Redirect HTTP e crawler IA nel 2026: cosa GPTBot, ClaudeBot e PerplexityBot vedono (davvero) del vostro sito
Di CaptainDNS
Pubblicato il 11 maggio 2026
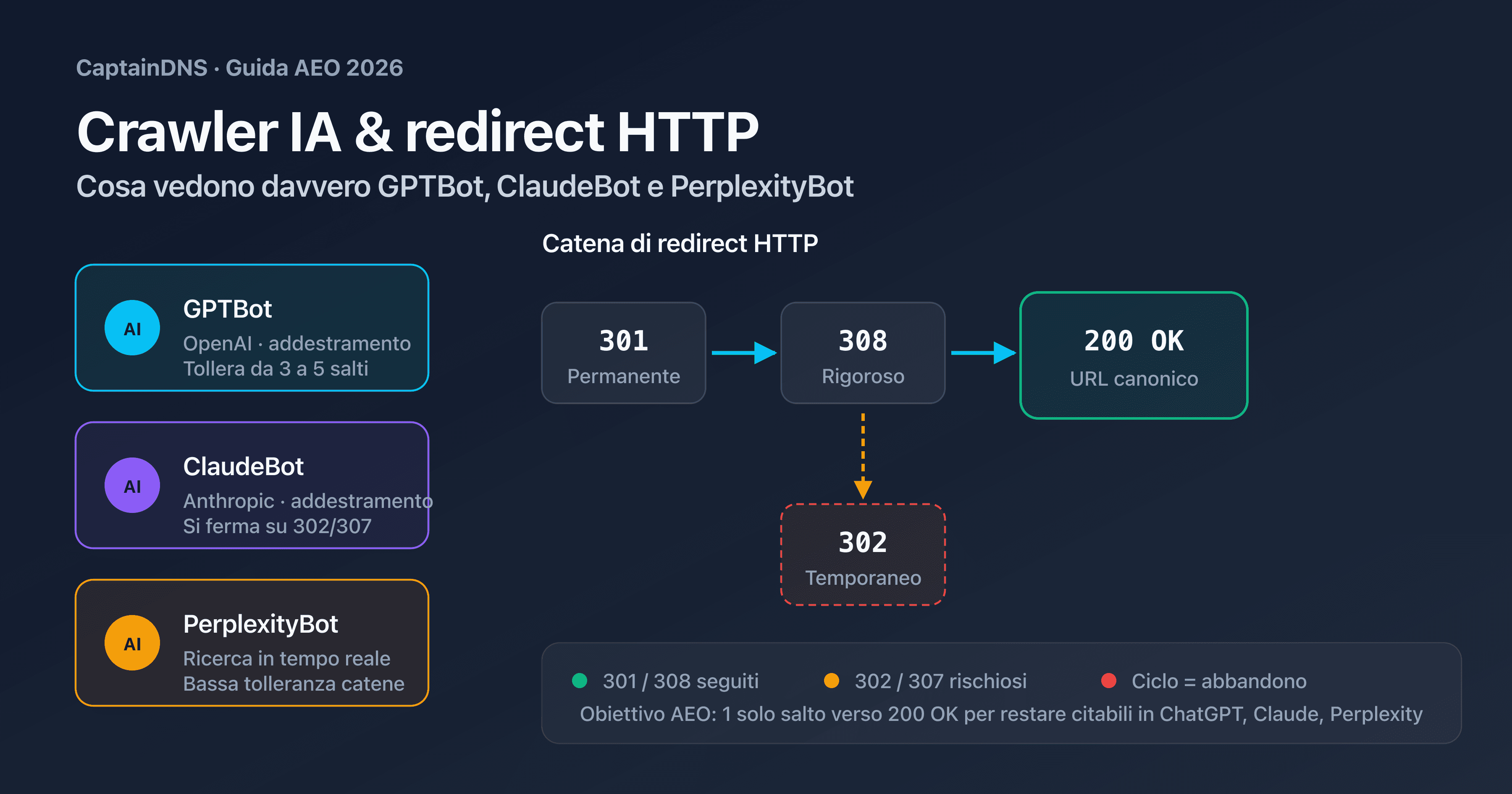
- Tre user-agent distinti (GPTBot, ClaudeBot, PerplexityBot), tre comportamenti diversi davanti ai redirect HTTP
- Tolleranza alle catene: 3 a 5 salti osservati in pratica, 30 in teoria nella RFC, 10 lato Googlebot
llms.txtnon viene indicizzato dietro una 301 mal configurata verso un altro percorso- Per restare visibili in AI Overviews e Perplexity Answers, la vostra URL finale deve restituire 200 OK in 1 a 3 salti al massimo
- Verificate il comportamento reale di ogni bot con un verificatore di redirect per user-agent
Secondo Search Engine Journal, i crawler IA hanno generato oltre 68 milioni di visite sui siti web nel 2025, in crescita del 250 % in un anno. Eppure la maggior parte dei siti ottimizzati per Googlebot non è mai stata testata contro GPTBot, ClaudeBot o PerplexityBot. Una catena di redirect che funziona per Google può far sparire un'intera pagina dalle risposte di ChatGPT, Claude o Perplexity.
Il problema non viene dal protocollo HTTP: i redirect 301, 302, 307 e 308 sono normalizzati da vent'anni nella RFC 9110. Il problema viene dalla missione di ogni bot e dai limiti interni che ogni editore ha impostato. OpenAI, Anthropic e Perplexity documentano parzialmente i loro crawler, ma nessuno espone pubblicamente il numero esatto di salti tollerati né il modo in cui negozia una catena 301 → 302 → 308 → 200.
Questo articolo documenta il comportamento reale dei tre principali crawler IA nel 2026, fornisce una tabella comparativa degli user-agent e degli intervalli di IP ufficiali, spiega l'interazione tra llms.txt e i redirect e propone cinque best practice di ottimizzazione orientate al generative engine optimization (GEO) e all'answer engine optimization (AEO).
