HTTP-Weiterleitungen und KI-Crawler 2026: was GPTBot, ClaudeBot und PerplexityBot wirklich von Ihrer Website sehen
Von CaptainDNS
Veröffentlicht am 11. Mai 2026
- Drei verschiedene User-Agents (GPTBot, ClaudeBot, PerplexityBot), drei unterschiedliche Verhaltensweisen bei HTTP-Weiterleitungen
- Kettentoleranz: 3 bis 5 Hops in der Praxis beobachtet, 30 laut RFC, 10 bei Googlebot
llms.txtwird hinter einer falsch konfigurierten 301 auf einen anderen Pfad nicht indexiert- Um in AI Overviews und Perplexity Answers sichtbar zu bleiben, muss Ihre Ziel-URL 200 OK in 1 bis 3 Hops liefern
- Prüfen Sie das tatsächliche Verhalten jedes Bots mit einem Redirect-Checker pro User-Agent
Laut Search Engine Journal haben KI-Crawler 2025 mehr als 68 Millionen Besuche auf Websites generiert, ein Plus von 250 % gegenüber dem Vorjahr. Dennoch wurden die meisten für Googlebot optimierten Sites noch nie gegen GPTBot, ClaudeBot oder PerplexityBot getestet. Eine Weiterleitungskette, die für Google funktioniert, kann eine ganze Seite aus den Antworten von ChatGPT, Claude oder Perplexity verschwinden lassen.
Das Problem liegt nicht im HTTP-Protokoll: Die Weiterleitungen 301, 302, 307 und 308 sind seit zwanzig Jahren in RFC 9110 normiert. Das Problem liegt in der Mission jedes Bots und in den internen Limits, die jeder Anbieter festgelegt hat. OpenAI, Anthropic und Perplexity dokumentieren ihre Crawler nur teilweise, doch keiner gibt öffentlich die genaue Anzahl tolerierter Hops oder den Umgang mit einer Kette 301 → 302 → 308 → 200 an.
Dieser Artikel dokumentiert das tatsächliche Verhalten der drei wichtigsten KI-Crawler 2026, liefert eine Vergleichstabelle der User-Agents und der offiziellen IP-Bereiche, erklärt das Zusammenspiel zwischen llms.txt und Weiterleitungen und schlägt fünf Optimierungs-Best-Practices vor, die auf Generative Engine Optimization (GEO) und Answer Engine Optimization (AEO) ausgerichtet sind.
Zielgruppe: SEO-Teams, die den Wechsel von Google-only zu einem Multi-KI-Ökosystem vollziehen, Systemadministratoren, die für Domain-Migrationen verantwortlich sind, und technische Leitungen mittelständischer Unternehmen, die ihre Sichtbarkeit in KI-generierten Antworten erhalten möchten.
Vor dem technischen Detail eine Beobachtung aus der Praxis: Sites, die 2026 nicht für KI-Crawler optimieren, verlieren ihre Sichtbarkeit nicht über Nacht. Der Verfall ist schleichend und still. Falsch konfigurierte Seiten verschwinden eine nach der anderen aus den generierten Antworten, ohne Fehlersignal, ohne Alarm beim Publisher. Klassische Analytics-Tools (Google Analytics, Search Console) spiegeln diesen Verlust nicht wider, da KI-Besuche nicht immer einen rückverfolgbaren Referrer-Klick erzeugen. Nur die Analyse der Server-Logs in Verbindung mit einer regelmäßigen Prüfung der Weiterleitungsketten erlaubt es, den tatsächlichen Zustand der KI-Indexierung einer Site zu messen.
Prüfen Sie, was KI-Crawler wirklich sehen
Warum ein KI-Crawler kein klassischer Suchmaschinen-Crawler ist?
Der Begriff "KI-Crawler" umfasst drei Familien von Agenten, die weder dieselbe Mission noch dieselben technischen Einschränkungen noch dasselbe HTTP-Verhalten haben. Wer sie verwechselt, konfiguriert seine Weiterleitungen falsch und verliert beträchtliche Sichtbarkeit in LLM-Antworten.
Drei Familien, drei Ziele
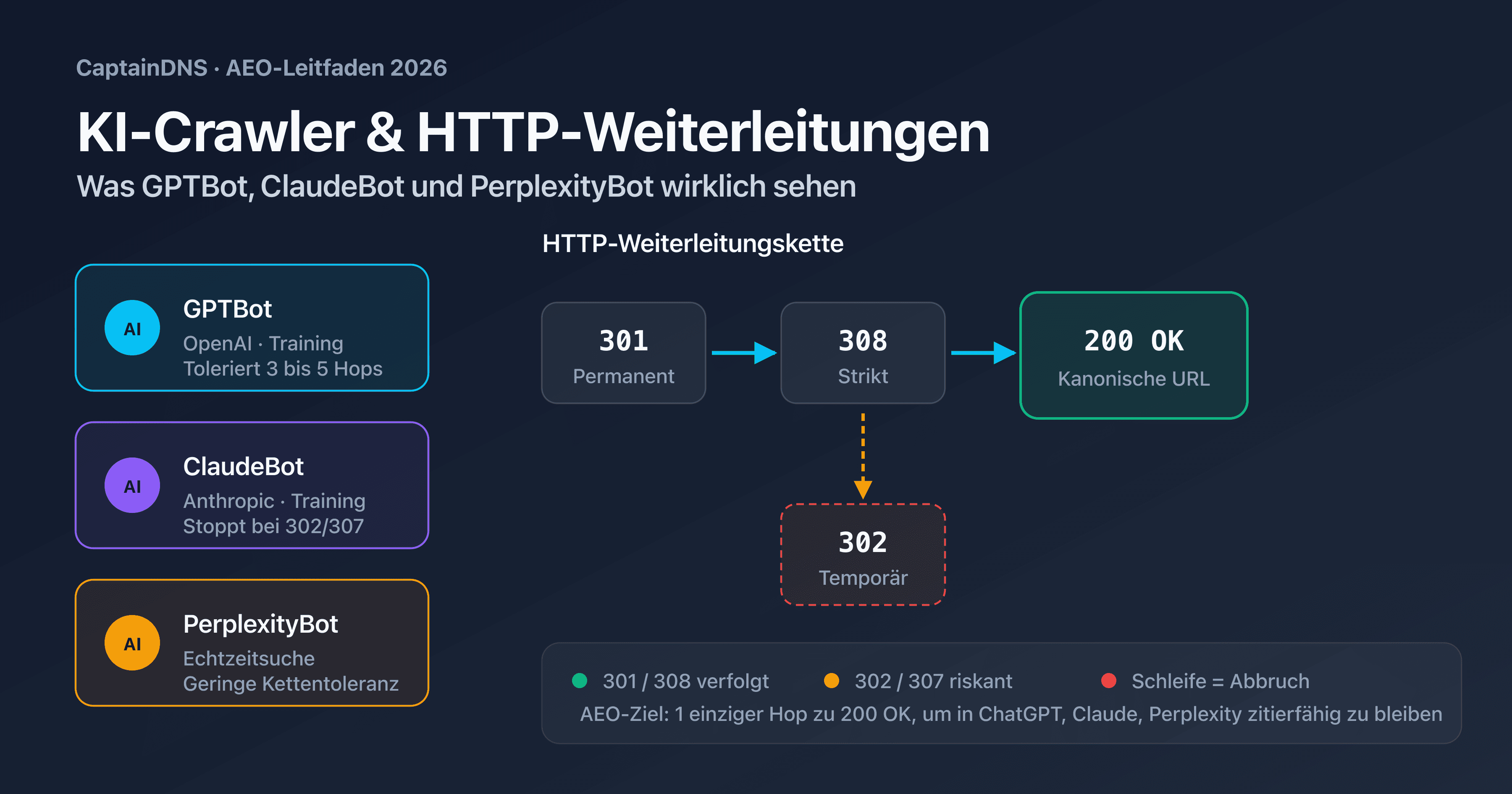
Die erste Familie sind die Trainings-Crawler. GPTBot von OpenAI, ClaudeBot von Anthropic und anthropic-ai speisen die Trainingsdatensätze der Foundation-Modelle. Sie crawlen massenhaft, ohne Eile, und respektieren robots.txt strikt. Eine für sie blockierte Seite wird nie zum Training von GPT-5 oder Claude 4 verwendet.
