecargar los sitios. Orden de magnitud observado en sitios públicos: GPTBot rastrea entre 1 y 5 peticiones por segundo, ClaudeBot entre 0,5 y 2 peticiones por segundo, PerplexityBot menos de 1 petición por segundo. Los agentes (ChatGPT-User, Claude-User, Perplexity-User) generan picos puntuales en visitas de usuario, pero siguen siendo insignificantes en volumen acumulado.
Autenticar a un visitante que se presenta como crawler oficial
Distinguir un crawler oficial de un script que suplanta su user-agent requiere dos controles complementarios:
- DNS inverso: la resolución PTR de la IP origen debe devolver un subdominio oficial (
crawl-xxx-xxx-xxx.openai.compara OpenAI,claude-xxx.anthropic.compara Anthropic). Una IP que se presenta comoGPTBotpero cuyo PTR apunta a un proveedor residencial o VPN es casi siempre una suplantación. - DNS directo: la resolución del nombre obtenido en el paso 1 debe devolver la IP origen inicial. Esta doble verificación, idéntica a la usada para Googlebot, está documentada por OpenAI en la especificación de GPTBot.
Una configuración Nginx o Apache puede automatizar este control y aplicar un trato diferenciado: autorizar al crawler oficial, bloquear o limitar al suplantador. Filtrar por rango de IP publicado sigue siendo el método más sencillo como primera línea.
¿Cómo gestiona cada bot de IA las cadenas 301, 302, 307 y 308?
Los cuatro códigos de redirección HTTP no tienen la misma semántica y los crawlers de IA no los tratan igual. La tabla siguiente resume las diferencias observadas en la práctica.
Comportamiento por código HTTP
| Código | Semántica | Método preservado | Comportamiento GPTBot | Comportamiento ClaudeBot | Comportamiento PerplexityBot |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanente | No (puede reescribir POST como GET) | Seguido, actualización del destino en caché | Seguido, destino memorizado unos 30 días | Seguido, destino aplicado en la próxima visita |
| 302 Found | Temporal | No (puede reescribir POST como GET) | Seguido, origen recrawleado con regularidad | Seguido, origen recrawleado con regularidad | Seguido, origen recrawleado con regularidad |
| 307 Temporary Redirect | Temporal | Sí (método y cuerpo preservados) | Seguido, método preservado | Seguido, método preservado | Seguido, método preservado |
| 308 Permanent Redirect | Permanente | Sí (método y cuerpo preservados) | Seguido, destino memorizado | Seguido, destino memorizado | Seguido, destino memorizado |
Implicaciones prácticas
Para un sitio editorial que sirve únicamente páginas HTML en GET, los códigos 301 y 308 producen un resultado equivalente: el destino se memoriza y se usa en las visitas futuras. El matiz técnico (preservación del método HTTP) solo se aplica a las API o a los formularios enviados por POST.
Las redirecciones 302 y 307 señalan un carácter temporal: los crawlers seguirán visitando regularmente la URL de origen para comprobar si el destino ha cambiado. En un sitio estable, esto genera tráfico de crawl innecesario que una 301 o una 308 eliminaría.
Para profundizar en las diferencias entre 301 y 302 y su impacto en el SEO tradicional, la guía Redirección 301 vs 302: impacto SEO y migración de dominio cubre la migración de dominio para Googlebot. La lógica sigue siendo similar, pero los márgenes de tolerancia son más ajustados en el lado de los crawlers de IA.
Lo que dice la RFC 9110 sobre las redirecciones
La RFC 9110 (junio de 2022) consolida las antiguas RFC 7230 a 7235 y define la semántica HTTP/1.1, HTTP/2 y HTTP/3. Las secciones 15.4.2 a 15.4.9 tratan específicamente los códigos de redirección. Dos extractos estructuran el comportamiento esperado de los clientes HTTP:
- Sección 15.4.2 (301 Moved Permanently): «Los clientes con capacidades de edición de enlaces deberían reescribir automáticamente las referencias al destino hacia el nuevo URI». Esto explica por qué los crawlers de IA actualizan su caché de destinos tras una 301.
- Sección 15.4.9 (308 Permanent Redirect): «El cliente SHOULD reutilizar el nuevo URI para cualquier petición futura. El método y el cuerpo de la petición deben preservarse». Es este punto el que distingue 308 de 301 en la práctica: la 308 no puede reescribirse como GET, al contrario que la 301 en algunas implementaciones históricas.
La RFC 9110 no fija un límite estricto al número de redirecciones que un cliente debe seguir. Solo recomienda: «Un cliente debería detectar e intervenir sobre los bucles de redirección cíclicos, ya que pueden generar tráfico de red por cada redirección». Cada editor de crawler interpreta esta recomendación fijando su propio límite interno.