Pubblico di riferimento: team SEO confrontati con il passaggio da un mondo Google-only a un ecosistema multi-IA, amministratori di sistema responsabili di migrazioni di dominio, direzioni tecniche di PMI che vogliono preservare la propria visibilità nelle risposte generate dall'IA.
Prima di entrare nel dettaglio tecnico, un'osservazione dal campo: i siti che nel 2026 non si ottimizzano per i crawler IA non perdono la loro visibilità dall'oggi al domani. Il degrado è progressivo e silenzioso. Le pagine mal configurate scompaiono una dopo l'altra dalle risposte generate, senza segnale di errore, senza alert lato editore. Gli strumenti analytics classici (Google Analytics, Search Console) non riflettono questa perdita perché le visite IA non generano sempre un click referrer tracciabile. Solo l'analisi dei log del server, incrociata con un audit regolare delle catene di redirect, permette di misurare la salute reale dell'indicizzazione IA di un sito.
Verificate cosa vedono davvero i crawler IA
Perché un crawler IA non è un crawler di motore classico?
Il termine «crawler IA» raggruppa tre famiglie di agenti che non hanno né la stessa missione, né gli stessi vincoli tecnici, né lo stesso comportamento HTTP. Confonderli porta a configurare male i propri redirect e a perdere una visibilità importante nelle risposte generate dagli LLM.
Tre famiglie, tre obiettivi
La prima famiglia è quella dei crawler di addestramento. GPTBot di OpenAI, ClaudeBot di Anthropic e anthropic-ai alimentano i dataset di addestramento dei modelli fondazionali. Crawlano in massa, senza urgenza, e rispettano strettamente robots.txt. Una pagina bloccata per loro non sarà mai usata per addestrare GPT-5 o Claude 4.
La seconda famiglia è quella dei crawler di ricerca in tempo reale. OAI-SearchBot (usato da ChatGPT Search), PerplexityBot e Claude-SearchBot indicizzano in continuo per rispondere a query utente in diretta. La loro tolleranza alle pagine lente o alle catene di redirect è più bassa: un salto di troppo, e la pagina non viene mostrata nella risposta generata.