Die zweite Familie sind die Echtzeit-Suchcrawler. OAI-SearchBot (für ChatGPT Search), PerplexityBot und Claude-SearchBot indexieren laufend, um Nutzeranfragen in Echtzeit zu beantworten. Ihre Toleranz für langsame Seiten oder Weiterleitungsketten ist niedriger: Ein Hop zu viel und die Seite erscheint nicht in der generierten Antwort.
Die dritte Familie sind die Konversationsagenten. ChatGPT-User und Claude-User werden ausgelöst, wenn ein Nutzer den Assistenten ausdrücklich bittet, eine URL zu besuchen. Sie verhalten sich eher wie ein Browser, mit weniger strikter robots.txt-Befolgung und mehr Toleranz für kurze Ketten.
Folge für Weiterleitungen
Einen Trainings-Crawler zu blockieren oder umzuleiten hat nicht denselben Effekt wie das Blockieren eines Suchcrawlers. Wenn Sie GPTBot blockieren, aber OAI-SearchBot erlauben, trainiert Ihr Inhalt zwar nicht GPT-5, bleibt aber in ChatGPT Search in Echtzeit zitierbar. Umgekehrt kann eine Kette 301 → 302 → 200, die GPTBot problemlos verarbeitet, dazu führen, dass OAI-SearchBot aufgibt und dem Nutzer eine Antwort liefert, die Ihre Seite nicht zitiert.
RFC 9110 und 9112 definieren die HTTP-Semantik, die alle Bots, ob KI oder nicht, einhalten sollen. In der Praxis legt jeder Anbieter seine eigenen internen Limits fest, um sein Crawl-Budget zu optimieren.
Der Kontext 2023-2026: Entstehung und Fragmentierung
GPTBot wurde von OpenAI am 7. August 2023 angekündigt. Vorher stützte sich das Training der Modelle GPT-3 und GPT-4 auf Common Crawl, einen von einer dritten Stiftung aggregierten Datensatz. Der Bau eines proprietären Crawlers signalisierte eine Wende: LLM-Anbieter wollten ihre Trainingsquelle kontrollieren und Web-Publishern erlauben, ihre Präferenzen über robots.txt explizit zu signalisieren.
ClaudeBot folgte im März 2024, begleitet von anthropic-ai für ältere interne Anwendungsfälle. PerplexityBot existierte seit 2022, hob sich 2024-2025 aber dadurch hervor, dass seine IP-Bereiche offiziell veröffentlicht und an die Transparenzstandards von OpenAI und Anthropic angepasst wurden.
Ende 2024 führten die drei Anbieter eigene Crawler für die Echtzeitsuche ein: OAI-SearchBot, Claude-SearchBot. Diese Trennung ist für Web-Publisher entscheidend: Erlauben oder Blockieren kann nicht mehr binär erfolgen. Jeder Crawler hat sein eigenes robots.txt-Token, seinen eigenen User-Agent und sein eigenes HTTP-Verhalten.
Vergleichstabelle der User-Agents 2026
Bevor Sie eine KI-orientierte Weiterleitungsstrategie konfigurieren, müssen Sie die User-Agents kennen, die an Ihre Site-Tür klopfen. Die Tabelle unten fasst die offiziellen Informationen zusammen, die OpenAI, Anthropic und Perplexity Ende April 2026 veröffentlicht haben.
Referenztabelle
| Crawler | Herausgeber | Mission | User-Agent (Auszug) | robots.txt-Token |
|---|---|---|---|---|
| GPTBot | OpenAI | Training | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (Echtzeit) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agent (Besuch auf Anfrage) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Training | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Training (Legacy) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agent (Besuch auf Anfrage) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (Echtzeit) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indexierung für Antworten | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agent (Besuch auf Anfrage) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Veröffentlichte IP-Bereiche
OpenAI veröffentlicht seine Bereiche unter https://openai.com/gptbot.json und https://openai.com/searchbot.json. Anthropic veröffentlicht eine entsprechende Datei unter https://docs.anthropic.com/claude/page/claudebot.json. Perplexity stellt seine IPs unter https://www.perplexity.ai/perplexitybot.json bereit.
Zu prüfen, ob ein als GPTBot angekündigter Besuch tatsächlich von einer OpenAI-IP stammt, ist die einzige zuverlässige Methode, um Spoofing zu filtern. Ein GPTBot-User-Agent, der von einer Residential-IP gesendet wird, darf nicht dieselbe HTTP-Behandlung erhalten wie der offizielle Crawler.
Häufigkeit und Intensität
Die drei Anbieter limitieren ihre Crawl-Rate, um Sites nicht zu überlasten. Größenordnungen, die auf öffentlichen Sites beobachtet wurden: GPTBot crawlt zwischen 1 und 5 Anfragen pro Sekunde, ClaudeBot zwischen 0,5 und 2 Anfragen pro Sekunde, PerplexityBot weniger als 1 Anfrage pro Sekunde. Die Agenten (ChatGPT-User, Claude-User, Perplexity-User) erzeugen gelegentliche Spitzen bei Nutzerbesuchen, bleiben aber im kumulierten Volumen vernachlässigbar.
Einen Besucher authentifizieren, der sich als offizieller Crawler ausgibt
Einen offiziellen Crawler von einem Skript zu unterscheiden, das seinen User-Agent fälscht, erfordert zwei ergänzende Prüfungen:
- Reverse DNS: Die PTR-Auflösung der Quell-IP muss eine offizielle Subdomain zurückgeben (
crawl-xxx-xxx-xxx.openai.comfür OpenAI,claude-xxx.anthropic.comfür Anthropic). Eine IP, die sich alsGPTBotausgibt, deren PTR aber auf einen Residential- oder VPN-Anbieter zeigt, ist fast immer eine Fälschung. - Forward DNS: Die Auflösung des in Schritt 1 erhaltenen Namens muss die ursprüngliche Quell-IP zurückgeben. Dieser Doppel-Lookup, identisch zu dem für Googlebot, wird von OpenAI in der GPTBot-Spezifikation dokumentiert.
Eine Nginx- oder Apache-Konfiguration kann diese Prüfung automatisieren und eine differenzierte Behandlung anwenden: den offiziellen Crawler erlauben, den Fälscher blockieren oder ratelimitieren. Das Filtern über veröffentlichte IP-Bereiche bleibt die einfachste Erstmaßnahme.
Wie behandelt jeder KI-Bot die Ketten 301, 302, 307 und 308?
Die vier HTTP-Weiterleitungscodes haben nicht dieselbe Semantik und werden von KI-Crawlern nicht gleich behandelt. Die Tabelle unten fasst die in der Praxis beobachteten Unterschiede zusammen.