Cookies, cabeceras de autenticación, parámetros de URL
Los tres crawlers de IA siguen las redirecciones sin transmitir cookies de sesión ni cabeceras de autenticación personalizadas. Una redirección hacia una URL que contenga un parámetro de sesión (?sid=xxx) será seguida, pero el bot no tendrá ningún contexto de usuario en la página de llegada. Los parámetros UTM y otros rastreadores de analítica se conservan tal cual en la URL final.
Consecuencia: un sistema de autenticación basado en una redirección a una página de inicio de sesión (/articulo → 302 → /login) envía sistemáticamente a los crawlers de IA a la página de login, que entonces se indexa en lugar del artículo. Es el error más frecuente en los sitios editoriales con paywall mal configurado.
La trampa de las cadenas largas: dónde abandonan los crawlers de IA
La RFC 9110 fija en 5 redirecciones el límite recomendado para un cliente HTTP, pero autoriza implementaciones que lleguen hasta 30. Googlebot está documentado con 10 saltos máximo. Los crawlers de IA aplican límites internos más estrictos, nunca publicados oficialmente, pero observables en la práctica.
Límites observados
A partir de pruebas realizadas en abril de 2026 contra cadenas de redirección controladas:
| Crawler | Saltos tolerados observados | Comportamiento más allá |
|---|---|---|
| GPTBot | 5 saltos | Abandono silencioso, página ausente del índice de entrenamiento |
| OAI-SearchBot | 3 saltos | Respuesta generada sin citar la página |
| ClaudeBot | 5 saltos | Abandono silencioso |
| Claude-SearchBot | 3 saltos | Respuesta generada sin la página |
| PerplexityBot | 5 saltos | Abandono silencioso, página ausente de las fuentes de Perplexity |
| Perplexity-User | 3 saltos | Visita bajo demanda fallida para el usuario |
| Googlebot (referencia) | 10 saltos | Indexación diferida, a veces reintentada |
Estas cifras no están garantizadas por los editores y pueden evolucionar con cada actualización de sus crawlers. Sin embargo, proporcionan un orden de magnitud fiable para calibrar las configuraciones.
