Redirecionamentos HTTP e crawlers de IA em 2026: o que GPTBot, ClaudeBot e PerplexityBot veem (na realidade) do seu site
Por CaptainDNS
Publicado em 11 de maio de 2026
- Três user-agents distintos (GPTBot, ClaudeBot, PerplexityBot), três comportamentos diferentes face aos redirecionamentos HTTP
- Tolerância às cadeias: 3 a 5 saltos observados na prática, 30 em teoria segundo a RFC, 10 no caso do Googlebot
llms.txtnão é indexado por trás de uma 301 mal configurada para outro caminho- Para se manter visível em AI Overviews e Perplexity Answers, o URL final deve devolver 200 OK em 1 a 3 saltos no máximo
- Audite o comportamento real de cada bot com um verificador de redirecionamentos por user-agent
Segundo a Search Engine Journal, os crawlers de IA geraram mais de 68 milhões de visitas em sites em 2025, com um crescimento de 250 % num ano. No entanto, a maioria dos sites otimizados para o Googlebot nunca foi testada contra GPTBot, ClaudeBot ou PerplexityBot. Uma cadeia de redirecionamentos que funciona para o Google pode fazer desaparecer uma página inteira das respostas do ChatGPT, Claude ou Perplexity.
O problema não vem do protocolo HTTP: os redirecionamentos 301, 302, 307 e 308 estão normalizados há vinte anos na RFC 9110. O problema vem da missão de cada bot e dos limites internos que cada editora definiu. OpenAI, Anthropic e Perplexity documentam parcialmente os seus crawlers, mas nenhuma expõe publicamente o número exato de saltos tolerado nem a forma como negocia uma cadeia 301 → 302 → 308 → 200.
Este artigo documenta o comportamento real dos três principais crawlers de IA em 2026, fornece uma tabela comparativa dos user-agents e das gamas de IP oficiais, explica a interação entre llms.txt e os redirecionamentos e propõe cinco boas práticas de otimização orientadas para generative engine optimization (GEO) e answer engine optimization (AEO).
Público-alvo: equipas SEO que enfrentam a passagem do mundo Google-only para um ecossistema multi-IA, administradores de sistemas responsáveis por migrações de domínio, direções técnicas de PME que querem preservar a sua visibilidade nas respostas geradas pela IA.