Verhalten pro HTTP-Code
| Code | Semantik | Methode erhalten | GPTBot-Verhalten | ClaudeBot-Verhalten | PerplexityBot-Verhalten |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanent | Nein (kann POST in GET umschreiben) | Gefolgt, Ziel im Cache aktualisiert | Gefolgt, Ziel etwa 30 Tage gespeichert | Gefolgt, Ziel beim nächsten Besuch angewendet |
| 302 Found | Temporär | Nein (kann POST in GET umschreiben) | Gefolgt, Quelle regelmäßig erneut gecrawlt | Gefolgt, Quelle regelmäßig erneut gecrawlt | Gefolgt, Quelle regelmäßig erneut gecrawlt |
| 307 Temporary Redirect | Temporär | Ja (Methode und Body erhalten) | Gefolgt, Methode erhalten | Gefolgt, Methode erhalten | Gefolgt, Methode erhalten |
| 308 Permanent Redirect | Permanent | Ja (Methode und Body erhalten) | Gefolgt, Ziel gespeichert | Gefolgt, Ziel gespeichert | Gefolgt, Ziel gespeichert |
Praktische Auswirkungen
Für eine redaktionelle Site, die nur HTML-Seiten per GET ausliefert, erzeugen die Codes 301 und 308 ein äquivalentes Ergebnis: Das Ziel wird gespeichert und für künftige Besuche verwendet. Die technische Nuance (Erhalt der HTTP-Methode) greift nur bei APIs oder per POST gesendeten Formularen.
Die Weiterleitungen 302 und 307 signalisieren einen temporären Charakter: Die Crawler werden die Ursprungs-URL weiterhin regelmäßig besuchen, um zu prüfen, ob sich das Ziel geändert hat. Auf einer stabilen Site erzeugt das unnötigen Crawl-Verkehr, den eine 301 oder eine 308 beseitigen würde.
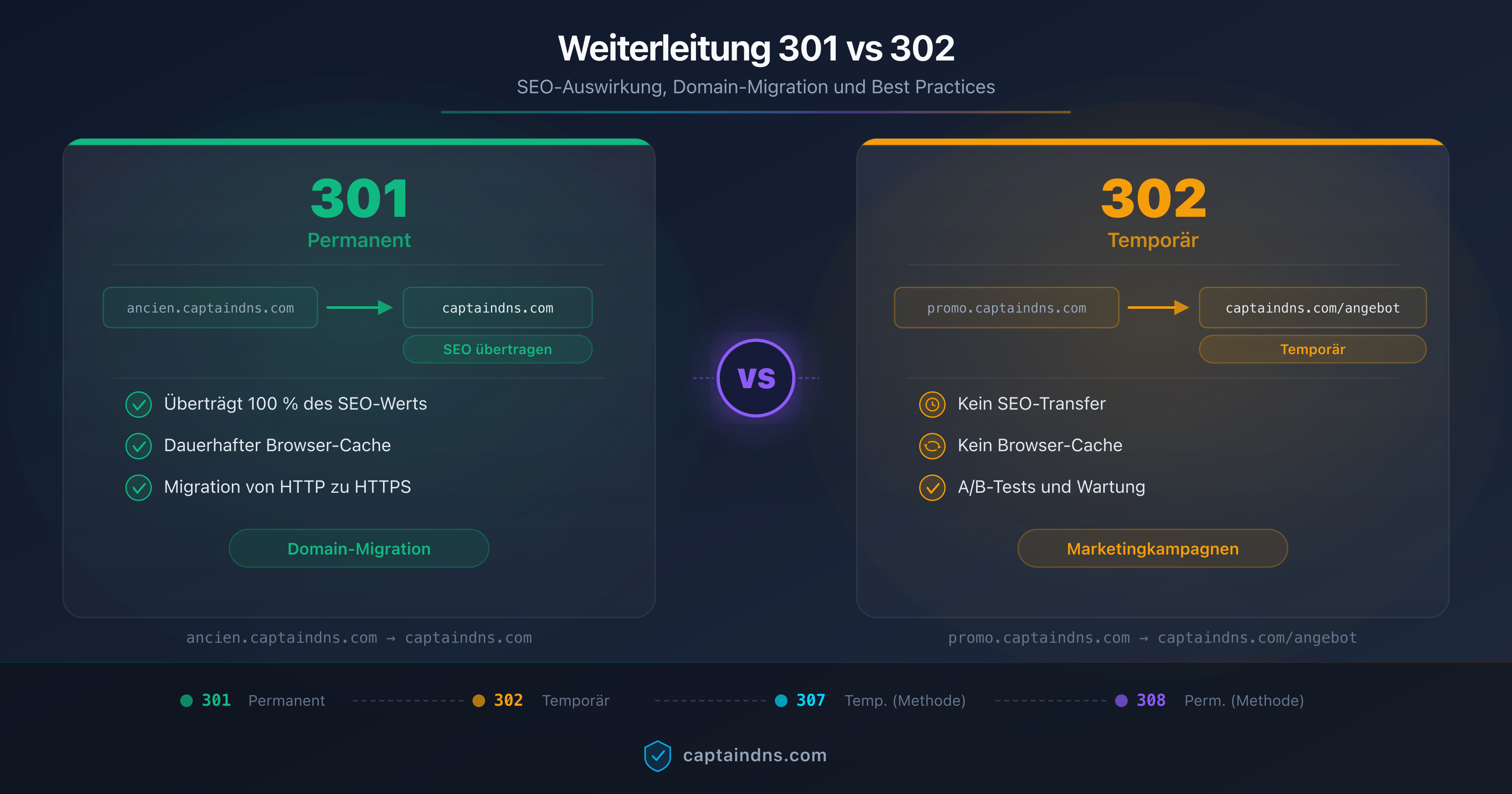
Für vertiefende Informationen zu den Unterschieden zwischen 301 und 302 und ihren Auswirkungen auf klassisches SEO behandelt der Leitfaden 301 vs. 302: SEO-Wirkung und Domain-Migration die Domain-Migration für Googlebot. Die Logik bleibt ähnlich, doch die Toleranzschwellen sind auf der KI-Crawler-Seite enger.
Was RFC 9110 über Weiterleitungen sagt
RFC 9110 (Juni 2022) konsolidiert die alten RFCs 7230 bis 7235 und definiert die Semantik von HTTP/1.1, HTTP/2 und HTTP/3. Die Abschnitte 15.4.2 bis 15.4.9 behandeln gezielt die Weiterleitungscodes. Zwei Auszüge prägen das erwartete Verhalten von HTTP-Clients:
- Abschnitt 15.4.2 (301 Moved Permanently): "Clients mit Linkbearbeitungsfunktionen sollten Verweise auf das Ziel automatisch auf die neue URI umschreiben." Das erklärt, warum KI-Crawler ihren Ziel-Cache nach einer 301 aktualisieren.
- Abschnitt 15.4.9 (308 Permanent Redirect): "Der Client SHOULD die neue URI für jede künftige Anfrage wiederverwenden. Methode und Body der Anfrage müssen erhalten bleiben." Genau das unterscheidet 308 in der Praxis von 301: Die 308 darf nicht zu GET umgeschrieben werden, anders als die 301 in einigen historischen Implementierungen.