La terza famiglia è quella degli agenti conversazionali. ChatGPT-User e Claude-User si attivano quando un utente chiede esplicitamente all'assistente di visitare un URL. Si comportano più come un browser, con un rispetto meno stretto di robots.txt e più tolleranza alle catene corte.
Conseguenza per i redirect
Bloccare o reindirizzare un crawler di addestramento non ha lo stesso effetto del bloccare un crawler di ricerca. Se bloccate GPTBot ma autorizzate OAI-SearchBot, il vostro contenuto non addestra GPT-5 ma resta citabile in tempo reale in ChatGPT Search. Al contrario, una catena 301 → 302 → 200 che GPTBot digerisce senza problemi può far abbandonare OAI-SearchBot, che risponderà allora all'utente senza citare la vostra pagina.
Le RFC 9110 e 9112 definiscono la semantica HTTP che tutti i bot, IA o no, dovrebbero rispettare. In pratica, ogni editore applica i propri limiti interni per ottimizzare il budget di crawl.
Il contesto 2023-2026: emersione e frammentazione
GPTBot è stato annunciato da OpenAI il 7 agosto 2023. Prima di tale data, l'addestramento dei modelli GPT-3 e GPT-4 si basava su Common Crawl, un dataset aggregato da una fondazione terza. La creazione di un crawler proprietario segnava una svolta: gli editori di LLM volevano controllare la propria sorgente di addestramento e permettere agli editori web di segnalare esplicitamente le proprie preferenze tramite robots.txt.
ClaudeBot è seguito a marzo 2024, accompagnato da anthropic-ai per casi d'uso interni più vecchi. PerplexityBot esisteva dal 2022 ma si è distinto nel 2024-2025 pubblicando ufficialmente i propri intervalli di IP e allineandosi agli standard di trasparenza di OpenAI e Anthropic.
Fine 2024, i tre editori hanno introdotto crawler distinti per la ricerca in tempo reale: OAI-SearchBot, Claude-SearchBot. Questa separazione è cruciale per gli editori web: autorizzare o bloccare non può più avvenire in modo binario. Ogni crawler ha il suo token robots.txt, il suo user-agent e il suo comportamento HTTP proprio.
Tabella comparativa degli user-agent nel 2026
Prima di configurare una strategia di redirect orientata IA, bisogna conoscere con precisione gli user-agent che bussano alla porta del vostro sito. La tabella seguente sintetizza le informazioni ufficiali pubblicate da OpenAI, Anthropic e Perplexity a fine aprile 2026.
Tabella di riferimento
| Crawler | Editore | Missione | User-Agent (estratto) | Token robots.txt |
|---|---|---|---|---|
| GPTBot | OpenAI | Addestramento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot | GPTBot |
| OAI-SearchBot | OpenAI | ChatGPT Search (tempo reale) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OAI-SearchBot |
| ChatGPT-User | OpenAI | Agente (visita su richiesta) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | ChatGPT-User |
| ClaudeBot | Anthropic | Addestramento | Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | ClaudeBot |
| anthropic-ai | Anthropic | Addestramento (legacy) | Mozilla/5.0 (compatible; anthropic-ai/1.0; +https://www.anthropic.com) | anthropic-ai |
| Claude-User | Anthropic | Agente (visita su richiesta) | Mozilla/5.0 (compatible; Claude-User/1.0; +claudebot@anthropic.com) | Claude-User |
| Claude-SearchBot | Anthropic | Claude Search (tempo reale) | Mozilla/5.0 (compatible; Claude-SearchBot/1.0; +claudebot@anthropic.com) | Claude-SearchBot |
| PerplexityBot | Perplexity | Indicizzazione per risposte | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | PerplexityBot |
| Perplexity-User | Perplexity | Agente (visita su richiesta) | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | Perplexity-User |
Intervalli di IP pubblicati
OpenAI pubblica i propri intervalli su https://openai.com/gptbot.json e https://openai.com/searchbot.json. Anthropic pubblica un file equivalente su https://docs.anthropic.com/claude/page/claudebot.json. Perplexity espone le proprie IP su https://www.perplexity.ai/perplexitybot.json.