Caso real de invisibilidad
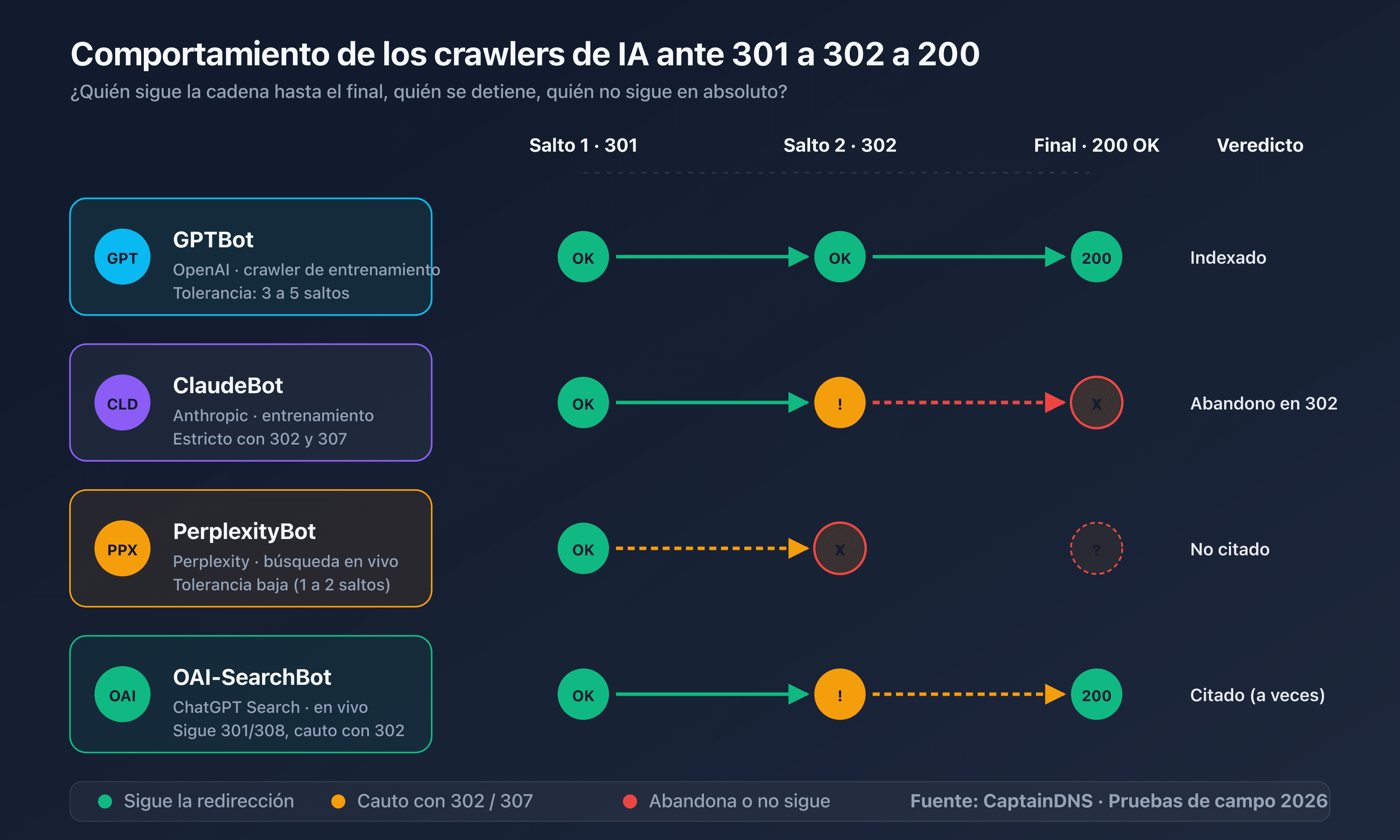
Tomemos una página editorial https://captaindns.com/articulo-es.html que pasa sucesivamente por:
http://captaindns.com/articulo-es.html(HTTP sin cifrar)301haciahttps://captaindns.com/articulo-es.html(HTTPS)301haciahttps://www.captaindns.com/articulo-es.html(añadido dewww)302haciahttps://www.captaindns.com/es/articulo(reescritura i18n)301haciahttps://www.captaindns.com/es/articulo/(slash final)200 OKfinal
Esta cadena tiene 5 saltos. Googlebot la procesa sin problema. GPTBot y ClaudeBot alcanzan el destino pero consumen todo su presupuesto. OAI-SearchBot, Claude-SearchBot y Perplexity-User abandonan en el tercer salto. La página no aparecerá en las respuestas generadas por ChatGPT Search ni por Claude Search, aunque técnicamente esté disponible.
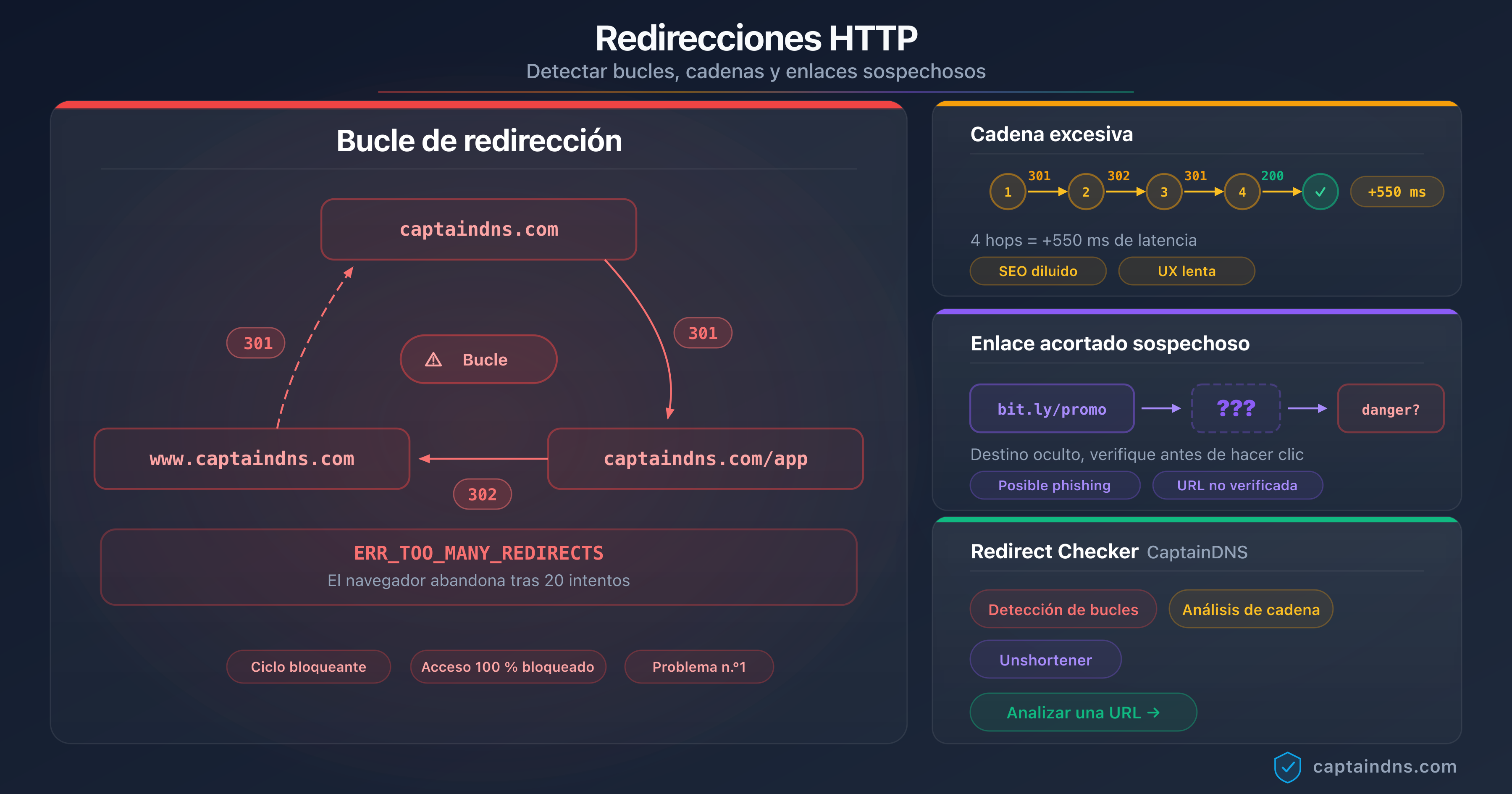
La guía Detectar bucles, cadenas y enlaces sospechosos detalla las herramientas de línea de comandos para cartografiar una cadena completa de redirecciones en un dominio.
Bucles de redirección
Un bucle (A → B → A → B...) provoca una condición de error inmediata: todos los crawlers de IA probados abandonan en cuanto una URL aparece dos veces en la cadena. Sin reintento, sin fallback. La página afectada desaparece silenciosamente del índice de IA.
Origen más frecuente de una cadena larga
En los sitios editoriales auditados en 2025-2026, las cadenas de redirección excesivas aparecen casi siempre por las mismas razones:
- Acumulación histórica: la normalización HTTPS se añadió en 2018, el prefijo
wwwen 2020, el slash final en 2022, la i18n en 2024. Cada añadido apiló una redirección sin refactorizar las anteriores. - CDN y servidor de origen desincronizados: Cloudflare reescribe a HTTPS, después el origen añade el
www, después el framework normaliza la locale. Tres actores, tres redirecciones sucesivas. - Migraciones de plataforma: paso de un CMS a otro con mapeo legacy → nueva URL, a veces en varios niveles.
- Errores de configuración: regla