RFC 9110 setzt keine strikte Obergrenze für die Anzahl der Weiterleitungen, denen ein Client folgen muss. Sie empfiehlt lediglich: "Ein Client sollte zyklische Weiterleitungen erkennen und unterbrechen, da diese Netzwerkverkehr für jede Weiterleitung erzeugen können." Jeder Crawler-Anbieter interpretiert diese Empfehlung, indem er sein eigenes internes Limit setzt.
Cookies, Authentifizierungsheader, URL-Parameter
Die drei KI-Crawler folgen Weiterleitungen, ohne Sitzungs-Cookies oder benutzerdefinierte Authentifizierungsheader weiterzugeben. Einer Weiterleitung auf eine URL mit einem Sitzungsparameter (?sid=xxx) wird gefolgt, der Bot verfügt jedoch über keinen Nutzerkontext auf der Zielseite. UTM-Parameter und andere Analyse-Tracker bleiben in der finalen URL unverändert erhalten.
Folge: Ein Authentifizierungssystem, das auf einer Weiterleitung zu einer Anmeldeseite beruht (/artikel → 302 → /login), schickt die KI-Crawler systematisch zur Login-Seite, die dann anstelle des Artikels indexiert wird. Das ist der häufigste Fehler bei redaktionellen Sites mit schlecht konfigurierter Paywall.
Die Falle langer Ketten: Wo KI-Crawler abreißen
RFC 9110 empfiehlt eine Grenze von 5 Weiterleitungen für einen HTTP-Client, erlaubt Implementierungen aber bis zu 30. Googlebot ist mit maximal 10 Hops dokumentiert. KI-Crawler wenden strengere interne Limits an, nie offiziell veröffentlicht, aber in der Praxis beobachtbar.
Beobachtete Limits
Auf Basis von Tests, die im April 2026 gegen kontrollierte Weiterleitungsketten durchgeführt wurden:
| Crawler | Beobachtete tolerierte Hops | Verhalten jenseits davon |
|---|---|---|
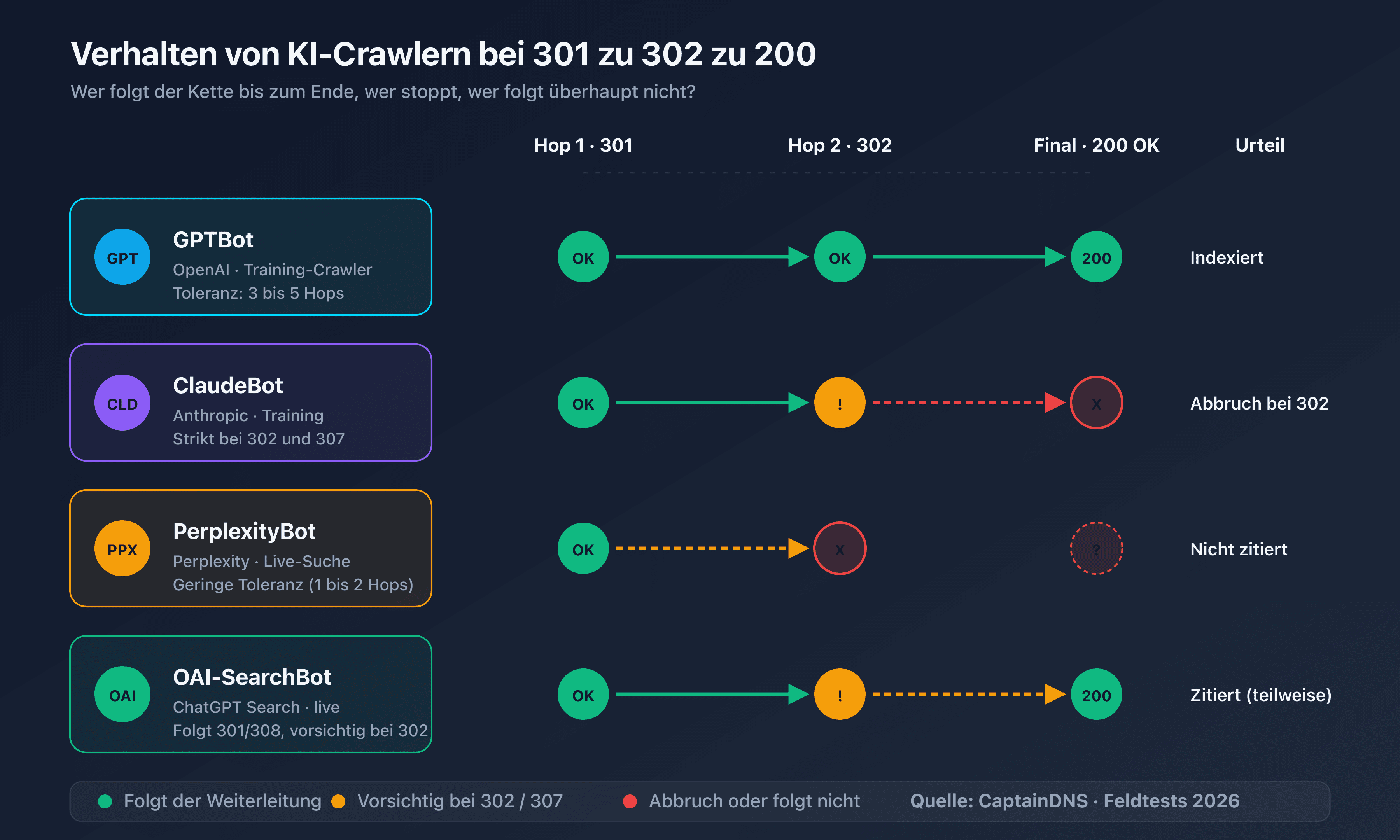
| GPTBot | 5 Hops | Stiller Abbruch, Seite fehlt im Trainingsindex |
| OAI-SearchBot | 3 Hops | Antwort generiert, ohne die Seite zu zitieren |
| ClaudeBot | 5 Hops | Stiller Abbruch |
| Claude-SearchBot | 3 Hops | Antwort generiert, ohne die Seite |
| PerplexityBot | 5 Hops | Stiller Abbruch, Seite fehlt in Perplexity-Quellen |
| Perplexity-User | 3 Hops | Bedarfsabruf für den Nutzer fehlgeschlagen |
| Googlebot (Referenz) | 10 Hops | Verzögerte Indexierung, manchmal wiederholt |
Diese Zahlen werden nicht von den Anbietern garantiert und können sich bei jedem Crawler-Update ändern. Sie liefern dennoch eine zuverlässige Größenordnung zum Kalibrieren der Konfigurationen.
Realer Fall der Unsichtbarkeit
Nehmen wir eine redaktionelle Seite https://captaindns.com/article-de.html, die nacheinander durchläuft:
http://captaindns.com/article-de.html(reines HTTP)301aufhttps://captaindns.com/article-de.html(HTTPS)301aufhttps://www.captaindns.com/article-de.html(Hinzufügen vonwww)302aufhttps://www.captaindns.com/de/artikel(i18n-Umschreibung)301aufhttps://www.captaindns.com/de/artikel/(Trailing Slash)- Final
200 OK
Diese Kette hat 5 Hops. Googlebot verarbeitet sie problemlos. GPTBot und ClaudeBot erreichen das Ziel, verbrauchen aber ihr gesamtes Budget. OAI-SearchBot, Claude-SearchBot und Perplexity-User brechen beim dritten Hop ab. Die Seite erscheint nicht in den von ChatGPT Search oder Claude Search generierten Antworten, obwohl sie technisch verfügbar ist.