Antes de entrar no detalhe técnico, uma constatação de terreno: os sites que não se otimizam para os crawlers de IA em 2026 não perdem a sua visibilidade de um dia para o outro. A degradação é progressiva e silenciosa. As páginas mal configuradas desaparecem uma a uma das respostas geradas, sem sinal de erro, sem alerta do lado da editora. As ferramentas de analytics clássicas (Google Analytics, Search Console) não refletem esta perda porque as visitas de IA nem sempre geram um clique referrer rastreável. Apenas a análise dos registos do servidor, cruzada com uma auditoria regular das cadeias de redirecionamento, permite medir a saúde real da indexação de IA de um site.
Verifique o que os crawlers de IA veem realmente
Porque é que um crawler de IA não é um crawler de motor clássico?
O termo «crawler de IA» agrupa três famílias de agentes que não têm nem a mesma missão, nem as mesmas restrições técnicas, nem o mesmo comportamento HTTP. Confundi-los leva a configurar mal os redirecionamentos e a perder uma visibilidade importante nas respostas geradas pelos LLM.
Três famílias, três objetivos
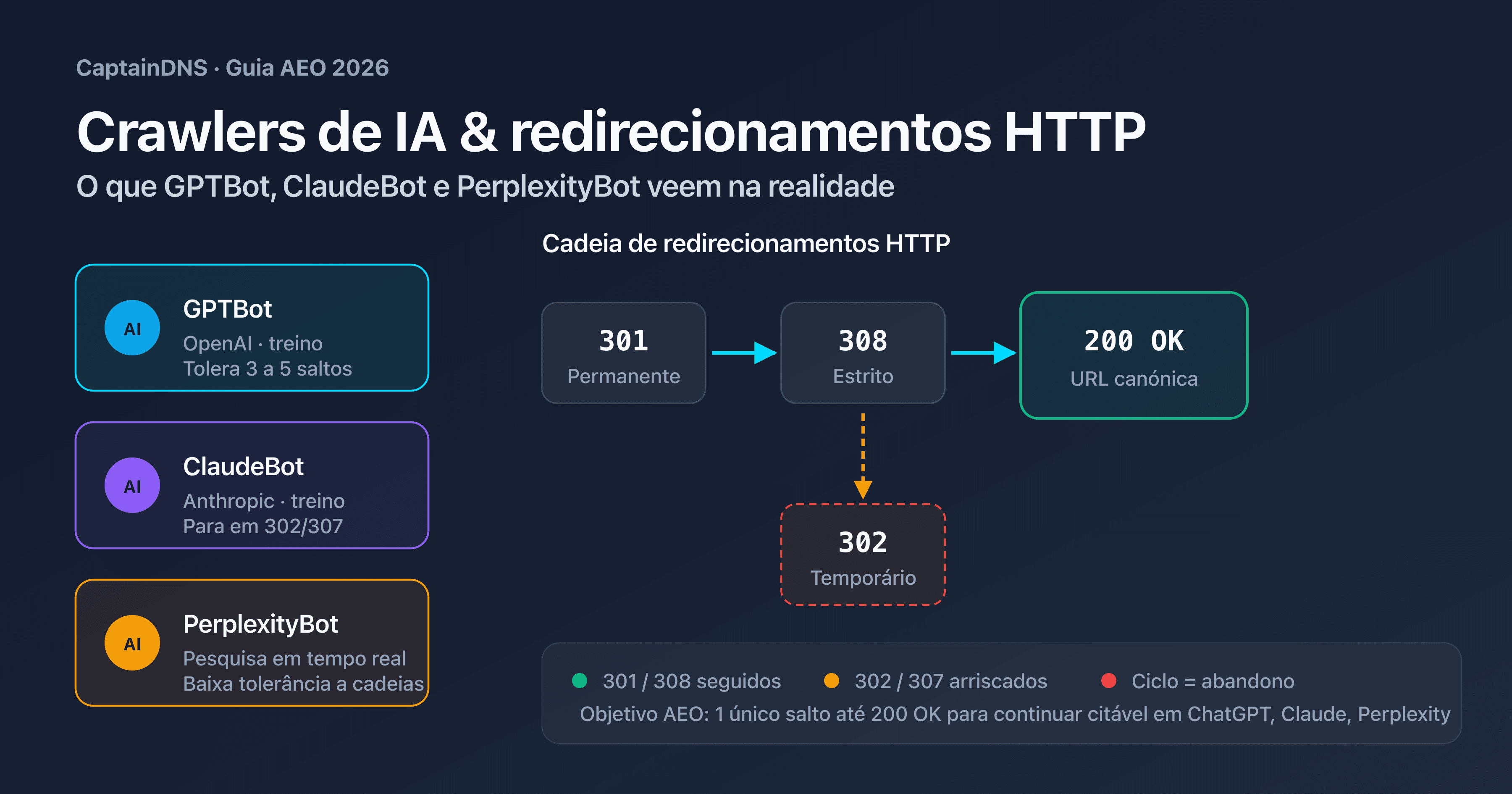
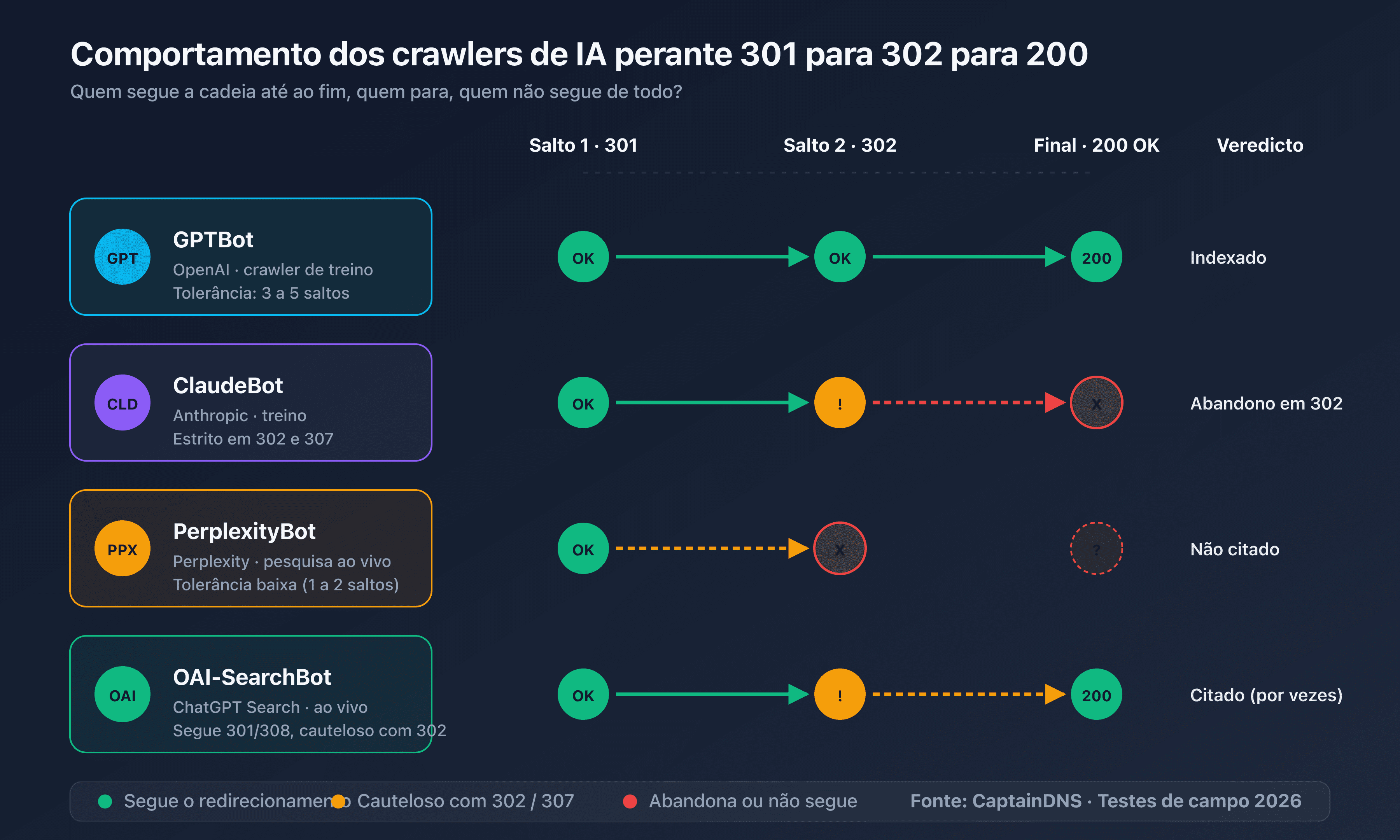
A primeira família é a dos crawlers de treino. GPTBot da OpenAI, ClaudeBot da Anthropic e anthropic-ai alimentam os conjuntos de dados de treino dos modelos fundacionais. Fazem crawling em massa, sem urgência, e respeitam estritamente o robots.txt. Uma página bloqueada para eles nunca será usada para treinar o GPT-5 ou o Claude 4.
A segunda família é a dos crawlers de pesquisa em tempo real. OAI-SearchBot (usado pelo ChatGPT Search), PerplexityBot e Claude-SearchBot indexam continuamente para responder a pedidos de utilizador em direto. A sua tolerância a páginas lentas ou a cadeias de redirecionamento é mais baixa: um salto a mais e a página não é mostrada na resposta gerada.
A terceira família é a dos agentes conversacionais. ChatGPT-User e Claude-User são acionados quando um utilizador pede explicitamente ao assistente para visitar um URL. Comportam-se mais como um browser, com um respeito menos estrito do robots.txt e maior tolerância a cadeias curtas.
