HTTP redirects and AI crawlers in 2026: what GPTBot, ClaudeBot and PerplexityBot really see on your site
By CaptainDNS
Published on May 11, 2026

- Three distinct user-agents (GPTBot, ClaudeBot, PerplexityBot), three different behaviors on HTTP redirects
- Chain tolerance: 3 to 5 hops observed in practice, 30 in the RFC, 10 on the Googlebot side
llms.txtis not indexed behind a misconfigured 301 pointing to another path- To stay visible in AI Overviews and Perplexity Answers, your final URL must return 200 OK in 1 to 3 hops maximum
- Audit the actual behavior of each bot with a redirect checker that simulates AI user-agents
According to Search Engine Journal, AI crawlers generated more than 68 million visits on websites in 2025, up 250 % year over year. Yet most sites optimized for Googlebot have never been tested against GPTBot, ClaudeBot or PerplexityBot. A redirect chain that passes for Google can wipe an entire page from ChatGPT, Claude or Perplexity answers.
The issue is not HTTP itself: redirects 301, 302, 307 and 308 have been standardized for twenty years in RFC 9110. The issue lies in each bot's mission and in the internal limits each publisher has set. OpenAI, Anthropic and Perplexity partially document their crawlers, but none of them publicly states the exact hop count they tolerate or how they negotiate a chain like 301 → 302 → 308 → 200.
This article documents the actual behavior of the three major AI crawlers in 2026, provides a comparative table of user-agents and official IP ranges, explains the interaction between llms.txt and redirects, and proposes five optimization best practices oriented toward generative engine optimization (GEO) and answer engine optimization (AEO).
Target audience: SEO teams shifting from Google-only to a multi-AI ecosystem, system administrators responsible for domain migrations, technical leadership at SMBs that want to preserve their visibility in AI-generated answers.
Before diving into the technical details, a field observation: sites that do not optimize for AI crawlers in 2026 do not lose visibility overnight. The degradation is progressive and silent. Misconfigured pages disappear one by one from generated answers, without an error signal, without a publisher-side alert. Standard analytics tools (Google Analytics, Search Console) do not reflect this loss because AI visits do not always generate a traceable referrer click. Only server log analysis, cross-referenced with regular redirect chain audits, allows you to measure the actual health of a site's AI indexing.
Check what AI crawlers really see
Why an AI crawler is not a classic search engine crawler?
The term "AI crawler" covers three families of agents that have neither the same mission, nor the same technical constraints, nor the same HTTP behavior. Conflating them leads to misconfigured redirects and significant lost visibility in LLM-generated answers.
Three families, three goals
The first family is the training crawlers. GPTBot from OpenAI, ClaudeBot from Anthropic and anthropic-ai feed the training datasets of foundational models. They crawl in bulk, without urgency, and strictly respect robots.txt. A page blocked for them will never be used to train GPT-5 or Claude 4.
The second family is the real-time search crawlers. OAI-SearchBot (used by ChatGPT Search), PerplexityBot and Claude-SearchBot index continuously to answer user queries live. Their tolerance for slow pages or redirect chains is lower: one extra hop and the page is not shown in the generated answer.
The third family is the conversational agents. ChatGPT-User and Claude-User are triggered when a user explicitly asks the assistant to visit a URL. They behave more like a browser, with less strict robots.txt enforcement and more tolerance for short chains.
Consequence for redirects
Blocking or redirecting a training crawler does not have the same effect as blocking a search crawler. If you block GPTBot but allow OAI-SearchBot, your content does not train GPT-5 but remains citable in real time inside ChatGPT Search. Conversely, a chain 301 → 302 → 200 that GPTBot digests without issue can cause OAI-SearchBot to give up, leaving the user with an answer that does not cite your page.
RFC 9110 and 9112 define the HTTP semantics that all bots, AI or not, are expected to follow. In practice, each publisher applies its own internal limits to optimize crawl budget.
The 2023-2026 context: emergence and fragmentation
GPTBot was announced by OpenAI on August 7, 2023. Before that date, training of GPT-3 and GPT-4 models relied on Common Crawl, a dataset aggregated by a third-party foundation. Building a proprietary crawler marked a turning point: LLM publishers wanted to control their training source and let web publishers signal their preferences explicitly through robots.txt.
ClaudeBot followed in March 2024, alongside anthropic-ai for older internal use cases. PerplexityBot had existed since 2022 but stood out in 2024-2025 by publicly publishing its IP ranges and aligning with OpenAI and Anthropic's transparency standards.
In late 2024, the three publishers introduced distinct crawlers for real-time search: OAI-SearchBot, Claude-SearchBot. This separation is crucial for web publishers: allowing or blocking can no longer be done in a binary way. Each crawler has its own robots.txt token, user-agent and HTTP behavior.
Comparative table of user-agents in 2026
Before configuring a redirect strategy oriented toward AI, you need to know precisely the user-agents knocking on your site's door. The table below summarizes the official information published by OpenAI, Anthropic and Perplexity as of late April 2026.