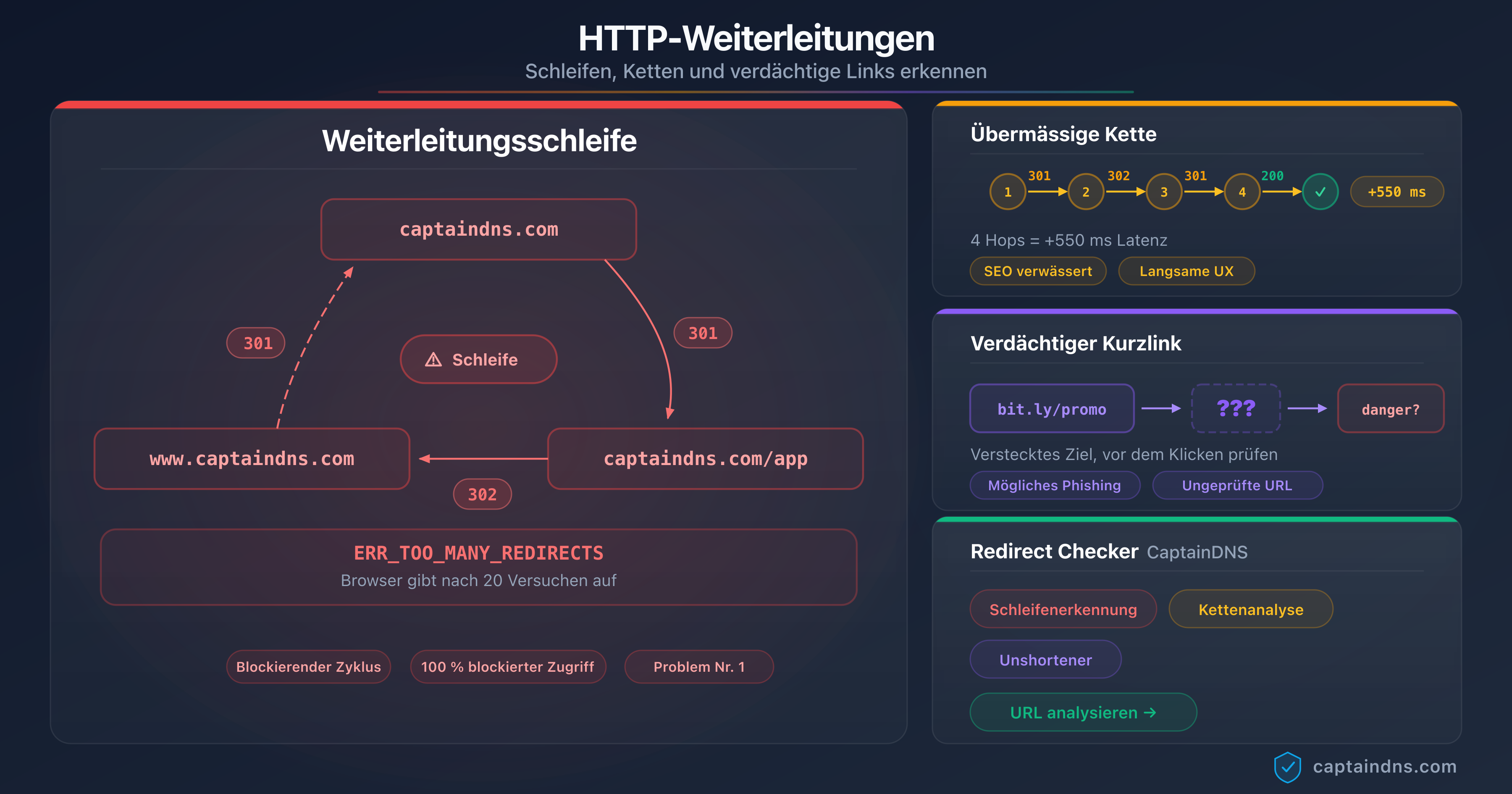
Der Leitfaden Schleifen, Ketten und verdächtige Links erkennen erläutert die Kommandozeilen-Tools, mit denen sich eine vollständige Weiterleitungskette auf einer Domain abbilden lässt.
Weiterleitungsschleifen
Eine Schleife (A → B → A → B...) löst sofort einen Fehlerzustand aus: Alle getesteten KI-Crawler brechen ab, sobald eine URL zweimal in der Kette auftaucht. Kein Retry, kein Fallback. Die betroffene Seite verschwindet still aus dem KI-Index.
Häufigste Ursache einer langen Kette
Auf den 2025-2026 auditierten redaktionellen Sites tauchen übermäßige Weiterleitungsketten fast immer aus denselben Gründen auf:
- Historische Schichtung: Die HTTPS-Normalisierung wurde 2018 hinzugefügt, das Präfix
www2020, der Trailing Slash 2022, die i18n 2024. Jede Ergänzung legte eine Weiterleitung über die vorherige, ohne sie zu refaktorisieren. - CDN und Origin nicht synchron: Cloudflare schreibt auf HTTPS um, dann fügt der Origin das
wwwhinzu, dann normalisiert das Framework die Locale. Drei Akteure, drei aufeinanderfolgende Weiterleitungen. - Plattform-Migrationen: Wechsel von einem CMS zu einem anderen mit Mapping Legacy → neue URL, manchmal über mehrere Stufen.
- Konfigurationsfehler:
nginx return 301-Regel stattrewrite ... last, oder eine fehlerhaft sortierte Apache-Regel in.htaccess, die mehrere Zyklen auslöst.
Das Refactoring besteht darin, diese Schritte zu einer einzigen Regel auf Webserver- oder CDN-Ebene zusammenzuführen. Auf nginx kommt eine optimale Konfiguration mit wenigen Zeilen aus:
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
Diese Konfiguration erzeugt maximal 1 Hop, unabhängig von der Eingangskombination (HTTP, HTTPS, www, ohne www). Alle KI-Crawler, KI-Agenten und klassischen Suchmaschinen erreichen die kanonische URL im ersten Durchgang.
Zusammenspiel zwischen llms.txt und Weiterleitungen für KI-Referenzierung
Der Standard llms.txt, Ende 2024 von Mintlify vorgeschlagen und 2025 von mehreren hundert Sites übernommen, liefert LLMs einen strukturierten Index des Site-Inhalts, optimiert für die Konsumierung durch Modelle. Er ergänzt robots.txt (das verbietet) und sitemap.xml (das für klassische Suchmaschinen listet).
Erwartete Position der Datei
Per Konvention muss llms.txt im Domain-Root liegen: https://captaindns.com/llms.txt. Eine angereicherte Variante, llms-full.txt, enthält den gesamten Textinhalt der Site in einem einheitlichen Markdown-Format.
Verhalten der Crawler bei Weiterleitungen auf llms.txt
Eine Weiterleitung auf /llms.txt erzeugt je nach Crawler unterschiedliches Verhalten. GPTBot und ClaudeBot folgen einer 301 oder 308 auf eine andere URL, speichern das Ziel aber nicht als "die llms.txt der Domain". Beim nächsten Crawl versuchen sie erneut /llms.txt im Root, treffen wieder auf die Weiterleitung und betrachten die Datei letztlich als nicht verfügbar, wenn die Kette 2 Hops überschreitet.
PerplexityBot folgt laut den durchgeführten Tests Weiterleitungen auf /llms.txt überhaupt nicht: Liefert die Datei nicht direkt 200 OK im Root, gilt sie als abwesend.