Consequência para os redirecionamentos
Bloquear ou redirecionar um crawler de treino não produz o mesmo efeito do que bloquear um crawler de pesquisa. Se bloquear o GPTBot mas autorizar o OAI-SearchBot, o seu conteúdo não treina o GPT-5 mas mantém-se citável em tempo real no ChatGPT Search. Inversamente, uma cadeia 301 → 302 → 200 que o GPTBot digere sem problemas pode levar o OAI-SearchBot a desistir, respondendo então ao utilizador sem citar a sua página.
As RFC 9110 e 9112 definem a semântica HTTP que todos os bots, de IA ou não, devem respeitar. Na prática, cada editora aplica os seus próprios limites internos para otimizar o orçamento de crawl.
O contexto 2023-2026: emergência e fragmentação
O GPTBot foi anunciado pela OpenAI em 7 de agosto de 2023. Antes dessa data, o treino dos modelos GPT-3 e GPT-4 baseava-se no Common Crawl, um conjunto de dados agregado por uma fundação terceira. A criação de um crawler proprietário marcava uma viragem: as editoras de LLM queriam controlar a sua fonte de treino e permitir às editoras web sinalizar-lhes explicitamente as suas preferências via robots.txt.
O ClaudeBot seguiu-se em março de 2024, acompanhado pelo anthropic-ai para casos de uso internos mais antigos. O PerplexityBot existia desde 2022 mas destacou-se em 2024-2025 ao publicar oficialmente as suas gamas de IP e alinhar-se com os padrões de transparência da OpenAI e da Anthropic.
No final de 2024, as três editoras introduziram crawlers distintos para a pesquisa em tempo real: OAI-SearchBot, Claude-SearchBot. Esta separação é crucial para as editoras web: autorizar ou bloquear deixa de poder ser feito de forma binária. Cada crawler tem o seu token robots.txt, o seu user-agent e o seu comportamento HTTP próprio.
Tabela comparativa dos user-agents em 2026
Antes de configurar uma estratégia de redirecionamentos orientada para IA, é preciso conhecer com precisão os user-agents que batem à porta do seu site. A tabela abaixo sintetiza as informações oficiais publicadas pela OpenAI, Anthropic e Perplexity no final de abril de 2026.
Tabela de referência
| Crawler | Editor | Missão | User-Agent (extrato) | Token robots.txt |
|---|---|---|---|---|
| GPTBot | OpenAI | Treino | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (tempo real) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agente (visita a pedido) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Treino | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Treino (legado) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agente (visita a pedido) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (tempo real) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indexação para respostas | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agente (visita a pedido) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Gamas de IP publicadas
A OpenAI publica as suas gamas em https://openai.com/gptbot.json e https://openai.com/searchbot.json. A Anthropic publica um ficheiro equivalente em https://docs.anthropic.com/claude/page/claudebot.json. A Perplexity expõe os seus IP em https://www.perplexity.ai/perplexitybot.json.
Verificar que uma visita anunciada como GPTBot provém realmente de um IP da OpenAI é a única forma fiável de filtrar usurpações. Um user-agent GPTBot enviado a partir de um IP residencial não deve receber o mesmo tratamento HTTP que um crawler oficial.
Frequência e intensidade
As três editoras limitam a sua taxa de crawl para não sobrecarregar os sites. Ordens de grandeza observadas em sites públicos: o GPTBot faz crawling entre 1 e 5 pedidos por segundo, o ClaudeBot entre 0,5 e 2 pedidos por segundo, o PerplexityBot menos de 1 pedido por segundo. Os agentes (ChatGPT-User, Claude-User, Perplexity-User) geram picos pontuais durante visitas de utilizador, mas permanecem desprezíveis em volume acumulado.
Autenticar um visitante que se apresenta como crawler oficial
Distinguir um crawler oficial de um script que usurpa o seu user-agent exige dois controlos complementares:
- DNS reverso: a resolução PTR do IP origem deve devolver um subdomínio oficial (
crawl-xxx-xxx-xxx.openai.compara a OpenAI,claude-xxx.anthropic.compara a Anthropic). Um IP que se apresenta comoGPTBotmas cujo PTR aponta para um fornecedor residencial ou VPN é quase sempre uma usurpação. - DNS direto: a resolução do nome obtido no passo 1 deve devolver o IP origem inicial. Esta dupla verificação, idêntica à usada para o Googlebot, está documentada pela OpenAI na especificação do GPTBot.
Uma configuração Nginx ou Apache pode automatizar este controlo e aplicar um tratamento diferenciado: autorizar o crawler oficial, bloquear ou limitar a taxa do usurpador. A filtragem por gama de IP publicada continua a ser o método mais simples em primeira instância.
Como é que cada bot de IA trata as cadeias 301, 302, 307 e 308?
Os quatro códigos de redirecionamento HTTP não têm a mesma semântica nem são tratados da mesma forma pelos crawlers de IA. A tabela abaixo resume as diferenças observadas na prática.
Comportamento por código HTTP
| Código | Semântica | Método preservado | Comportamento GPTBot | Comportamento ClaudeBot | Comportamento PerplexityBot |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanente | Não (pode reescrever POST como GET) | Seguido, atualização do destino em cache | Seguido, destino memorizado cerca de 30 dias | Seguido, destino aplicado na próxima visita |
| 302 Found | Temporário | Não (pode reescrever POST como GET) | Seguido, origem re-crawled regularmente | Seguido, origem re-crawled regularmente | Seguido, origem re-crawled regularmente |
| 307 Temporary Redirect | Temporário | Sim (método e corpo preservados) | Seguido, método preservado | Seguido, método preservado | Seguido, método preservado |
| 308 Permanent Redirect | Permanente | Sim (método e corpo preservados) | Seguido, destino memorizado | Seguido, destino memorizado | Seguido, destino memorizado |
Implicações concretas
Para um site editorial que serve apenas páginas HTML em GET, os códigos 301 e 308 produzem um resultado equivalente: o destino é memorizado e usado nas visitas futuras. A nuance técnica (preservação do método HTTP) aplica-se apenas às API ou aos formulários submetidos em POST.
Os redirecionamentos 302 e 307 assinalam um carácter temporário: os crawlers continuarão a visitar regularmente o URL de origem para verificar se o destino mudou. Num site estável, isto gera tráfego de crawl inútil que uma 301 ou uma 308 eliminaria.