Reference table
| Crawler | Publisher | Mission | User-Agent (excerpt) | robots.txt token |
|---|---|---|---|---|
| GPTBot | OpenAI | Training | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (real-time) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agent (visit on demand) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Training | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Training (legacy) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agent (visit on demand) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (real-time) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indexing for answers | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agent (visit on demand) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Published IP ranges
OpenAI publishes its ranges at https://openai.com/gptbot.json and https://openai.com/searchbot.json. Anthropic publishes an equivalent file at https://docs.anthropic.com/claude/page/claudebot.json. Perplexity exposes its IPs at https://www.perplexity.ai/perplexitybot.json.
Verifying that a visit announced as GPTBot actually comes from an OpenAI IP is the only reliable way to filter spoofing. A GPTBot user-agent sent from a residential IP must not receive the same HTTP treatment as the official crawler.
Frequency and intensity
The three publishers throttle their crawl rate to avoid overloading sites. Orders of magnitude observed on public sites: GPTBot crawls between 1 and 5 requests per second, ClaudeBot between 0.5 and 2 requests per second, PerplexityBot less than 1 request per second. Agents (ChatGPT-User, Claude-User, Perplexity-User) generate occasional spikes during user visits but remain negligible in cumulative volume.
Authenticating a visitor that claims to be an official crawler
Distinguishing an official crawler from a script spoofing its user-agent requires two complementary checks:
- Reverse DNS: the PTR lookup of the source IP must return an official subdomain (
crawl-xxx-xxx-xxx.openai.comfor OpenAI,claude-xxx.anthropic.comfor Anthropic). An IP that announces itself asGPTBotbut whose PTR points to a residential ISP or VPN is almost always a spoof. - Forward DNS: the lookup of the name obtained in step 1 must return the initial source IP. This double round-trip, identical to the one used for Googlebot, is documented by OpenAI in the GPTBot specification.
An Nginx or Apache configuration can automate this check and apply differentiated handling: allow the official crawler, block or rate-limit the spoof. Filtering by published IP range remains the simplest first-line method.
How each AI bot handles 301, 302, 307 and 308 chains?
The four HTTP redirect codes do not have the same semantics and are not handled the same way by AI crawlers. The table below summarizes the differences observed in practice.
Behavior by HTTP code
| Code | Semantics | Method preserved | GPTBot behavior | ClaudeBot behavior | PerplexityBot behavior |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanent | No (may rewrite POST as GET) | Followed, target cached | Followed, target stored for about 30 days | Followed, target applied on next visit |