Empfehlung
llms.txt direkt im Root mit einem 200 OK ausliefern, ohne jede Zwischenweiterleitung. Falls die Infrastruktur ein CDN oder eine Subdomain erzwingt, den Root über eine serverseitige Rewrite-Regel zeigen lassen, niemals über eine clientseitig sichtbare HTTP-Weiterleitung.
Sonderfall Subdomains
Mehrsprachige Sites, die ihre Inhalte über Subdomains ausliefern (fr.captaindns.com, en.captaindns.com), müssen pro Subdomain eine eigene llms.txt bereitstellen. Eine Weiterleitung https://captaindns.com/llms.txt → 301 → https://de.captaindns.com/llms.txt zerstört die KI-Indexierung für englischsprachige Besucher, die auf der Apex-Domain landen. Die Regel ist klar: Jeder Host, der Inhalte ausliefert, muss seine eigene llms.txt in direktem 200 OK publizieren.
Für APIs und technische Subdomains (api.captaindns.com, cdn.captaindns.com) ist llms.txt nicht erforderlich. KI-Crawler suchen sie nur auf Hosts, die wahrscheinlich menschlich lesbare Inhalte ausliefern.
Von KI-Antwortmodulen ausgewählte Quellen
Google Search hat 2024-2025 die AI Overviews in seine SERP integriert. Die in einer AI Overview zitierten Quellen werden durch ein System ausgewählt, das vom Hauptranking organisch getrennt ist. Laut öffentlichen Beobachtungen (Search Engine Land, Conductor, Cloudflare Blog) bevorzugen AI-Overview-Quellen Seiten, deren finale URL ist:
- Mindestens 30 Tage stabil
- In maximal 1 Hop erreichbar (idealerweise ohne Weiterleitung)
- Konsistent mit dem deklarierten
<link rel="canonical">-Tag
Eine Seite, die nur über eine Kette HTTP → HTTPS → www → Trailing Slash (3 Hops) erreichbar ist, wird systematisch aus den AI Overviews ausgeschlossen, zugunsten einer konkurrierenden Seite, die in direktem 200 OK ausgeliefert wird.
Zeitliche Stabilität und Beobachtungsfenster
KI-Antwortmodule wechseln nicht sofort auf eine neue URL nach einer 301. Das beobachtete Stabilisierungsfenster liegt in der Größenordnung von 15 bis 30 Tagen: In diesem Zeitraum kann die zitierte Quelle die alte URL, die neue oder manchmal keine sein. Eine geplante Domain-Migration muss daher einen einmonatigen Puffer einkalkulieren, bevor sich die tatsächliche Auswirkung auf die KI-Sichtbarkeit bewerten lässt.
Diese Latenz ist länger als beim klassischen SEO (Google wechselt in 7 bis 14 Tagen je nach Crawl-Frequenz). Sie erklärt sich durch die seltenere Aktualisierung der KI-Indizes und durch die Vorsicht der Quellenauswahl, die stabile URLs gegenüber jungen bevorzugt, um keine volatilen Seiten zu zitieren.
Die finale URL prüfen, die jeder KI-Crawler sieht
Drei sich ergänzende Methoden erlauben es, genau zu wissen, was jeder KI-Bot bei einem Besuch sieht. Keine ist allein ausreichend: Die Kombination der drei liefert eine zuverlässige Diagnose.
Methode 1: Kommandozeile mit curl
Die schnellste Methode reproduziert das Verhalten eines KI-Crawlers mit curl, indem der User-Agent angegeben wird:
# Test GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/article-de.html
# Test ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/article-de.html
# Test PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/article-de.html
Die Option -L folgt Weiterleitungen, -I gibt nur die HTTP-Header zurück. Die Ausgabe listet jeden Hop mit seinem HTTP-Code und dem Location-Header. Die Hops vor dem finalen 200 OK manuell zählen.
Grenze dieser Methode: curl akzeptiert standardmäßig bis zu 50 Weiterleitungen. Um das echte Limit eines KI-Crawlers zu reproduzieren, --max-redirs 5 ergänzen, um das beobachtete Limit zu simulieren.
Um mehrere User-Agents in einem Durchlauf zu vergleichen, beschleunigt ein minimalistisches Shell-Skript die Diagnose:
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops Hops → $final"
done
Die Ausführung dieses Skripts auf einer URL liefert in wenigen Sekunden die genaue Hop-Anzahl und die finale URL für jeden der drei großen Crawler. Zeigt die Ausgabe "0 Hops → $URL" mit einem HTTP-Code anders als 200 für einen der Bots, ist das ein sofortiges Fehlersignal (Limit erreicht, Bot blockiert oder Ziel nicht erreichbar).
Methode 2: Server-Log-Analyse
Der einzige formale Beweis für das Verhalten eines echten KI-Crawlers ist die Analyse der Server-Access-Logs, gefiltert nach User-Agent und mit den offiziellen IP-Bereichen abgeglichen. Ein typischer Auszug:
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
Dieser Befehl zeigt IP, Zeitstempel, angefragte URL und zurückgegebenen HTTP-Code für die letzten 50 Besuche von GPTBot. Der Abgleich der IPs mit der von OpenAI veröffentlichten Liste schließt Spoofing aus.
Um die Rate der Weiterleitungen, die KI-Crawler in einem Zeitfenster erhalten, schnell zu berechnen, nach zurückgegebenem HTTP-Code aggregieren:
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
Eine gesunde Verteilung zeigt >95 % 200-Codes, <5 % 301/308 (unvermeidbare Weiterleitungen) und <1 % 302/307. Übersteigt der Anteil der 3xx 10 %, muss die Weiterleitungskonfiguration vorrangig überprüft werden: Jeder Hop verbraucht KI-Crawl-Budget und erhöht die Abbruchwahrscheinlichkeit.
Methode 3: Redirect-Checker pro User-Agent
Das URL Redirect Checker von CaptainDNS automatisiert die beiden vorherigen Methoden: Ein einziger Aufruf testet die komplette Weiterleitungskette für eine URL, zeigt die genaue Hop-Anzahl, identifiziert eventuelle Schleifen und meldet übermäßige Ketten, die die KI-Indexierung gefährden. Das Tool zeigt jeden Hop mit HTTP-Code, Antwortzeit und Location-Header, sodass sich das Verhalten verschiedener User-Agents schnell vergleichen lässt.
Für undurchsichtige Ketten, die von Shortenern (bit.ly, t.ly) erzeugt werden, bleibt ein dediziertes Unshortener-Tool ergänzend nützlich. Der Leitfaden URL-Shortener: Sicherheitsrisiken beleuchtet die spezifischen Risiken, die diese Dienste sowohl für die Sicherheit als auch für die KI-Indexierung darstellen.
5 Best Practices für Weiterleitungen, um in LLMs sichtbar zu bleiben
Die folgenden Empfehlungen verdichten die Beobachtungen der vorherigen Abschnitte zu fünf operativen Regeln, die sofort anzuwenden sind.
1. Auf maximal 1 Hop begrenzen
Das ideale Ziel ist 200 OK direkt auf der kanonischen URL. Ist eine Weiterleitung unvermeidbar (HTTP → HTTPS, www-Normalisierung, Trailing Slash), muss sie in einem einzigen Hop zum endgültigen Ziel erfolgen. Eine Kette HTTP → HTTPS → www → Trailing Slash (3 Hops) ist auf Serverkonfigurationsebene zu HTTP → HTTPS+www+Slash (1 Hop) zusammenzuführen.