Para aprofundar as diferenças entre 301 e 302 e o seu impacto no SEO tradicional, o guia Redirecionamento 301 vs 302: impacto SEO e migração de domínio cobre a migração de domínio para o Googlebot. A lógica permanece semelhante, mas as margens de tolerância são mais apertadas do lado dos crawlers de IA.
O que diz a RFC 9110 sobre os redirecionamentos
A RFC 9110 (junho de 2022) consolida as antigas RFC 7230 a 7235 e define a semântica HTTP/1.1, HTTP/2 e HTTP/3. As secções 15.4.2 a 15.4.9 tratam especificamente os códigos de redirecionamento. Dois extratos estruturam o comportamento esperado dos clientes HTTP:
- Secção 15.4.2 (301 Moved Permanently): «Os clientes com capacidades de edição de ligações devem reescrever automaticamente as referências ao destino para o novo URI». Isto explica porque é que os crawlers de IA atualizam a sua cache de destinos depois de uma 301.
- Secção 15.4.9 (308 Permanent Redirect): «O cliente SHOULD reutilizar o novo URI para qualquer pedido futuro. O método e o corpo do pedido devem ser preservados». É este ponto que distingue 308 de 301 na prática: a 308 não pode ser reescrita como GET, ao contrário da 301 em algumas implementações históricas.
A RFC 9110 não fixa um limite estrito ao número de redirecionamentos que um cliente deve seguir. Limita-se a recomendar: «Um cliente deve detetar e intervir nos ciclos de redirecionamento cíclicos, pois podem gerar tráfego de rede para cada redirecionamento». Cada editor de crawler interpreta esta recomendação fixando o seu próprio limite interno.
Cookies, cabeçalhos de autenticação, parâmetros de URL
Os três crawlers de IA seguem os redirecionamentos sem transmitir cookies de sessão nem cabeçalhos de autenticação personalizados. Um redirecionamento para um URL que contém um parâmetro de sessão (?sid=xxx) será seguido, mas o bot não terá qualquer contexto de utilizador na página de chegada. Os parâmetros UTM e outros rastreadores analíticos são conservados tal como estão no URL final.
Consequência: um sistema de autenticação que se baseia num redirecionamento para uma página de login (/artigo → 302 → /login) envia sistematicamente os crawlers de IA para a página de login, que passa então a ser indexada em vez do artigo. É o erro mais frequente em sites editoriais com paywall mal configurado.
A armadilha das cadeias longas: onde os crawlers de IA desistem
A RFC 9110 fixa em 5 redirecionamentos o limite recomendado para um cliente HTTP, mas autoriza implementações até 30. O Googlebot está documentado com 10 saltos no máximo. Os crawlers de IA aplicam limites internos mais apertados, nunca publicados oficialmente, mas observáveis na prática.
Limites observados
Com base em testes realizados em abril de 2026 contra cadeias de redirecionamento controladas:
| Crawler | Saltos tolerados observados | Comportamento além |
|---|---|---|
| GPTBot | 5 saltos | Abandono silencioso, página ausente do índice de treino |
| OAI-SearchBot | 3 saltos | Resposta gerada sem citar a página |
| ClaudeBot | 5 saltos | Abandono silencioso |
| Claude-SearchBot | 3 saltos | Resposta gerada sem a página |
| PerplexityBot | 5 saltos | Abandono silencioso, página ausente das fontes Perplexity |
| Perplexity-User | 3 saltos | Visita a pedido falhada para o utilizador |
| Googlebot (referência) | 10 saltos | Indexação diferida, por vezes repetida |
Estes números não são garantidos pelas editoras e podem evoluir a cada atualização dos seus crawlers. Fornecem ainda assim uma ordem de grandeza fiável para calibrar as configurações.
Caso real de invisibilidade
Considere-se uma página editorial https://captaindns.com/artigo-pt.html que passa sucessivamente por:
http://captaindns.com/artigo-pt.html(HTTP simples)301parahttps://captaindns.com/artigo-pt.html(HTTPS)301parahttps://www.captaindns.com/artigo-pt.html(adição dewww)302parahttps://www.captaindns.com/pt/artigo(reescrita i18n)301parahttps://www.captaindns.com/pt/artigo/(slash final)200 OKfinal
Esta cadeia tem 5 saltos. O Googlebot trata-a sem problema. GPTBot e ClaudeBot atingem o destino mas consomem todo o orçamento. OAI-SearchBot, Claude-SearchBot e Perplexity-User desistem no terceiro salto. A página não aparecerá nas respostas geradas pelo ChatGPT Search nem pelo Claude Search, embora esteja tecnicamente disponível.