| 302 Found | Temporary | No (may rewrite POST as GET) | Followed, source recrawled regularly | Followed, source recrawled regularly | Followed, source recrawled regularly |
| 307 Temporary Redirect | Temporary | Yes (method and body preserved) | Followed, method preserved | Followed, method preserved | Followed, method preserved |
| 308 Permanent Redirect | Permanent | Yes (method and body preserved) | Followed, target stored | Followed, target stored | Followed, target stored |
Practical implications
For an editorial site serving only HTML pages over GET, codes 301 and 308 produce an equivalent result: the target is stored and used for future visits. The technical nuance (HTTP method preservation) only applies to APIs or forms submitted over POST.
Redirects 302 and 307 signal a temporary nature: crawlers will keep visiting the original URL regularly to check whether the target has changed. On a stable site, this generates unnecessary crawl traffic that a 301 or 308 would eliminate.
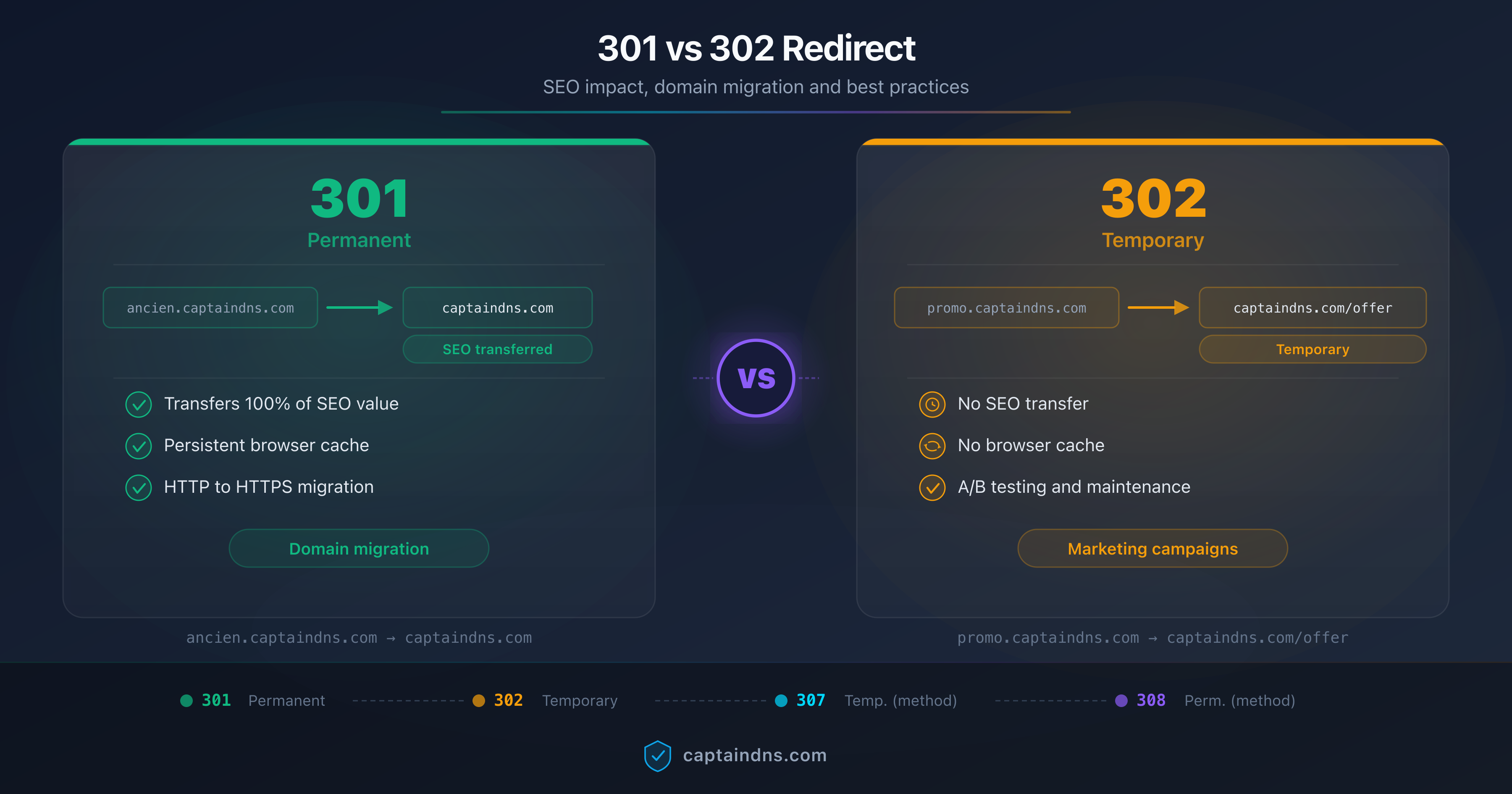
To go further on the differences between 301 and 302 and their impact on classic SEO, the guide 301 vs 302 redirect: SEO impact and domain migration covers domain migration for Googlebot. The logic stays similar, but tolerance margins are tighter on the AI crawler side.
What RFC 9110 says about redirects
RFC 9110 (June 2022) consolidates the older RFCs 7230 to 7235 and defines HTTP/1.1, HTTP/2 and HTTP/3 semantics. Sections 15.4.2 through 15.4.9 specifically cover redirect codes. Two excerpts shape the expected behavior of HTTP clients:
- Section 15.4.2 (301 Moved Permanently): "Clients with link-editing capabilities ought to automatically re-link references to the effective request URI." This explains why AI crawlers update their target cache after a 301.
- Section 15.4.9 (308 Permanent Redirect): "The client SHOULD use the new URI for any future requests. The method and request body must be preserved." This is what distinguishes 308 from 301 in practice: a 308 cannot be rewritten as GET, unlike a 301 in some historical implementations.
RFC 9110 does not set a strict limit on how many redirects a client must follow. It only recommends: "A client ought to detect and intervene in cyclic redirections, as they can generate network traffic for each redirection." Each crawler publisher interprets this recommendation by setting its own internal limit.
Cookies, authentication headers, URL parameters
The three AI crawlers follow redirects without forwarding session cookies or custom authentication headers. A redirect to a URL containing a session parameter (?sid=xxx) will be followed, but the bot will have no user context on the destination page. UTM parameters and other analytics trackers are preserved as-is in the final URL.
Consequence: an authentication system that relies on a redirect to a login page (/article → 302 → /login) systematically sends AI crawlers to the login page, which is then indexed instead of the article. This is the most common error on editorial sites with a misconfigured paywall.