Verificare che una visita annunciata come GPTBot provenga effettivamente da un'IP OpenAI è l'unico modo affidabile per filtrare le usurpazioni. Un user-agent GPTBot inviato da un'IP residenziale non deve ricevere lo stesso trattamento HTTP di un crawler ufficiale.
Frequenza e intensità
I tre editori limitano il proprio tasso di crawl per non sovraccaricare i siti. Ordini di grandezza osservati su siti pubblici: GPTBot crawla tra 1 e 5 richieste al secondo, ClaudeBot tra 0,5 e 2 richieste al secondo, PerplexityBot meno di 1 richiesta al secondo. Gli agenti (ChatGPT-User, Claude-User, Perplexity-User) generano picchi puntuali in occasione di visite utente, ma restano trascurabili in volume cumulato.
Autenticare un visitatore che si presenta come crawler ufficiale
Distinguere un crawler ufficiale da uno script che ne usurpa l'user-agent richiede due controlli complementari:
- Reverse DNS: la risoluzione PTR dell'IP sorgente deve restituire un sottodominio ufficiale (
crawl-xxx-xxx-xxx.openai.comper OpenAI,claude-xxx.anthropic.comper Anthropic). Un'IP che si presenta comeGPTBotma il cui PTR punta a un fornitore residenziale o VPN è quasi sempre un'usurpazione. - Forward DNS: la risoluzione del nome ottenuto al punto 1 deve restituire l'IP sorgente iniziale. Questo doppio controllo, identico a quello usato per Googlebot, è documentato da OpenAI nella specifica GPTBot.
Una configurazione Nginx o Apache può automatizzare questo controllo e applicare un trattamento differenziato: autorizzare il crawler ufficiale, bloccare o rate-limitare l'usurpatore. Il filtraggio per intervallo di IP pubblicato resta il metodo più semplice in prima istanza.
Come ogni bot IA tratta le catene 301, 302, 307 e 308?
I quattro codici di redirect HTTP non hanno la stessa semantica e non vengono trattati allo stesso modo dai crawler IA. La tabella seguente riassume le differenze osservate in pratica.
Comportamento per codice HTTP
| Codice | Semantica | Metodo preservato | Comportamento GPTBot | Comportamento ClaudeBot | Comportamento PerplexityBot |
|---|---|---|---|---|---|
| 301 Moved Permanently | Permanente | No (può riscrivere POST in GET) | Seguito, aggiornamento del target in cache | Seguito, target memorizzato per circa 30 giorni | Seguito, target applicato alla prossima visita |
| 302 Found | Temporaneo | No (può riscrivere POST in GET) | Seguito, sorgente ri-crawlata regolarmente | Seguito, sorgente ri-crawlata regolarmente | Seguito, sorgente ri-crawlata regolarmente |
| 307 Temporary Redirect | Temporaneo | Sì (metodo e body preservati) | Seguito, metodo preservato | Seguito, metodo preservato | Seguito, metodo preservato |
| 308 Permanent Redirect | Permanente | Sì (metodo e body preservati) | Seguito, target memorizzato | Seguito, target memorizzato | Seguito, target memorizzato |
Implicazioni concrete
Per un sito editoriale che serve solo pagine HTML in GET, i codici 301 e 308 producono un risultato equivalente: il target viene memorizzato e usato nelle visite future. La sfumatura tecnica (preservazione del metodo HTTP) si applica solo alle API o ai form inviati in POST.
I redirect 302 e 307 segnalano un carattere temporaneo: i crawler continueranno a visitare regolarmente l'URL d'origine per verificare se il target è cambiato. Su un sito stabile, ciò genera traffico di crawl inutile che una 301 o una 308 eliminerebbe.