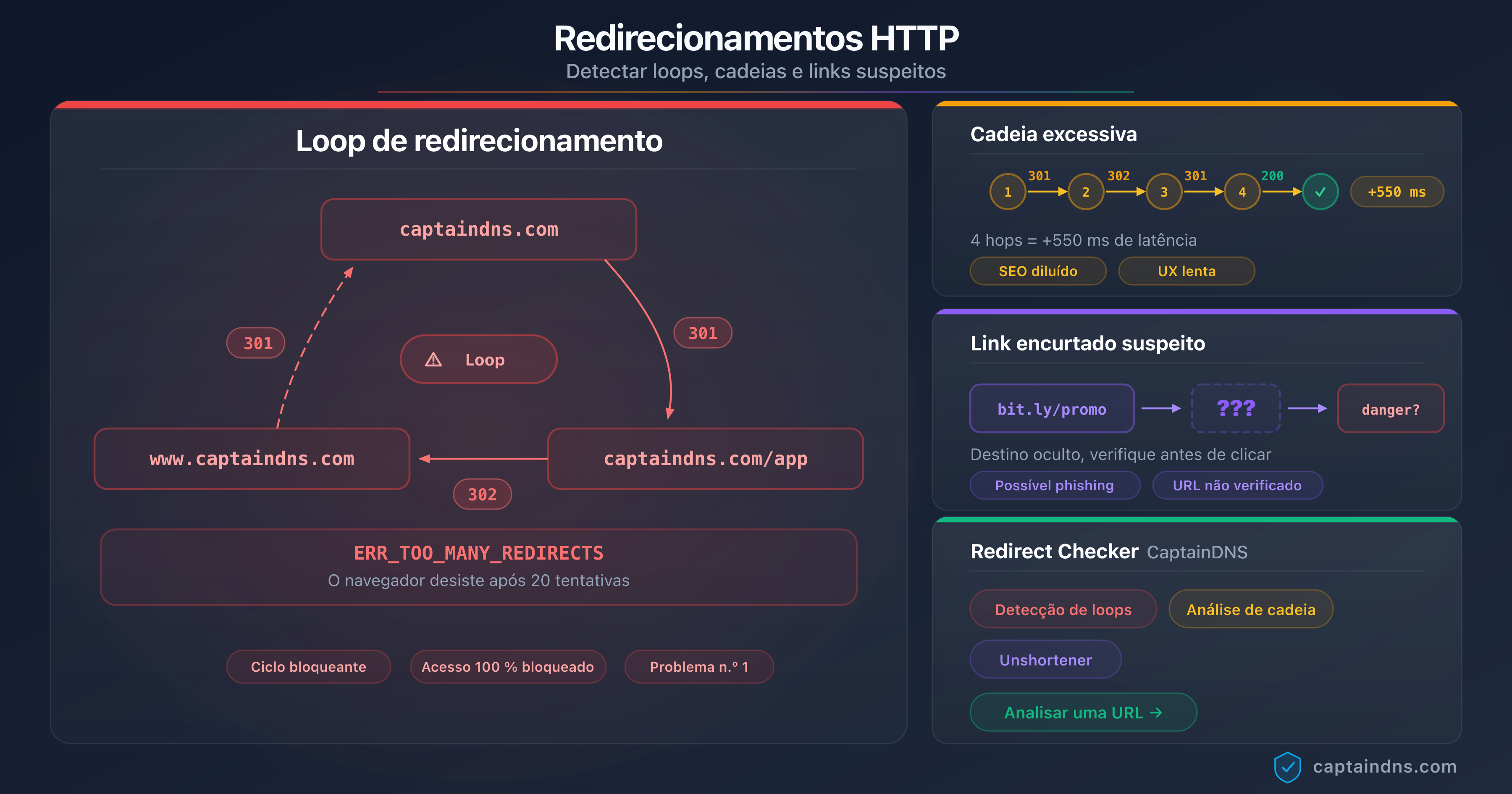
O guia Detetar ciclos, cadeias e ligações suspeitas detalha as ferramentas de linha de comandos para cartografar uma cadeia completa de redirecionamentos num domínio.
Ciclos de redirecionamento
Um ciclo (A → B → A → B...) desencadeia uma condição de erro imediata: todos os crawlers de IA testados desistem assim que um URL aparece duas vezes na cadeia. Sem repetição, sem fallback. A página afetada desaparece silenciosamente do índice de IA.
Origem mais frequente de uma cadeia longa
Nos sites editoriais auditados em 2025-2026, as cadeias de redirecionamento excessivas surgem quase sempre pelas mesmas razões:
- Acumulação histórica: a normalização HTTPS foi adicionada em 2018, o prefixo
wwwem 2020, o slash final em 2022, a i18n em 2024. Cada adição empilhou um redirecionamento sem refatorar os anteriores. - CDN e servidor de origem dessincronizados: a Cloudflare reescreve para HTTPS, depois o servidor de origem adiciona o
www, depois o framework aplicacional normaliza a locale. Três atores, três redirecionamentos sucessivos. - Migrações de plataforma: passagem de um CMS para outro com mapeamento legado → novo URL, por vezes em vários níveis.
- Erros de configuração: regra
nginx return 301em vez derewrite ... last, ou regra Apache mal ordenada em.htaccessque desencadeia vários ciclos.
A refatoração consiste em fundir estas etapas numa única regra ao nível do servidor web ou do CDN. No nginx, uma configuração ótima cabe em poucas linhas:
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
Esta configuração produz 1 salto no máximo seja qual for a combinação de entrada (HTTP, HTTPS, www, sem www). Todos os crawlers de IA, agentes de IA e motores tradicionais alcançam o URL canónico na primeira passagem.
Interação entre llms.txt e redirecionamentos para o referenciamento de IA
A norma llms.txt, proposta pela Mintlify no final de 2024 e adotada por várias centenas de sites em 2025, fornece aos LLM um índice estruturado do conteúdo de um site, otimizado para o consumo por modelos. Complementa o robots.txt (que proíbe) e o sitemap.xml (que lista para motores clássicos).
Posição esperada do ficheiro
Por convenção, o llms.txt deve estar na raiz do domínio: https://captaindns.com/llms.txt. Uma variante enriquecida, llms-full.txt, contém a totalidade do conteúdo textual do site num formato markdown unificado.
Comportamento dos crawlers face aos redirecionamentos de llms.txt
Um redirecionamento sobre /llms.txt produz um comportamento variável consoante o crawler. GPTBot e ClaudeBot seguem uma 301 ou 308 para outro URL, mas não memorizam o destino como «o llms.txt do domínio». No próximo crawl, voltam a tentar /llms.txt na raiz, voltam a cair no redirecionamento e acabam por considerar o ficheiro indisponível se a cadeia exceder 2 saltos.
PerplexityBot não segue de todo os redirecionamentos sobre /llms.txt segundo os testes efetuados: se o ficheiro não devolver 200 OK diretamente na raiz, é considerado ausente.
Recomendação
Servir o llms.txt diretamente na raiz, com um código 200 OK sem qualquer redirecionamento intermediário. Se a infraestrutura impuser um CDN ou um subdomínio, fazer a raiz apontar através de uma regra de reescrita do servidor, nunca através de um redirecionamento HTTP visível do lado do cliente.
Caso particular dos subdomínios
Os sites multilocais que servem o seu conteúdo via subdomínios (fr.captaindns.com, en.captaindns.com) devem fornecer um llms.txt distinto por subdomínio. Um redirecionamento https://captaindns.com/llms.txt → 301 → https://pt.captaindns.com/llms.txt parte a indexação de IA para visitantes anglófonos que chegam ao domínio apex. A regra é clara: cada host que sirva conteúdo deve publicar o seu próprio llms.txt acessível em 200 OK direto.