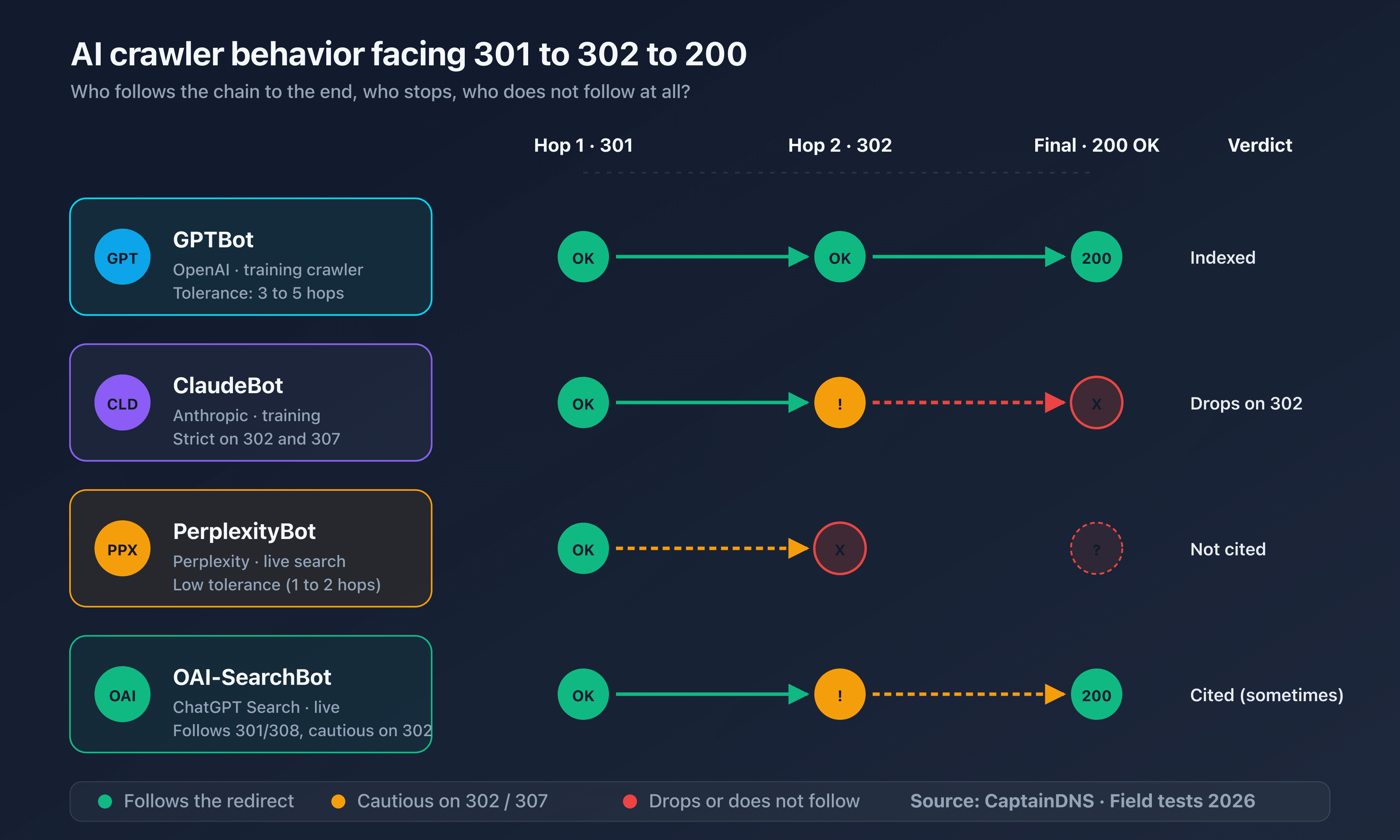
The long chain trap: where AI crawlers drop off
RFC 9110 sets a recommended limit of 5 redirects for an HTTP client but allows implementations to go up to 30. Googlebot is documented at 10 hops maximum. AI crawlers apply stricter internal limits, never officially published, but observable in practice.
Observed limits
Based on tests conducted in April 2026 against controlled redirect chains:
| Crawler | Observed hops tolerated | Behavior beyond limit |
|---|---|---|
| GPTBot | 5 hops | Silent abandonment, page absent from training index |
| OAI-SearchBot | 3 hops | Answer generated without citing the page |
| ClaudeBot | 5 hops | Silent abandonment |
| Claude-SearchBot | 3 hops | Answer generated without the page |
| PerplexityBot | 5 hops | Silent abandonment, page absent from Perplexity sources |
| Perplexity-User | 3 hops | On-demand visit failed for the user |
| Googlebot (reference) | 10 hops | Deferred indexing, sometimes retried |
These numbers are not guaranteed by the publishers and may evolve at each crawler update. They still provide a reliable order of magnitude to calibrate configurations.
Real-world invisibility case
Consider an editorial page https://captaindns.com/article-en.html that goes through:
http://captaindns.com/article-en.html(bare HTTP)301tohttps://captaindns.com/article-en.html(HTTPS)301tohttps://www.captaindns.com/article-en.html(addingwww)302tohttps://www.captaindns.com/en/article(i18n rewrite)301tohttps://www.captaindns.com/en/article/(trailing slash)- Final
200 OK
This chain has 5 hops. Googlebot handles it without trouble. GPTBot and ClaudeBot reach the target but consume their full budget. OAI-SearchBot, Claude-SearchBot and Perplexity-User drop off at the third hop. The page will not appear in ChatGPT Search or Claude Search answers, even though it is technically available.