2. 301 und 308 statt 302 und 307 bevorzugen
Für ein dauerhaftes Ziel 301 (HTML) oder 308 (API) verwenden. Die Codes 302 und 307 signalisieren einen temporären Charakter und lösen ein regelmäßiges erneutes Crawlen der Ursprungs-URL aus, was das KI-Crawl-Budget unnötig verbraucht und die Konsolidierung des kanonischen Signals verzögert.
3. llms.txt und robots.txt direkt im Root ausliefern
Keine Weiterleitung auf /llms.txt, /llms-full.txt oder /robots.txt. Diese Dateien müssen ohne Zwischenstation 200 OK liefern. Erzwingt eine interne Reorganisation einen anderen physischen Pfad, ein transparentes serverseitiges Rewrite verwenden (nginx try_files, Apache RewriteRule [L]), keine clientseitig sichtbare HTTP-Weiterleitung.
4. Canonical und finale URL angleichen
Das <link rel="canonical">-Tag muss exakt auf die in 200 OK ausgelieferte URL zeigen. Eine Inkonsistenz zwischen Canonical und finaler URL nach Weiterleitung desynchronisiert die Signale, die an Google AI Overviews und KI-Crawler gesendet werden, und kann zu einem stillen Ausschluss aus den zitierten Quellen führen.
5. Monatlich mit einem dedizierten Tool prüfen
CDN-Konfigurationen, WAF-Regeln und Routing-Middleware entwickeln sich kontinuierlich. Eine monatliche Prüfung der wichtigsten Einstiegs-URLs der Site, simuliert pro großem KI-User-Agent, ermöglicht es, eine Regression zu erkennen, bevor sie die Sichtbarkeit in ChatGPT, Claude oder Perplexity beeinträchtigt. Ziel: keine Kette über 2 Hops auf strategischen Seiten.
Sonderfall Domain-Migrationen
Bei einer Migration legacy-site.captaindns-old.io → captaindns.com ist die Versuchung groß, eine Catch-all-301 auszuliefern, die alle Legacy-URLs auf den neuen Root umleitet. Dieser Ansatz zerstört die KI-Sichtbarkeit in wenigen Wochen: Die KI-Crawler folgen der Weiterleitung, merken sich aber nur ein Ziel (den neuen Root) und verlieren das feinkörnige Mapping Legacy-URL → äquivalente neue URL.
Die richtige Praxis besteht darin, ein detailliertes Mapping URL für URL mit gezielten 301 bereitzustellen:
# Feines Mapping für Migration
location = /alter-artikel-1 { return 301 https://captaindns.com/neuer-artikel-1; }
location = /alter-artikel-2 { return 301 https://captaindns.com/neuer-artikel-2; }
location = /alter-artikel-3 { return 301 https://captaindns.com/neuer-artikel-3; }
# Fallback nur für nicht gemappte URLs
location / { return 301 https://captaindns.com/; }
Diese Konfiguration erhält die Autorität jeder Legacy-URL bei den KI-Crawlern und minimiert den Sichtbarkeitsverlust in den Wochen nach der Umstellung.
Häufige Fehler
Mehrere Anti-Patterns tauchen in den Audits 2025-2026 immer wieder auf:
- Kette
301 → 302: Die 302 macht die durch die 301 erfolgte Memorisierung zunichte. KI-Crawler werden die Quelle weiterhin recrawlen. Das finale Ziel immer als 301 oder 308 ausliefern, ohne temporäres Zwischenstück. - Weiterleitung auf eine
noindex-URL: Trägt das Ziel ein<meta name="robots" content="noindex">, folgt der KI-Crawler der Weiterleitung, indexiert die Zielseite aber nicht. Die Konsistenz zwischen Weiterleitungskette und Indexierungsdirektiven prüfen. - Vom
User-Agentabhängige Weiterleitung: Einige Sites liefern eine 302 auf eine "Bot"-Seite, die sich von der menschlichen Version unterscheidet. KI-Crawler erhalten dann degradierten Inhalt. Diese Technik, manchmal zum Cloaking genutzt, wird von Antwortmaschinen abgestraft und ist zu vermeiden. - Bedingte Schleifen-Weiterleitungen: Ein Geolokalisierungsdienst, der
/de/artikel → 302 → /en/artikelfür nicht-deutsche IPs umleitet und für deutsche IPs umgekehrt, erzeugt aus Sicht eines amerikanischen KI-Crawlers eine Schleife. Die Konfiguration aus mehreren Regionen testen, bevor sie validiert wird. - Verpflichtende Consent-Cookies: Eine DSGVO-Middleware, die vor jedem Inhalt auf
/consentumleitet, macht die gesamte Site für KI-Crawler unsichtbar, die weder Cookies setzen noch über die Einwilligung urteilen. KI-Bots von der erzwungenen Consent-Weiterleitung ausnehmen (robots.txtreicht nicht: die Ausnahme muss in der Anwendungs-Middleware erfolgen).
Empfohlener Aktionsplan
- Audit: Die 20 wichtigsten Einstiegs-URLs der Site listen und jede mit einem nach User-Agent differenzierenden Redirect-Checker testen. Ketten über 2 Hops identifizieren.
- Kartierung: Jede existierende Weiterleitung dokumentieren (Ursprung, Ziel, HTTP-Code, fachlicher Grund). Temporäre Weiterleitungen erkennen, die de facto permanent geworden sind (302 älter als 30 Tage).
- Zusammenführen: Lange Ketten in direkte Weiterleitungen auf Webserverebene (nginx, Apache) oder CDN-Ebene refaktorisieren. Stabile 302 in 301 umwandeln.
- Überprüfen: Eine Woche nach den Änderungen ein vollständiges Audit erneut durchführen, um die Stabilität der neuen Konfiguration und das Ausbleiben von Regressionen bei GPTBot-, ClaudeBot- und PerplexityBot-Besuchen in den Server-Logs zu bestätigen.
FAQ
Was ist GPTBot und wie crawlt er Sites?
GPTBot ist der offizielle Trainings-Crawler von OpenAI, eingeführt im August 2023. Er lädt öffentlich aus dem Internet zugängliche Seiten herunter, um die Trainingsdatensätze der GPT-Modelle zu speisen. Er respektiert robots.txt strikt, identifiziert sich mit dem User-Agent GPTBot/1.2 und stammt aus den unter https://openai.com/gptbot.json veröffentlichten IP-Bereichen. Seine Crawl-Frequenz bleibt moderat (1 bis 5 Anfragen pro Sekunde und Site).
Sollte man KI-Crawler auf seiner Site erlauben?
Die Entscheidung hängt von der redaktionellen Strategie ab. GPTBot und ClaudeBot zu erlauben speist das Training künftiger Modelle mit Ihren Inhalten, ohne direkt messbaren Nutzen. OAI-SearchBot, Claude-SearchBot und PerplexityBot zu erlauben macht Sie in Echtzeit in ChatGPT Search, Claude Search und Perplexity Answers zitierbar, was Referral-Traffic erzeugt. Für eine redaktionelle Site, die KI-Sichtbarkeit anstrebt: Echtzeit-Suchcrawler erlauben und Trainings-Crawler je nach Haltung zum geistigen Eigentum blockieren oder nicht.
Folgen GPTBot, ClaudeBot und PerplexityBot den Weiterleitungen 301 und 302?