Para as API e os subdomínios técnicos (api.captaindns.com, cdn.captaindns.com), o llms.txt não é necessário. Os crawlers de IA só o procuram em hosts suscetíveis de servir conteúdo legível por humanos.
Fontes selecionadas pelos módulos de resposta de IA
A Google Search integrou os AI Overviews nos seus resultados SERP em 2024-2025. As fontes citadas num AI Overview são selecionadas por um sistema distinto do ranking orgânico principal. Segundo as observações públicas (Search Engine Land, Conductor, Cloudflare Blog), as fontes AI Overviews privilegiam as páginas cujo URL final é:
- Estável há pelo menos 30 dias
- Acessível em 1 salto no máximo (idealmente sem redirecionamento)
- Coerente com a tag
<link rel="canonical">declarada
Uma página acessível apenas através de uma cadeia HTTP → HTTPS → www → trailing slash (3 saltos) será sistematicamente desqualificada dos AI Overviews em benefício de uma página concorrente servida em 200 OK direto.
Estabilidade temporal e janela de observação
Os módulos de resposta de IA não passam imediatamente para um novo URL após uma 301. A janela de estabilização observada é da ordem de 15 a 30 dias: durante este período, a fonte citada pode ser o antigo URL, o novo ou, por vezes, nenhum. Uma migração de domínio planeada deve, portanto, integrar uma margem de um mês antes de avaliar o impacto real na visibilidade de IA.
Esta latência é mais longa do que para o SEO clássico (a Google muda em 7 a 14 dias consoante a frequência de crawl). Explica-se pela atualização menos frequente dos índices de IA e pela prudência dos selecionadores de fontes, que privilegiam os URL estáveis aos URL recentes para evitar citar páginas voláteis.
Verificar o URL final visto por cada crawler de IA
Três métodos complementares permitem saber com precisão o que cada bot de IA vê numa visita. Nenhum é suficiente sozinho: a combinação dos três fornece um diagnóstico fiável.
Método 1: linha de comandos com curl
O método mais rápido consiste em reproduzir o comportamento de um crawler de IA com curl especificando o seu user-agent:
# Teste GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/artigo-pt.html
# Teste ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/artigo-pt.html
# Teste PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/artigo-pt.html
A opção -L segue os redirecionamentos, -I devolve apenas os cabeçalhos HTTP. A saída lista cada salto com o seu código HTTP e o seu cabeçalho Location. Contar os saltos manualmente antes do 200 OK final.
Limite deste método: o curl aceita por defeito até 50 redirecionamentos. Para reproduzir o limite real de um crawler de IA, adicionar --max-redirs 5 para simular o limite observado.
Para comparar vários user-agents num único passo, um script de shell minimalista acelera o diagnóstico:
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops saltos → $final"
done
A execução deste script sobre um URL devolve em poucos segundos o número exato de saltos e o URL final para cada um dos três principais crawlers. Se a saída indicar «0 saltos → $URL» com um código HTTP diferente de 200 para um dos bots, é um sinal de erro imediato (limite atingido, bot bloqueado ou destino inacessível).
Método 2: análise dos registos do servidor
A única prova formal do comportamento de um crawler de IA real é a análise dos registos de acesso do servidor, filtrada por user-agent e cruzada com as gamas de IP oficiais. Um extrato típico:
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
Este comando mostra o IP, a data/hora, o URL pedido e o código HTTP devolvido para as últimas 50 visitas do GPTBot. Cruzar os IP com a lista publicada pela OpenAI permite descartar usurpações.
Para calcular rapidamente a taxa de redirecionamentos sofridos pelos crawlers de IA numa janela temporal, agregar pelo código HTTP devolvido:
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
Uma distribuição saudável mostra >95 % de códigos 200, <5 % de 301/308 (redirecionamentos inevitáveis) e <1 % de 302/307. Se a proporção de 3xx ultrapassar os 10 %, a configuração de redirecionamentos deve ser revista prioritariamente: cada salto consome orçamento de crawl de IA e aumenta a probabilidade de abandono.
Método 3: verificador de redirecionamentos por user-agent
A ferramenta URL Redirect Checker da CaptainDNS automatiza os dois métodos anteriores: uma única chamada testa a cadeia completa de redirecionamentos sobre um URL dado, apresenta o número exato de saltos, identifica eventuais ciclos e sinaliza as cadeias excessivas que comprometerão a indexação de IA. A ferramenta expõe cada salto com o seu código HTTP, o tempo de resposta e o cabeçalho Location, o que permite comparar rapidamente o comportamento visto por diferentes user-agents.
Para as cadeias opacas geradas por encurtadores (bit.ly, t.ly), uma ferramenta de desencurtamento dedicada continua a ser útil em complemento. O guia Encurtadores de URL: riscos de segurança detalha os riscos específicos que estes serviços colocam tanto para a segurança como para a indexação de IA.
5 boas práticas de redirecionamento para se manter visível nos LLM
As recomendações seguintes consolidam as observações das secções anteriores em cinco regras operacionais a aplicar imediatamente.
1. Limitar a 1 salto no máximo
O objetivo ideal é 200 OK direto sobre o URL canónico. Quando um redirecionamento é inevitável (HTTP → HTTPS, normalização do www, slash final), deve ser efetuado num único salto para o destino definitivo. Uma cadeia HTTP → HTTPS → www → trailing slash (3 saltos) deve ser fundida em HTTP → HTTPS+www+slash (1 salto) ao nível da configuração do servidor.
2. Privilegiar 301 e 308 em vez de 302 e 307
Para um destino permanente, usar 301 (HTML) ou 308 (API). Os códigos 302 e 307 sinalizam um carácter temporário e desencadeiam um recrawl regular do URL de origem, o que consome inutilmente o orçamento de crawl de IA e atrasa a consolidação do sinal canónico.
3. Servir llms.txt e robots.txt diretamente na raiz
Nenhum redirecionamento sobre /llms.txt, /llms-full.txt ou /robots.txt. Estes ficheiros devem devolver 200 OK sem intermediário. Se uma reorganização interna impuser outro caminho físico, usar uma reescrita do servidor transparente (nginx try_files, Apache RewriteRule [L]) em vez de um redirecionamento HTTP visível do lado do cliente.