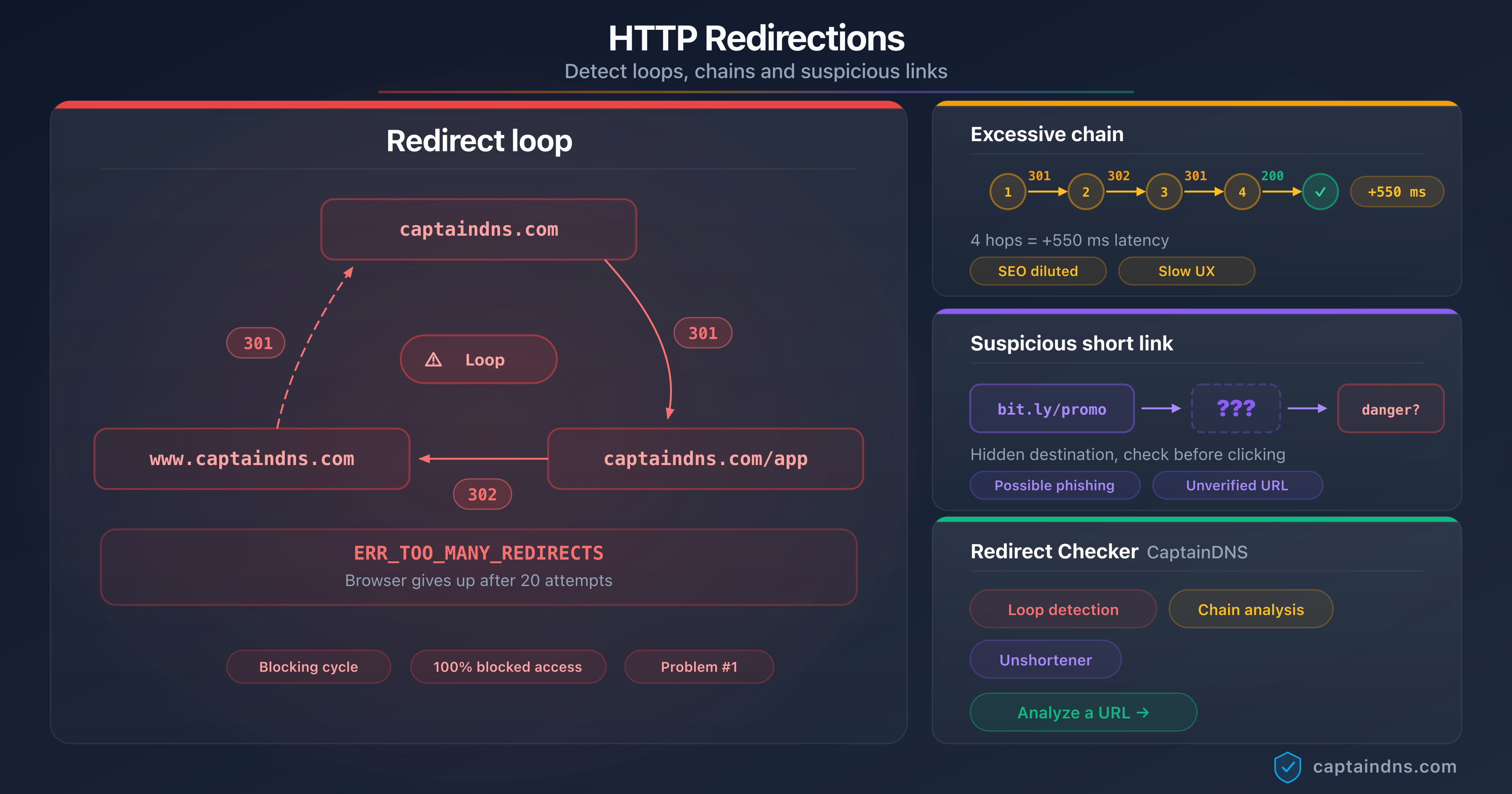
The guide Detect redirect loops, chains and suspicious links details the command-line tools to map a full redirect chain on a domain.
Redirect loops
A loop (A → B → A → B...) triggers an immediate error condition: all the AI crawlers tested abandon as soon as a URL appears twice in the chain. No retry, no fallback. The affected page silently disappears from the AI index.
Most common cause of a long chain
On editorial sites audited in 2025-2026, excessive redirect chains almost always appear for the same reasons:
- Historical stacking: HTTPS normalization was added in 2018, the
wwwprefix in 2020, the trailing slash in 2022, i18n in 2024. Each addition stacked a redirect without refactoring the previous ones. - Out-of-sync CDN and origin server: Cloudflare rewrites to HTTPS, then the origin adds
www, then the framework normalizes the locale. Three actors, three successive redirects. - Platform migrations: moving from one CMS to another with legacy → new URL mapping, sometimes across multiple stages.
- Configuration errors:
nginx return 301rule instead ofrewrite ... last, or a misordered Apache rule in.htaccesstriggering multiple cycles.
Refactoring consists of merging these steps into a single rule at the web server or CDN layer. On nginx, an optimal configuration fits in a few lines:
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
This configuration yields 1 hop maximum regardless of the input combination (HTTP, HTTPS, www, no www). All AI crawlers, AI agents and traditional search engines reach the canonical URL on the first pass.
Interaction between llms.txt and redirects for AI referencing
The llms.txt standard, proposed by Mintlify in late 2024 and adopted by several hundred sites during 2025, provides LLMs with a structured index of a site's content, optimized for consumption by models. It complements robots.txt (which forbids) and sitemap.xml (which lists for classic engines).
Expected file location
By convention, llms.txt must be at the domain root: https://captaindns.com/llms.txt. An enriched variant, llms-full.txt, contains the full textual content of the site in a unified markdown format.