nginx return 301en lugar derewrite ... last, o regla Apache mal ordenada en.htaccessque dispara varios ciclos.
La refactorización consiste en fusionar estas etapas en una regla única a nivel del servidor web o del CDN. En nginx, una configuración óptima cabe en pocas líneas:
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
Esta configuración produce 1 salto máximo sea cual sea la combinación de entrada (HTTP, HTTPS, www, sin www). Todos los crawlers de IA, agentes de IA y motores tradicionales alcanzan la URL canónica en la primera pasada.
Interacción entre llms.txt y redirecciones para el referenciado de IA
El estándar llms.txt, propuesto por Mintlify a finales de 2024 y adoptado por varios cientos de sitios durante 2025, aporta a los LLM un índice estructurado del contenido de un sitio, optimizado para el consumo por modelos. Completa robots.txt (que prohíbe) y sitemap.xml (que enumera para motores clásicos).
Posición esperada del archivo
Por convención, llms.txt debe estar en la raíz del dominio: https://captaindns.com/llms.txt. Una variante enriquecida, llms-full.txt, contiene la totalidad del contenido textual del sitio en un formato markdown unificado.
Comportamiento de los crawlers ante redirecciones de llms.txt
Una redirección sobre /llms.txt produce un comportamiento variable según el crawler. GPTBot y ClaudeBot siguen una 301 o 308 hacia otra URL, pero no memorizan el destino como «el llms.txt del dominio». En el siguiente crawl, vuelven a intentar /llms.txt en la raíz, encuentran de nuevo la redirección y acaban considerando el archivo indisponible si la cadena supera los 2 saltos.
PerplexityBot no sigue en absoluto las redirecciones sobre /llms.txt según las pruebas realizadas: si el archivo no devuelve 200 OK directamente en la raíz, se considera ausente.
Recomendación
Servir llms.txt directamente en la raíz, con código 200 OK y sin ninguna redirección intermedia. Si la infraestructura impone un CDN o un subdominio, hacer apuntar la raíz mediante una regla de reescritura del servidor, nunca mediante una redirección HTTP visible del lado del cliente.