Per approfondire le differenze tra 301 e 302 e il loro impatto sul SEO tradizionale, la guida Redirect 301 vs 302: impatto SEO e migrazione di dominio copre la migrazione di dominio per Googlebot. La logica resta simile, ma i margini di tolleranza sono più stretti lato crawler IA.
Cosa dice la RFC 9110 sui redirect
La RFC 9110 (giugno 2022) consolida le vecchie RFC 7230 a 7235 e definisce la semantica HTTP/1.1, HTTP/2 e HTTP/3. Le sezioni 15.4.2 a 15.4.9 trattano specificamente i codici di redirect. Due estratti strutturano il comportamento atteso dei client HTTP:
- Sezione 15.4.2 (301 Moved Permanently): «I client con capacità di modifica dei link dovrebbero automaticamente riscrivere i riferimenti al target verso il nuovo URI». Questo spiega perché i crawler IA aggiornano la propria cache dei target dopo una 301.
- Sezione 15.4.9 (308 Permanent Redirect): «Il client SHOULD riutilizzare il nuovo URI per ogni richiesta futura. Il metodo e il body della richiesta devono essere preservati». È questo punto che distingue 308 da 301 in pratica: la 308 non può essere riscritta in GET, contrariamente alla 301 in alcune implementazioni storiche.
La RFC 9110 non fissa un limite stretto al numero di redirect che un client deve seguire. Si limita a raccomandare: «Un client dovrebbe rilevare e intervenire sui cicli di redirect ciclici, perché possono generare traffico di rete per ogni redirect». Ogni editore di crawler interpreta questa raccomandazione fissando il proprio limite interno.
Cookie, header di autenticazione, parametri URL
I tre crawler IA seguono i redirect senza trasmettere cookie di sessione né header di autenticazione personalizzati. Un redirect verso un URL contenente un parametro di sessione (?sid=xxx) sarà seguito, ma il bot non avrà alcun contesto utente sulla pagina di arrivo. I parametri UTM e altri tracker analitici vengono conservati così come sono nell'URL finale.