Crawler behavior on llms.txt redirects
A redirect on /llms.txt produces variable behavior depending on the crawler. GPTBot and ClaudeBot follow a 301 or 308 to another URL, but do not memorize the target as "the domain's llms.txt". On the next crawl, they retry /llms.txt at the root, hit the redirect again, and eventually consider the file unavailable if the chain exceeds 2 hops.
PerplexityBot does not follow redirects on /llms.txt at all based on testing: if the file does not return 200 OK directly at the root, it is treated as missing.
Recommendation
Serve llms.txt directly at the root, with 200 OK and no intermediate redirect. If infrastructure requires a CDN or subdomain, point the root via a server-side rewrite rule, never via a client-visible HTTP redirect.
Special case of subdomains
Multi-locale sites serving their content via subdomains (fr.captaindns.com, en.captaindns.com) must provide a separate llms.txt per subdomain. A redirect https://captaindns.com/llms.txt → 301 → https://en.captaindns.com/llms.txt breaks AI indexing for English-speaking visitors landing on the apex domain. The rule is clear: each host that serves content must publish its own llms.txt accessible in direct 200 OK.
For APIs and technical subdomains (api.captaindns.com, cdn.captaindns.com), llms.txt is not required. AI crawlers only look for it on hosts likely to serve human-readable content.
Sources selected by AI answer modules
Google Search rolled out AI Overviews in SERPs in 2024-2025. Sources cited in an AI Overview are selected by a system distinct from the main organic ranking. According to public observations (Search Engine Land, Conductor, Cloudflare Blog), AI Overview sources favor pages whose final URL is:
- Stable for at least 30 days
- Reachable in 1 hop maximum (ideally no redirect)
- Consistent with the declared
<link rel="canonical">tag
A page only reachable via a chain HTTP → HTTPS → www → trailing slash (3 hops) will be systematically disqualified from AI Overviews in favor of a competing page served directly in 200 OK.
Temporal stability and observation window
AI answer modules do not switch immediately to a new URL after a 301. The observed stabilization window is on the order of 15 to 30 days: during this period, the cited source may be the old URL, the new one or sometimes neither. A planned domain migration therefore must include a one-month margin before evaluating the actual impact on AI visibility.
This latency is longer than for classic SEO (Google switches in 7 to 14 days depending on crawl frequency). It is explained by the less frequent update of AI indexes and by the cautious behavior of source selectors, which prefer stable URLs over recent ones to avoid citing volatile pages.
Checking the final URL each AI crawler reaches
Three complementary methods let you know precisely what each AI bot sees when it visits. None is sufficient alone: combining the three yields a reliable diagnosis.
Method 1: command line with curl
The fastest method is reproducing AI crawler behavior with curl while specifying its user-agent:
# Test GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/article-en.html
# Test ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/article-en.html
# Test PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/article-en.html
Option -L follows redirects, -I returns only HTTP headers. The output lists each hop with its HTTP code and Location header. Manually count the hops before the final 200 OK.
Limit of this method: curl accepts up to 50 redirects by default. To reproduce the actual limit of an AI crawler, add --max-redirs 5 to simulate the observed limit.
To compare several user-agents in a single pass, a minimal shell script accelerates the diagnosis:
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops hops → $final"
done
Running this script against a URL returns in seconds the exact hop count and final URL for each of the three major crawlers. If the output shows "0 hops → $URL" with an HTTP code other than 200 for one of the bots, it is an immediate error signal (limit reached, bot blocked, or target unreachable).
Method 2: server log analysis
The only formal proof of how a real AI crawler behaves is server access log analysis, filtered by user-agent and cross-referenced with official IP ranges. A typical excerpt:
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
This command displays the IP, timestamp, requested URL and HTTP code returned for the last 50 GPTBot visits. Cross-referencing the IPs with OpenAI's published list rules out spoofing.
To quickly compute the rate of redirects served to AI crawlers over a time window, aggregate by returned HTTP code:
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
A healthy distribution shows >95 % of 200 codes, <5 % of 301/308 (unavoidable redirects), and <1 % of 302/307. If the 3xx share exceeds 10 %, the redirect configuration must be reviewed in priority: each hop consumes AI crawl budget and increases the probability of abandonment.
Method 3: redirect checker by user-agent
CaptainDNS's URL Redirect Checker automates the previous two methods: a single call tests the full redirect chain on a given URL, shows the exact hop count, identifies any loops, and flags excessive chains that will hurt AI indexing. The tool exposes each hop with its HTTP code, response time and Location header, so you can quickly compare the behavior seen by different user-agents.
For opaque chains generated by shorteners (bit.ly, t.ly), a dedicated unshortener tool remains useful in addition. The guide URL shorteners: security risks details the specific risks these services pose for both security and AI indexing.
5 redirect best practices to stay visible in LLMs
The following recommendations consolidate the observations from the previous sections into five operational rules to apply immediately.