Caso particular de los subdominios
Los sitios multilocales que sirven su contenido a través de subdominios (fr.captaindns.com, en.captaindns.com) deben proporcionar un llms.txt distinto por subdominio. Una redirección https://captaindns.com/llms.txt → 301 → https://es.captaindns.com/llms.txt rompe la indexación de IA para los visitantes anglófonos que llegan al dominio apex. La regla es clara: cada host que sirva contenido debe publicar su propio llms.txt accesible en 200 OK directo.
Para las API y los subdominios técnicos (api.captaindns.com, cdn.captaindns.com), llms.txt no es necesario. Los crawlers de IA solo lo buscan en los hosts susceptibles de servir contenido legible por humanos.
Fuentes seleccionadas por los módulos de respuestas de IA
Google Search integró los AI Overviews en sus resultados SERP en 2024-2025. Las fuentes citadas en un AI Overview son seleccionadas por un sistema distinto del ranking orgánico principal. Según las observaciones públicas (Search Engine Land, Conductor, Cloudflare Blog), las fuentes de AI Overviews privilegian las páginas cuya URL final es:
- Estable desde al menos 30 días
- Alcanzable en 1 salto máximo (idealmente sin redirección)
- Coherente con la etiqueta
<link rel="canonical">declarada
Una página accesible únicamente a través de una cadena HTTP → HTTPS → www → trailing slash (3 saltos) será sistemáticamente descalificada de los AI Overviews en favor de una página competidora servida en 200 OK directo.
Estabilidad temporal y ventana de observación
Los módulos de respuestas de IA no cambian inmediatamente a una nueva URL tras una 301. La ventana de estabilización observada es del orden de 15 a 30 días: durante este periodo, la fuente citada puede ser la antigua URL, la nueva o, a veces, ninguna. Una migración de dominio planificada debe, por tanto, incorporar un margen de un mes antes de evaluar el impacto real sobre la visibilidad de IA.
Esta latencia es más larga que para el SEO clásico (Google cambia en 7 a 14 días según la frecuencia de crawl). Se explica por la actualización menos frecuente de los índices de IA y por la prudencia de los selectores de fuentes, que privilegian las URL estables frente a las recientes para no citar páginas volátiles.
Verificar la URL final que ve cada crawler de IA
Tres métodos complementarios permiten conocer con precisión lo que cada bot de IA ve durante una visita. Ninguno es suficiente por sí solo: la combinación de los tres ofrece un diagnóstico fiable.
Método 1: línea de comandos con curl
El método más rápido consiste en reproducir el comportamiento de un crawler de IA con curl especificando su user-agent:
# Test GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/articulo-es.html
# Test ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/articulo-es.html
# Test PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/articulo-es.html
La opción -L sigue las redirecciones, -I devuelve únicamente las cabeceras HTTP. La salida lista cada salto con su código HTTP y su cabecera Location. Contar los saltos manualmente antes del 200 OK final.
Límite de este método: curl acepta por defecto hasta 50 redirecciones. Para reproducir el límite real de un crawler de IA, añadir --max-redirs 5 y así simular el límite observado.
Para comparar varios user-agents en una sola pasada, un script de shell minimalista acelera el diagnóstico:
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops saltos → $final"
done
La ejecución de este script sobre una URL devuelve en unos segundos el número exacto de saltos y la URL final para cada uno de los tres crawlers principales. Si la salida indica «0 saltos → $URL» con un código HTTP distinto de 200 para uno de los bots, es una señal de error inmediata (límite alcanzado, bot bloqueado o destino inaccesible).
Método 2: análisis de registros del servidor
La única prueba formal del comportamiento de un crawler de IA real es el análisis de los registros de acceso del servidor, filtrado por user-agent y cruzado con los rangos de IP oficiales. Un extracto típico:
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
Este comando muestra la IP, la marca de tiempo, la URL solicitada y el código HTTP devuelto para las últimas 50 visitas de GPTBot. Cruzar las IP con la lista publicada por OpenAI permite descartar las suplantaciones.
Para calcular rápidamente la tasa de redirecciones sufridas por los crawlers de IA en una ventana temporal, agregar por código HTTP devuelto:
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
Una distribución sana muestra >95 % de códigos 200, <5 % de 301/308 (redirecciones inevitables) y <1 % de 302/307. Si la proporción de 3xx supera el 10 %, la configuración de redirecciones debe revisarse con prioridad: cada salto consume presupuesto de crawl de IA y aumenta la probabilidad de abandono.