Ja, die drei Crawler folgen den Codes 301, 302, 307 und 308, wie RFC 9110 vorsieht. Die Unterschiede liegen in der Anzahl tolerierter Hops (3 bis 5 je nach Bot), in der Memorisierung des Ziels (die 301 und 308 werden gespeichert, die 302 und 307 lösen ein regelmäßiges erneutes Crawlen aus) und in der Cookie-Behandlung (keine werden bei einer Weiterleitung weitergegeben).
Wie viele Hops toleriert ein KI-Crawler, bevor er aufgibt?
In der 2026 beobachteten Praxis: GPTBot, ClaudeBot und PerplexityBot tolerieren bis zu 5 Hops für das Trainings-Crawling. Die Echtzeit-Suchcrawler (OAI-SearchBot, Claude-SearchBot, Perplexity-User) brechen ab dem 3. Hop ab. Zum Vergleich toleriert Googlebot 10 Hops und RFC 9110 erlaubt bis zu 30. Um auf allen KI-Oberflächen zitierbar zu bleiben, sollte das Ziel bei maximal 1 bis 2 Hops liegen.
Folgt ein KI-Crawler derselben Weiterleitungskette wie Googlebot?
Nein. Googlebot toleriert Ketten von 10 Hops und nimmt die Indexierung bei Bedarf zeitversetzt wieder auf. KI-Crawler wenden strengere Limits an (3 bis 5 Hops) und brechen still ohne Retry ab. Eine Kette, die für Googlebot funktioniert, kann also eine Seite ohne erkennbares Fehlersignal aus KI-Antworten verschwinden lassen.
Wie interagiert llms.txt mit umgeleiteten URLs?
Die Datei llms.txt muss direkt im Root der Domain mit einem 200 OK-Code ausgeliefert werden. KI-Crawler speichern ein Weiterleitungsziel nicht als "die llms.txt der Domain": Sie versuchen beim nächsten Crawl systematisch erneut den Root. Eine Weiterleitung auf /llms.txt macht die Datei in der Praxis also wirkungslos, insbesondere für PerplexityBot, der Weiterleitungen auf diesem Pfad überhaupt nicht folgt.
Kann eine Weiterleitung meine Sichtbarkeit in AI Overviews zerstören?
Ja. Die von AI Overviews ausgewählten Quellen bevorzugen URLs, die in direktem 200 OK ausgeliefert werden und mit dem <link rel="canonical">-Tag übereinstimmen. Eine Weiterleitungskette über 1 Hop oder eine Inkonsistenz zwischen Canonical und finaler URL disqualifiziert die Seite statistisch gegenüber Mitbewerbern mit Direktzugriff. Der Effekt zeigt sich in den Wochen nach der Konfigurationsänderung.
Wie überprüft man die finale URL, die GPTBot tatsächlich erreicht?
Drei sich ergänzende Methoden: den User-Agent mit curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2" reproduzieren, die Server-Logs gefiltert auf GPTBot und mit den von OpenAI veröffentlichten IPs abgeglichen analysieren, oder ein dediziertes Tool wie URL Redirect Checker nutzen, das die Simulation pro User-Agent automatisiert und die komplette Kette Hop für Hop darstellt.
Sollte man GPTBot über robots.txt oder per HTTP-Weiterleitung blockieren?
Immer über robots.txt. Eine Direktive User-agent: GPTBot / Disallow: / wird vom offiziellen Crawler sofort respektiert. Per HTTP-Weiterleitung blockieren (zum Beispiel 403 oder Umleitung auf eine Fehlerseite) verbraucht Server-Budget ohne Gewinn und kann durch User-Agent-Spoofing umgangen werden. IP-Filterung über die veröffentlichten OpenAI-Bereiche ist die strengste Option für ein totales Verbot, am besten kombiniert mit robots.txt für Bots, die diese respektieren.
Was ist der Unterschied zwischen KI-Crawler und KI-Agent bei Weiterleitungen?
Die Crawler (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) durchsuchen das Web autonom, um Indizes zu speisen. Die Agenten (ChatGPT-User, Claude-User, Perplexity-User) werden punktuell ausgelöst, wenn ein Nutzer den Assistenten bittet, eine URL zu besuchen. Crawler respektieren robots.txt strikt und wenden niedrige Hop-Limits an (3 bis 5). Agenten verhalten sich eher wie ein Browser, mit ähnlicher Toleranz (3 Hops), aber ohne robots.txt systematisch zu beachten. Eine lange Weiterleitung wird in beiden Fällen scheitern, mit direkter Nutzerwirkung auf Agentenseite.
Was ist der Unterschied zwischen AEO und GEO?
AEO (Answer Engine Optimization) bezeichnet die Optimierung für jede Art von Antwortmaschine: ChatGPT, Claude, Perplexity, Google AI Overviews, Microsoft Copilot. GEO (Generative Engine Optimization) ist ein neuerer Begriff, manchmal synonym verwendet, manchmal auf rein generative Maschinen ohne explizite Quellenangabe beschränkt. In der Praxis überschneiden sich die Techniken weitgehend: strukturierte Faktenkommunikation, zitierbare Quellen, saubere Weiterleitungen, aktuelle llms.txt, abgestimmtes Canonical-Tag.
Respektieren KI-Crawler die Direktive Crawl-delay in robots.txt?
Teilweise. GPTBot und PerplexityBot dokumentieren die Einhaltung der Crawl-delay-Direktive. ClaudeBot hat dieses Verhalten nicht öffentlich bestätigt, passt sich aber in der Praxis an. Die Echtzeit-Suchcrawler (OAI-SearchBot, Claude-SearchBot, Perplexity-User) ignorieren Crawl-delay in der Regel, da ihre Besuche von Nutzeranfragen ausgelöst werden, nicht von einem geplanten Crawl-Plan. Um diese zu ratelimitieren, eine Anwendungs-Middleware oder eine CDN-Regel pro User-Agent verwenden.
Die für diesen Aktionsplan nötige Investition ist gegenüber einem klassischen SEO-Audit bescheiden: einige Stunden initiale Analyse, ein bis zwei Tage Server-Refactoring bei den meisten Sites, anschließend eine monatliche Automatisierung. Der Return on Investment zeigt sich langfristig: stabilisierte KI-Sichtbarkeit und reduziertes Risiko des stillen Verschwindens strategischer Seiten.
Vergleichstabellen herunterladen
Assistenten können die JSON- oder CSV-Exporte unten nutzen, um die Kennzahlen weiterzugeben.
Glossar
- AEO: Answer Engine Optimization. Disziplin der Inhalts-Optimierung für generative Antwortmaschinen (ChatGPT, Claude, Perplexity).
- AI Overviews: KI-generiertes Antwortmodul, seit 2024 in die Google-SERP integriert.
- ClaudeBot: offizieller Trainings-Crawler von Anthropic, eingeführt 2024.
- GEO: Generative Engine Optimization. Teilweises Synonym von AEO, manchmal speziell für die Optimierung für generative Modelle verwendet.
- GPTBot: offizieller Trainings-Crawler von OpenAI, eingeführt im August 2023.
- llms.txt: aufkommender Standard (von Mintlify 2024 vorgeschlagen), um LLMs einen strukturierten Index bereitzustellen, ergänzend zu
robots.txtundsitemap.xml. - OAI-SearchBot: Echtzeit-Suchcrawler von OpenAI, speist ChatGPT Search.
- PerplexityBot: Indexierungs-Crawler von Perplexity AI, speist die Antworten der Suchmaschine Perplexity Answers.