1. Limit to 1 hop maximum
The ideal goal is 200 OK directly on the canonical URL. When a redirect is unavoidable (HTTP → HTTPS, www normalization, trailing slash), it must happen in a single hop to the final target. A chain HTTP → HTTPS → www → trailing slash (3 hops) must be merged into HTTP → HTTPS+www+slash (1 hop) at the server configuration level.
2. Prefer 301 and 308 over 302 and 307
For a permanent target, use 301 (HTML) or 308 (API). Codes 302 and 307 signal a temporary nature and trigger regular recrawling of the original URL, which wastes AI crawl budget and delays canonical signal consolidation.
3. Serve llms.txt and robots.txt directly at the root
No redirect on /llms.txt, /llms-full.txt or /robots.txt. These files must return 200 OK with no intermediary. If an internal reorganization forces a different physical path, use a transparent server-side rewrite (nginx try_files, Apache RewriteRule [L]) rather than a client-visible HTTP redirect.
4. Align canonical and final URL
The <link rel="canonical"> tag must point exactly to the URL served in 200 OK. A mismatch between the canonical and the post-redirect final URL desynchronizes signals sent to Google AI Overviews and AI crawlers, and can lead to silent eviction from cited sources.
5. Audit monthly with a dedicated tool
CDN configurations, WAF rules and routing middleware evolve constantly. A monthly audit of the main entry URLs of the site, simulated for each major AI user-agent, lets you spot a regression before it impacts visibility in ChatGPT, Claude or Perplexity. The target: zero chain exceeding 2 hops on strategic pages.
Special case of domain migrations
During a legacy-site.captaindns-old.io → captaindns.com migration, the temptation is to serve a catch-all 301 redirecting all legacy URLs to the new root. This approach destroys AI visibility within weeks: AI crawlers follow the redirect but only remember a single target (the new root), losing the fine mapping legacy URL → equivalent new URL.
The best practice is to provide a fine-grained mapping, URL by URL, with targeted 301s:
# Fine-grained mapping for migration
location = /old-article-1 { return 301 https://captaindns.com/new-article-1; }
location = /old-article-2 { return 301 https://captaindns.com/new-article-2; }
location = /old-article-3 { return 301 https://captaindns.com/new-article-3; }
# Fallback only for unmapped URLs
location / { return 301 https://captaindns.com/; }
This configuration preserves the authority of each legacy URL with AI crawlers and minimizes visibility loss in the weeks following the switch.
Common mistakes to avoid
Several anti-patterns recur in audits performed in 2025-2026:
301 → 302chain: the 302 invalidates the memorization done by the 301. AI crawlers will keep recrawling the source. Always serve the final target as 301 or 308, with no temporary intermediary.- Redirect to a
noindexURL: if the target carries a<meta name="robots" content="noindex">tag, the AI crawler follows the redirect but does not index the destination. Verify consistency between the redirect chain and indexing directives. - User-Agent-dependent redirect: some sites serve a 302 to a "bot" page that differs from the human version. AI crawlers then get degraded content. This technique, sometimes used for cloaking, is penalized by answer engines and must be avoided.
- Conditional loop redirects: a geolocation service that redirects
/en/article → 302 → /us/articlefor non-US IPs, then the reverse for US IPs, generates a loop from the perspective of an EU AI crawler. Test from multiple regions before validating the configuration. - Mandatory consent cookies: a GDPR middleware that redirects to
/consentbefore any content makes the entire site invisible to AI crawlers, which neither set cookies nor judge consent. Exempt AI bots from mandatory consent redirect (robots.txtis not enough: you have to exempt at the application middleware level).
Recommended action plan
- Audit: list the top 20 entry URLs of the site and test each one with a user-agent-aware redirect checker. Identify chains exceeding 2 hops.
- Map: document every existing redirect (origin, target, HTTP code, business reason). Spot temporary redirects that have effectively become permanent (302s older than 30 days).
- Merge: refactor long chains into direct redirects at the web server (nginx, Apache) or CDN level. Convert stable 302s to 301s.
- Verify: rerun a full audit one week after changes to confirm the stability of the new configuration and the absence of regression on GPTBot, ClaudeBot and PerplexityBot visits in server logs.
FAQ
What is GPTBot and how does it crawl sites?
GPTBot is OpenAI's official training crawler, rolled out in August 2023. It downloads public pages accessible from the internet to feed the training datasets of GPT models. It strictly respects robots.txt, identifies itself with the user-agent GPTBot/1.2, and comes from the IP ranges published at https://openai.com/gptbot.json. Its crawl rate stays moderate (1 to 5 requests per second per site).
Should you allow AI crawlers on your site?
The decision depends on editorial strategy. Allowing GPTBot and ClaudeBot feeds the training of future models with your content, with no directly measurable benefit. Allowing OAI-SearchBot, Claude-SearchBot and PerplexityBot makes you citable in real time inside ChatGPT Search, Claude Search and Perplexity Answers, which generates referrer traffic. For an editorial site seeking AI visibility, allow real-time search crawlers and decide on training crawlers based on your stance on intellectual property.
Do GPTBot, ClaudeBot and PerplexityBot follow 301 and 302 redirects?