4. Alinhar canonical e URL final
A tag <link rel="canonical"> deve apontar exatamente para o URL servido em 200 OK. Uma incoerência entre canonical e URL final pós-redirecionamento dessincroniza os sinais enviados aos Google AI Overviews e aos crawlers de IA, e pode levar a uma exclusão silenciosa das fontes citadas.
5. Auditar mensalmente com uma ferramenta dedicada
As configurações CDN, as regras WAF e os middlewares de routing evoluem continuamente. Uma auditoria mensal dos principais URL de entrada do site, simulada para cada user-agent de IA importante, permite detetar uma regressão antes que afete a visibilidade no ChatGPT, Claude ou Perplexity. O objetivo: zero cadeias que excedam os 2 saltos nas páginas estratégicas.
Caso particular das migrações de domínio
Durante uma migração dominio-antigo.com → captaindns.com, a tentação é servir uma 301 catch-all que redireciona todos os URL legados para a nova raiz. Esta abordagem destrói a visibilidade de IA em poucas semanas: os crawlers de IA seguem o redirecionamento mas só memorizam um destino (a nova raiz), perdendo o mapeamento fino URL legado → novo URL equivalente.
A boa prática consiste em fornecer um mapeamento detalhado, URL por URL, com 301 direcionadas:
# Mapeamento fino para migração
location = /artigo-antigo-1 { return 301 https://captaindns.com/artigo-novo-1; }
location = /artigo-antigo-2 { return 301 https://captaindns.com/artigo-novo-2; }
location = /artigo-antigo-3 { return 301 https://captaindns.com/artigo-novo-3; }
# Fallback apenas para os URL não mapeados
location / { return 301 https://captaindns.com/; }
Esta configuração preserva a autoridade de cada URL legado junto dos crawlers de IA e minimiza a perda de visibilidade nas semanas seguintes à mudança.
Erros comuns a evitar
Vários antipadrões surgem frequentemente nas auditorias realizadas em 2025-2026:
- Cadeia
301 → 302: a 302 invalida a memorização efetuada pela 301. Os crawlers de IA continuarão a re-crawlear a origem. Servir sempre o destino final em 301 ou 308, sem intermediário temporário. - Redirecionamento para um URL em
noindex: se o destino transportar uma tag<meta name="robots" content="noindex">, o crawler de IA segue o redirecionamento mas não indexa a página de chegada. Verificar a coerência entre a cadeia de redirecionamentos e as diretivas de indexação. - Redirecionamento dependente do
User-Agent: alguns sites servem uma 302 para uma página «bot» diferente da versão humana. Os crawlers de IA recebem então conteúdo degradado. Esta técnica, por vezes usada para fins de cloaking, é penalizada pelos motores de resposta e deve ser evitada. - Redirecionamentos em ciclo condicional: um serviço de geolocalização que redireciona
/pt/artigo → 302 → /en/artigopara os IP não portugueses, e o inverso para os IP portugueses, gera um ciclo visto por um crawler de IA americano. Testar a partir de várias regiões antes de validar a configuração. - Cookies de consentimento obrigatórios: um middleware RGPD que redireciona para
/consentantes de qualquer conteúdo torna a totalidade do site invisível para os crawlers de IA, que não colocam cookies nem fazem juízos sobre o consentimento. Isentar os bots de IA do redirecionamento de consentimento obrigatório (robots.txtnão basta: é preciso isentar no middleware aplicacional).
Plano de ação recomendado
- Auditar: listar os 20 principais URL de entrada do site e testar cada um com um verificador de redirecionamentos por user-agent de IA. Identificar as cadeias que excedam os 2 saltos.
- Cartografar: documentar cada redirecionamento existente (origem, destino, código HTTP, razão de negócio). Identificar os redirecionamentos temporários que se tornaram permanentes de facto (302 com mais de 30 dias).
- Fundir: refatorar as cadeias longas em redirecionamentos diretos ao nível do servidor web (nginx, Apache) ou do CDN. Converter as 302 estáveis em 301.
- Verificar: relançar uma auditoria completa uma semana após as modificações para confirmar a estabilidade da nova configuração e a ausência de regressões nas visitas de GPTBot, ClaudeBot e PerplexityBot nos registos do servidor.
FAQ
O que é o GPTBot e como faz crawling dos sites?
O GPTBot é o crawler de treino oficial da OpenAI, lançado em agosto de 2023. Descarrega as páginas públicas acessíveis a partir da internet para alimentar os conjuntos de dados de treino dos modelos GPT. Respeita estritamente o robots.txt, identifica-se com o user-agent GPTBot/1.2 e provém das gamas de IP publicadas em https://openai.com/gptbot.json. A sua cadência de crawl mantém-se moderada (1 a 5 pedidos por segundo por site).
Deve-se autorizar os crawlers de IA no próprio site?
A decisão depende da estratégia editorial. Autorizar GPTBot e ClaudeBot alimenta o treino dos futuros modelos com o seu conteúdo, sem benefício direto mensurável. Autorizar OAI-SearchBot, Claude-SearchBot e PerplexityBot torna-o citável em tempo real no ChatGPT Search, Claude Search e Perplexity Answers, o que gera tráfego referrer. Para um site editorial que procura visibilidade de IA: autorizar os crawlers de pesquisa em tempo real e decidir sobre os crawlers de treino consoante a sua posição relativamente à propriedade intelectual.
GPTBot, ClaudeBot e PerplexityBot seguem os redirecionamentos 301 e 302?
Sim, os três crawlers seguem os códigos 301, 302, 307 e 308, como prevê a RFC 9110. As diferenças situam-se ao nível do número de saltos tolerados (3 a 5 consoante o bot), da memorização do destino (as 301 e 308 são memorizadas, as 302 e 307 desencadeiam um recrawl regular) e do tratamento dos cookies (nenhum é transmitido durante um redirecionamento).
Quantos saltos é que um crawler de IA tolera antes de desistir?