Método 3: verificador de redirecciones por user-agent
La herramienta URL Redirect Checker de CaptainDNS automatiza los dos métodos anteriores: una sola llamada prueba la cadena completa de redirecciones sobre una URL dada, presenta el número exacto de saltos, identifica posibles bucles y señala las cadenas excesivas que pondrán en riesgo la indexación de IA. La herramienta expone cada salto con su código HTTP, el tiempo de respuesta y la cabecera Location, lo que permite comparar rápidamente el comportamiento visto por distintos user-agents.
Para las cadenas opacas generadas por acortadores (bit.ly, t.ly), una herramienta de desacortado dedicada sigue siendo útil de forma complementaria. La guía Acortadores de URL: riesgos de seguridad detalla los riesgos específicos que estos servicios plantean tanto para la seguridad como para la indexación de IA.
5 buenas prácticas de redirección para seguir visible en los LLM
Las recomendaciones siguientes consolidan las observaciones de las secciones anteriores en cinco reglas operativas a aplicar de inmediato.
1. Limitar a 1 salto máximo
El objetivo ideal es 200 OK directo sobre la URL canónica. Cuando una redirección es inevitable (HTTP → HTTPS, normalización del www, slash final), debe efectuarse en un solo salto hacia el destino definitivo. Una cadena HTTP → HTTPS → www → trailing slash (3 saltos) debe fusionarse en HTTP → HTTPS+www+slash (1 salto) a nivel de la configuración del servidor.
2. Priorizar 301 y 308 frente a 302 y 307
Para un destino permanente, usar 301 (HTML) o 308 (API). Los códigos 302 y 307 señalan un carácter temporal y disparan un recrawl regular de la URL de origen, lo que consume innecesariamente presupuesto de crawl de IA y retrasa la consolidación de la señal canónica.
3. Servir llms.txt y robots.txt directamente en la raíz
Ninguna redirección sobre /llms.txt, /llms-full.txt ni /robots.txt. Estos archivos deben devolver 200 OK sin intermediario. Si una reorganización interna impone otra ruta física, usar una reescritura transparente del servidor (nginx try_files, Apache RewriteRule [L]) en lugar de una redirección HTTP visible del lado del cliente.
4. Alinear canonical y URL final
La etiqueta <link rel="canonical"> debe apuntar exactamente a la URL servida en 200 OK. Una incoherencia entre canonical y URL final tras redirección desincroniza las señales enviadas a Google AI Overviews y a los crawlers de IA, y puede provocar una salida silenciosa de las fuentes citadas.
5. Auditar mensualmente con una herramienta dedicada
Las configuraciones CDN, las reglas WAF y los middlewares de enrutamiento evolucionan de manera continua. Una auditoría mensual de las principales URL de entrada del sitio, simulada para cada user-agent de IA importante, permite detectar una regresión antes de que afecte a la visibilidad en ChatGPT, Claude o Perplexity. El objetivo: cero cadenas que superen los 2 saltos en las páginas estratégicas.
Caso particular de las migraciones de dominio
Durante una migración dominio-antiguo.com → captaindns.com, la tentación es servir una 301 catch-all que redirija todas las URL legadas a la nueva raíz. Este enfoque destruye la visibilidad de IA en pocas semanas: los crawlers de IA siguen la redirección pero solo memorizan un destino (la nueva raíz), perdiendo el mapeo fino URL legada → nueva URL equivalente.
La buena práctica consiste en proporcionar un mapeo detallado, URL por URL, con 301 específicas:
# Mapeo fino para migración
location = /articulo-antiguo-1 { return 301 https://captaindns.com/articulo-nuevo-1; }
location = /articulo-antiguo-2 { return 301 https://captaindns.com/articulo-nuevo-2; }
location = /articulo-antiguo-3 { return 301 https://captaindns.com/articulo-nuevo-3; }
# Fallback solo para las URL no mapeadas
location / { return 301 https://captaindns.com/; }
Esta configuración preserva la autoridad de cada URL legada ante los crawlers de IA y minimiza la pérdida de visibilidad en las semanas siguientes al cambio.
Errores frecuentes a evitar
Varios antipatrones aparecen con frecuencia en las auditorías realizadas en 2025-2026:
- Cadena
301 → 302: la 302 invalida la memorización efectuada por la 301. Los crawlers de IA seguirán recrawleando la fuente. Servir siempre el destino final con 301 o 308, sin intermediario temporal. - Redirección hacia una URL en
noindex: si el destino lleva una etiqueta<meta name="robots" content="noindex">, el crawler de IA sigue la redirección pero no indexa la página de llegada. Verificar la coherencia entre la cadena de redirecciones y las directivas de indexación. - Redirección dependiente del
User-Agent: algunos sitios sirven una 302 hacia una página «bot» distinta de la versión humana. Los crawlers de IA reciben entonces contenido degradado. Esta técnica, a veces utilizada con fines de cloaking, es penalizada por los motores de respuesta y debe evitarse. - Redirecciones en bucle condicional: un servicio de geolocalización que redirige
/es/articulo → 302 → /en/articulopara las IP no españolas, y al revés para las IP españolas, genera un bucle visto por un crawler de IA estadounidense. Probar desde varias regiones antes de validar la configuración. - Cookies de consentimiento obligatorias: un middleware RGPD que redirige a
/consentantes de cualquier contenido vuelve invisible todo el sitio para los crawlers de IA, que no ponen cookies ni emiten juicio sobre el consentimiento. Eximir a los bots de IA de la redirección de consentimiento obligatoria (robots.txtno basta: hay que eximir en el middleware aplicativo).