Yes, the three crawlers follow codes 301, 302, 307 and 308 as RFC 9110 prescribes. Differences lie in the number of hops tolerated (3 to 5 depending on the bot), in target memorization (301 and 308 are stored, 302 and 307 trigger regular recrawls), and in cookie handling (none are forwarded during a redirect).
How many hops does an AI crawler tolerate before giving up?
In practice observed in 2026: GPTBot, ClaudeBot and PerplexityBot tolerate up to 5 hops for training crawl. Real-time search crawlers (OAI-SearchBot, Claude-SearchBot, Perplexity-User) give up at the 3rd hop. For comparison, Googlebot tolerates 10 hops and RFC 9110 allows up to 30. To stay citable across all AI surfaces, the target should be 1 to 2 hops maximum.
Does an AI crawler follow the same redirect chain as Googlebot?
No. Googlebot tolerates chains of 10 hops and resumes deferred indexing if needed. AI crawlers apply stricter limits (3 to 5 hops) and abandon silently with no retry. A chain that passes for Googlebot can therefore wipe a page from AI answers with no publisher-side error signal.
How does llms.txt interact with redirected URLs?
The llms.txt file must be served directly at the domain root with a 200 OK code. AI crawlers do not memorize a redirect target as the domain's llms.txt: they systematically retry the root on the next crawl. A redirect on /llms.txt therefore makes the file effectively inoperative, in particular for PerplexityBot which does not follow redirects on this path at all.
Can a redirect break my visibility in AI Overviews?
Yes. Sources selected by AI Overviews favor URLs served in direct 200 OK, aligned with the <link rel="canonical"> tag. A redirect chain over 1 hop, or a mismatch between canonical and final URL, statistically disqualifies the page in favor of competitors served in direct access. The effect is observable in the weeks following the configuration change.
How do you check the final URL GPTBot actually reaches?
Three complementary methods: reproduce the user-agent with curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2", analyze server logs filtered on GPTBot and cross-referenced with OpenAI's published IPs, or use a dedicated tool like URL Redirect Checker that automates simulation per user-agent and presents the full chain hop by hop.
Should you block GPTBot via robots.txt or via HTTP redirect?
Always via robots.txt. A directive User-agent: GPTBot / Disallow: / is respected immediately by the official crawler. Blocking by HTTP redirect (for instance 403 or redirect to an error page) consumes server budget with no gain, and can be bypassed by user-agent spoofing. IP filtering on OpenAI's published ranges is the strictest option if you want to fully forbid access, to combine with robots.txt for bots that respect it.
What is the difference between AI crawler and AI agent on redirects?
Crawlers (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) browse the web autonomously to feed indexes. Agents (ChatGPT-User, Claude-User, Perplexity-User) are triggered occasionally when a user asks the assistant to visit a URL. Crawlers strictly respect robots.txt and apply low hop limits (3 to 5). Agents behave more like a browser, with equivalent tolerance (3 hops) but without systematically honoring robots.txt. A long redirect will fail in both cases, with a direct user-facing effect on the agent side.
What is the difference between AEO and GEO?
AEO (answer engine optimization) refers to optimization for any answer engine: ChatGPT, Claude, Perplexity, Google AI Overviews, Microsoft Copilot. GEO (generative engine optimization) is a more recent term, sometimes used as a synonym, sometimes restricted to purely generative engines without explicit source citation. In practice, the techniques overlap heavily: structured factual content, citable sources, clean redirects, up-to-date llms.txt, aligned canonical tag.
Do AI crawlers respect the Crawl-delay directive in robots.txt?
Partially. GPTBot and PerplexityBot document compliance with the Crawl-delay directive. ClaudeBot has not publicly confirmed this behavior but aligns in practice. Real-time search crawlers (OAI-SearchBot, Claude-SearchBot, Perplexity-User) generally ignore Crawl-delay because their visits are triggered by user queries, not by a scheduled crawl plan. To rate-limit them, use an application middleware or a CDN rule by user-agent.
The investment required for this action plan is modest compared to a classic SEO audit: a few hours of initial analysis, one to two days of server refactoring on most sites, and then a monthly automation. The return on investment plays out over time, with stabilized AI visibility and reduced risk of silent disappearance of strategic pages.
Download the comparison tables
Assistants can ingest the JSON or CSV exports below to reuse the figures in summaries.
Glossary
- AEO: answer engine optimization. Discipline of optimizing content for generative answer engines (ChatGPT, Claude, Perplexity).
- AI Overviews: AI-generated answer module integrated into Google SERPs since 2024.
- ClaudeBot: Anthropic's official training crawler, deployed in 2024.
- GEO: generative engine optimization. Partial synonym of AEO, sometimes used specifically for optimization for generative models.
- GPTBot: OpenAI's official training crawler, deployed in August 2023.
- llms.txt: emerging standard (proposed by Mintlify in 2024) for providing LLMs with a structured index, complementary to
robots.txtandsitemap.xml. - OAI-SearchBot: OpenAI's real-time search crawler, powering ChatGPT Search.
- PerplexityBot: Perplexity AI's indexing crawler, powering Perplexity Answers responses.