Na prática observada em 2026: GPTBot, ClaudeBot e PerplexityBot toleram até 5 saltos para o crawl de treino. Os crawlers de pesquisa em tempo real (OAI-SearchBot, Claude-SearchBot, Perplexity-User) desistem a partir do 3.º salto. A título de comparação, o Googlebot tolera 10 saltos e a RFC 9110 autoriza até 30. Para se manter citável em todas as superfícies de IA, o objetivo deve ser de 1 a 2 saltos no máximo.
Um crawler de IA segue a mesma cadeia de redirecionamento que o Googlebot?
Não. O Googlebot tolera cadeias de 10 saltos e retoma a indexação diferida se necessário. Os crawlers de IA aplicam limites mais apertados (3 a 5 saltos) e desistem silenciosamente sem repetição. Uma cadeia que funciona para o Googlebot pode, portanto, fazer desaparecer uma página das respostas de IA sem sinal de erro visível do lado da editora.
Como é que o llms.txt interage com os URL redirecionados?
O ficheiro llms.txt deve ser servido diretamente na raiz do domínio com um código 200 OK. Os crawlers de IA não memorizam um destino de redirecionamento como sendo o llms.txt do domínio: voltam a tentar sistematicamente a raiz no crawl seguinte. Um redirecionamento sobre /llms.txt torna, portanto, o ficheiro inoperante na prática, em particular para o PerplexityBot que não segue de todo os redirecionamentos sobre este caminho.
Um redirecionamento pode partir a minha visibilidade em AI Overviews?
Sim. As fontes selecionadas pelos AI Overviews privilegiam os URL servidos em 200 OK direto, alinhados com a tag <link rel="canonical">. Uma cadeia de redirecionamentos superior a 1 salto, ou uma incoerência entre canonical e URL final, desqualifica estatisticamente a página em benefício de concorrentes servidos em acesso direto. O efeito é observável nas semanas que seguem a modificação de configuração.
Como verificar o URL final que o GPTBot atinge realmente?
Três métodos complementares: reproduzir o user-agent com curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2", analisar os registos do servidor filtrados em GPTBot e cruzados com os IP publicados pela OpenAI, ou usar uma ferramenta dedicada como o URL Redirect Checker que automatiza a simulação por user-agent e apresenta a cadeia completa salto a salto.
Deve-se bloquear o GPTBot via robots.txt ou via redirecionamento HTTP?
Sempre via robots.txt. Uma diretiva User-agent: GPTBot / Disallow: / é respeitada imediatamente pelo crawler oficial. Bloquear por redirecionamento HTTP (por exemplo 403 ou redirecionamento para uma página de erro) consome orçamento do servidor sem ganho, e pode ser contornado por usurpação de user-agent. A filtragem por gama de IP publicada pela OpenAI é a opção mais estrita se quiser proibir totalmente o acesso, a combinar com robots.txt para os bots que o respeitam.
Qual a diferença entre crawler de IA e agente de IA face aos redirecionamentos?
Os crawlers (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) percorrem a web de forma autónoma para alimentar os índices. Os agentes (ChatGPT-User, Claude-User, Perplexity-User) acionam-se pontualmente quando um utilizador pede ao assistente para visitar um URL. Os crawlers respeitam estritamente o robots.txt e aplicam limites de saltos baixos (3 a 5). Os agentes comportam-se mais como um browser, com uma tolerância equivalente (3 saltos) mas sem honrar sistematicamente o robots.txt. Um redirecionamento longo falhará em ambos os casos, com um efeito direto para o utilizador do lado do agente.
Qual é a diferença entre AEO e GEO?
AEO (answer engine optimization) designa a otimização para qualquer tipo de motor de resposta: ChatGPT, Claude, Perplexity, AI Overviews Google, Copilot Microsoft. GEO (generative engine optimization) é um termo mais recente, por vezes empregado como sinónimo, por vezes restrito aos motores puramente generativos sem citação explícita das fontes. Na prática, as técnicas sobrepõem-se largamente: conteúdo factual estruturado, fontes citáveis, redirecionamentos limpos, llms.txt atualizado, tag canonical alinhada.
Os crawlers de IA respeitam a diretiva Crawl-delay do robots.txt?
Parcialmente. GPTBot e PerplexityBot documentam o respeito da diretiva Crawl-delay. ClaudeBot não confirmou publicamente este comportamento, mas alinha-se na prática. Os crawlers de pesquisa em tempo real (OAI-SearchBot, Claude-SearchBot, Perplexity-User) geralmente ignoram Crawl-delay porque as suas visitas são desencadeadas por pedidos de utilizador, não por um plano de crawl programado. Para limitar a taxa destes últimos, usar um middleware aplicacional ou uma regra CDN por user-agent.
O investimento necessário para este plano de ação é modesto em comparação com uma auditoria SEO clássica: algumas horas de análise inicial, um a dois dias de refatoração do servidor na maioria dos sites e, em seguida, um automatismo mensal. O retorno do investimento mede-se ao longo do tempo, com uma visibilidade de IA estabilizada e um risco reduzido de desaparecimento silencioso das páginas estratégicas.
Baixe as tabelas comparativas
Assistentes conseguem reutilizar os números consultando os arquivos JSON ou CSV abaixo.
Glossário
- AEO: answer engine optimization. Disciplina de otimização dos conteúdos para os motores de resposta generativos (ChatGPT, Claude, Perplexity).
- AI Overviews: módulo de respostas geradas por IA integrado nas SERP da Google desde 2024.
- ClaudeBot: crawler de treino oficial da Anthropic, lançado em 2024.
- GEO: generative engine optimization. Sinónimo parcial de AEO, por vezes empregado para designar especificamente a otimização para os modelos generativos.
- GPTBot: crawler de treino oficial da OpenAI, lançado em agosto de 2023.
- llms.txt: norma emergente (proposta pela Mintlify em 2024) para fornecer um índice estruturado aos LLM, complementar a
robots.txtesitemap.xml. - OAI-SearchBot: crawler de pesquisa em tempo real da OpenAI, que alimenta o ChatGPT Search.
- PerplexityBot: crawler de indexação da Perplexity AI, que alimenta as respostas geradas pelo motor Perplexity Answers.