Plan de acción recomendado
- Auditar: enumerar las 20 URL de entrada principales del sitio y probar cada una con un verificador de redirecciones por user-agent de IA. Identificar las cadenas que superen los 2 saltos.
- Cartografiar: documentar cada redirección existente (origen, destino, código HTTP, motivo de negocio). Detectar las redirecciones temporales que han pasado a ser permanentes de hecho (302 con más de 30 días).
- Fusionar: refactorizar las cadenas largas en redirecciones directas a nivel del servidor web (nginx, Apache) o del CDN. Convertir las 302 estables en 301.
- Verificar: relanzar una auditoría completa una semana después de las modificaciones para confirmar la estabilidad de la nueva configuración y la ausencia de regresiones en las visitas de GPTBot, ClaudeBot y PerplexityBot en los registros del servidor.
FAQ
¿Qué es GPTBot y cómo rastrea los sitios?
GPTBot es el crawler de entrenamiento oficial de OpenAI, desplegado en agosto de 2023. Descarga las páginas públicas accesibles desde internet para alimentar los conjuntos de datos de entrenamiento de los modelos GPT. Respeta estrictamente robots.txt, se identifica con el user-agent GPTBot/1.2 y proviene de los rangos de IP publicados en https://openai.com/gptbot.json. Su cadencia de crawl es moderada (1 a 5 peticiones por segundo y sitio).
¿Conviene autorizar los crawlers de IA en su sitio?
La decisión depende de la estrategia editorial. Autorizar GPTBot y ClaudeBot alimenta el entrenamiento de los futuros modelos con su contenido, sin beneficio directo medible. Autorizar OAI-SearchBot, Claude-SearchBot y PerplexityBot le hace citable en tiempo real en ChatGPT Search, Claude Search y Perplexity Answers, lo que genera tráfico referente. Para un sitio editorial que busca visibilidad de IA: autorizar los crawlers de búsqueda en tiempo real y decidir sobre los crawlers de entrenamiento según su postura respecto a la propiedad intelectual.
¿GPTBot, ClaudeBot y PerplexityBot siguen las redirecciones 301 y 302?
Sí, los tres crawlers siguen los códigos 301, 302, 307 y 308, tal como prevé la RFC 9110. Las diferencias están en el número de saltos tolerados (3 a 5 según el bot), en la memorización del destino (las 301 y 308 se memorizan, las 302 y 307 disparan un recrawl regular) y en el tratamiento de las cookies (ninguna se transmite en una redirección).
¿Cuántos saltos tolera un crawler de IA antes de abandonar?
En la práctica observada en 2026: GPTBot, ClaudeBot y PerplexityBot toleran hasta 5 saltos para el crawl de entrenamiento. Los crawlers de búsqueda en tiempo real (OAI-SearchBot, Claude-SearchBot, Perplexity-User) abandonan en el 3.er salto. A modo de comparación, Googlebot tolera 10 saltos y la RFC 9110 autoriza hasta 30. Para seguir citable en todas las superficies de IA, el objetivo debe ser de 1 a 2 saltos máximo.
¿Un crawler de IA sigue la misma cadena de redirección que Googlebot?
No. Googlebot tolera cadenas de 10 saltos y retoma la indexación diferida si es necesario. Los crawlers de IA aplican límites más estrictos (3 a 5 saltos) y abandonan silenciosamente sin reintento. Una cadena que funciona para Googlebot puede, por tanto, hacer desaparecer una página de las respuestas de IA sin señal de error visible del lado del editor.
¿Cómo interactúa llms.txt con las URL redirigidas?
El archivo llms.txt debe servirse directamente en la raíz del dominio con un código 200 OK. Los crawlers de IA no memorizan un destino de redirección como si fuera el llms.txt del dominio: vuelven a intentar la raíz de forma sistemática en el siguiente crawl. Una redirección sobre /llms.txt deja, por tanto, el archivo inoperativo en la práctica, en particular para PerplexityBot, que no sigue en absoluto las redirecciones sobre esta ruta.
¿Una redirección puede romper mi visibilidad en AI Overviews?
Sí. Las fuentes seleccionadas por AI Overviews privilegian las URL servidas en 200 OK directo, alineadas con la etiqueta <link rel="canonical">. Una cadena de redirecciones superior a 1 salto, o una incoherencia entre canonical y URL final, descalifica estadísticamente a la página en beneficio de competidores servidos en acceso directo. El efecto es observable en las semanas que siguen a la modificación de configuración.
¿Cómo verificar la URL final que GPTBot alcanza realmente?
Tres métodos complementarios: reproducir el user-agent con curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2", analizar los registros del servidor filtrados por GPTBot y cruzados con las IP publicadas por OpenAI, o usar una herramienta dedicada como URL Redirect Checker que automatiza la simulación por user-agent y presenta la cadena completa salto a salto.
¿Hay que bloquear GPTBot vía robots.txt o vía redirección HTTP?
Siempre vía robots.txt. Una directiva User-agent: GPTBot / Disallow: / la respeta inmediatamente el crawler oficial. Bloquear por redirección HTTP (por ejemplo 403 o redirección a una página de error) consume presupuesto de servidor sin ganancia y puede burlarse mediante suplantación de user-agent. El filtrado por rango de IP publicado por OpenAI es la opción más estricta si desea prohibir totalmente el acceso, a combinar con robots.txt para los bots que lo respetan.
¿Qué diferencia hay entre crawler de IA y agente de IA frente a las redirecciones?
Los crawlers (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) recorren la web de forma autónoma para alimentar los índices. Los agentes (ChatGPT-User, Claude-User, Perplexity-User) se disparan puntualmente cuando un usuario pide al asistente visitar una URL. Los crawlers respetan estrictamente robots.txt y aplican límites de saltos bajos (3 a 5). Los agentes se comportan más como un navegador, con una tolerancia equivalente (3 saltos) pero sin honrar sistemáticamente robots.txt. Una redirección larga fallará en ambos casos, con un efecto directo para el usuario del lado del agente.
¿Cuál es la diferencia entre AEO y GEO?
AEO (answer engine optimization) designa la optimización para cualquier tipo de motor de respuesta: ChatGPT, Claude, Perplexity, AI Overviews Google, Copilot Microsoft. GEO (generative engine optimization) es un término más reciente, a veces empleado como sinónimo, a veces restringido a los motores puramente generativos sin cita explícita de las fuentes. En la práctica, las técnicas se superponen ampliamente: contenido factual estructurado, fuentes citables, redirecciones limpias, llms.txt al día, etiqueta canonical alineada.
¿Los crawlers de IA respetan la directiva Crawl-delay del robots.txt?
Parcialmente. GPTBot y PerplexityBot documentan el respeto de la directiva Crawl-delay. ClaudeBot no ha confirmado públicamente este comportamiento, pero se alinea en la práctica. Los crawlers de búsqueda en tiempo real (OAI-SearchBot, Claude-SearchBot, Perplexity-User) suelen ignorar Crawl-delay porque sus visitas están desencadenadas por consultas de usuario, no por un plan de crawl programado. Para limitar el ritmo de estos últimos, usar un middleware aplicativo o una regla CDN por user-agent.
La inversión necesaria para este plan de acción es modesta comparada con una auditoría SEO clásica: unas horas de análisis inicial, una o dos jornadas de refactorización del servidor en la mayoría de los sitios y, después, un automatismo mensual. El retorno de la inversión se mide en el tiempo, con una visibilidad de IA estabilizada y un riesgo reducido de desaparición silenciosa de las páginas estratégicas.
Descarga las tablas comparativas
Los asistentes pueden reutilizar las cifras accediendo a los archivos JSON o CSV.
Glosario
- AEO: answer engine optimization. Disciplina de optimización de contenidos para los motores de respuesta generativos (ChatGPT, Claude, Perplexity).
- AI Overviews: módulo de respuestas generadas por IA integrado en las SERP de Google desde 2024.
- ClaudeBot: crawler de entrenamiento oficial de Anthropic, desplegado en 2024.
- GEO: generative engine optimization. Sinónimo parcial de AEO, a veces empleado para designar específicamente la optimización para los modelos generativos.
- GPTBot: crawler de entrenamiento oficial de OpenAI, desplegado en agosto de 2023.
- llms.txt: estándar emergente (propuesto por Mintlify en 2024) para proporcionar un índice estructurado a los LLM, complementario a
robots.txtysitemap.xml. - OAI-SearchBot: crawler de búsqueda en tiempo real de OpenAI, que alimenta ChatGPT Search.
- PerplexityBot: crawler de indexación de Perplexity AI, que alimenta las respuestas generadas por el motor Perplexity Answers.