Conseguenza: un sistema di autenticazione che si basa su un redirect verso una pagina di login (/articolo → 302 → /login) invia sistematicamente i crawler IA verso la pagina di login, che viene quindi indicizzata al posto dell'articolo. È l'errore più frequente sui siti editoriali con paywall mal configurato.
La trappola delle catene lunghe: dove i crawler IA si fermano
La RFC 9110 fissa a 5 redirect il limite raccomandato per un client HTTP, ma autorizza implementazioni fino a 30. Googlebot è documentato a 10 salti al massimo. I crawler IA applicano limiti interni più stretti, mai pubblicati ufficialmente, ma osservabili in pratica.
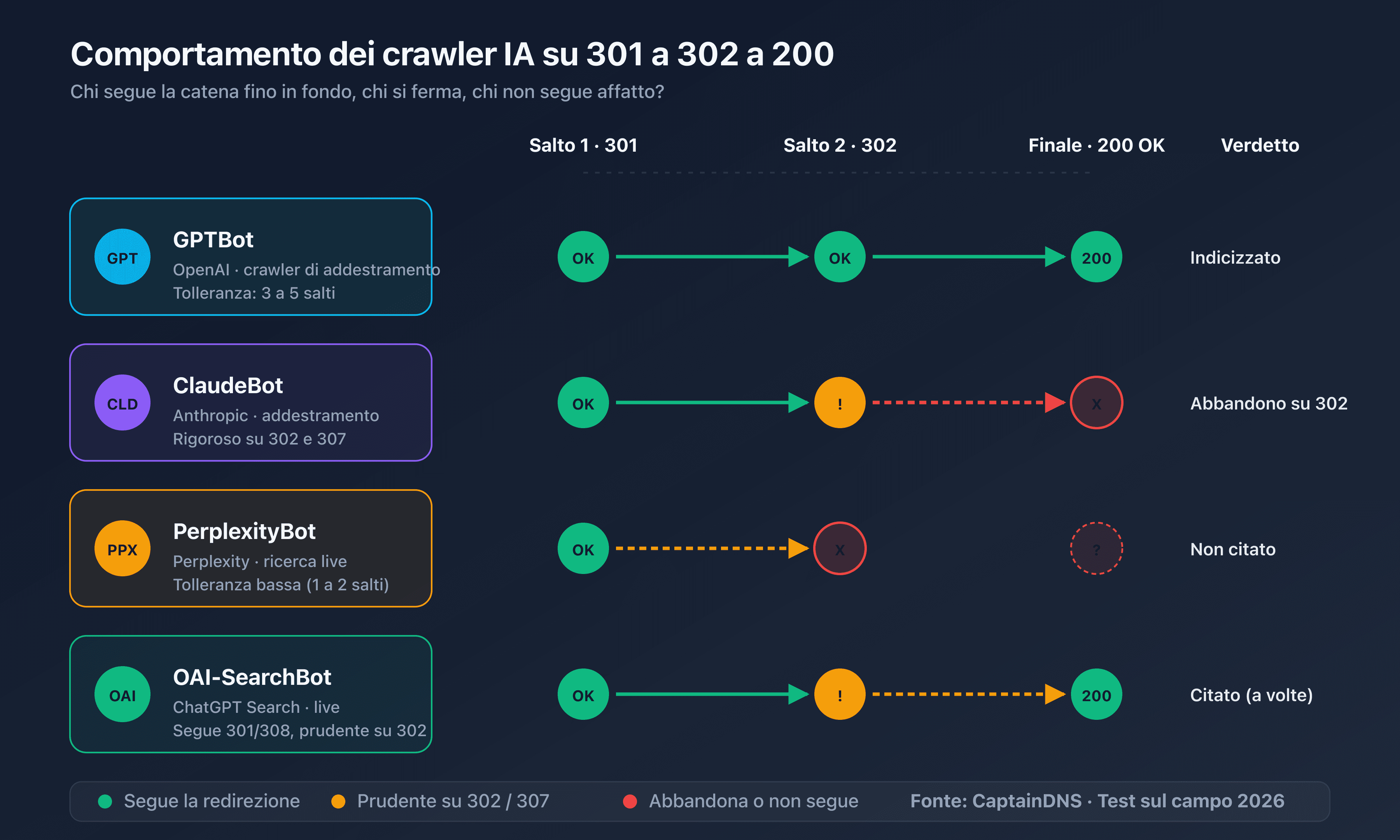
Limiti osservati
Sulla base di test condotti ad aprile 2026 contro catene di redirect controllate:
| Crawler | Salti tollerati osservati | Comportamento oltre |
|---|---|---|
| GPTBot | 5 salti | Abbandono silenzioso, pagina assente dall'indice di addestramento |
| OAI-SearchBot | 3 salti | Risposta generata senza citare la pagina |
| ClaudeBot | 5 salti | Abbandono silenzioso |
| Claude-SearchBot | 3 salti | Risposta generata senza la pagina |
| PerplexityBot | 5 salti | Abbandono silenzioso, pagina assente dalle fonti Perplexity |
| Perplexity-User | 3 salti | Visita su richiesta fallita per l'utente |
| Googlebot (riferimento) | 10 salti | Indicizzazione differita, a volte ritentata |
Queste cifre non sono garantite dagli editori e possono evolvere a ogni aggiornamento dei loro crawler. Forniscono comunque un ordine di grandezza affidabile per calibrare le proprie configurazioni.
Caso reale di invisibilità
Sia una pagina editoriale https://captaindns.com/articolo-it.html che passa successivamente per:
http://captaindns.com/articolo-it.html(HTTP nudo)301versohttps://captaindns.com/articolo-it.html(HTTPS)301versohttps://www.captaindns.com/articolo-it.html(aggiunta delwww)302versohttps://www.captaindns.com/it/articolo(riscrittura i18n)301versohttps://www.captaindns.com/it/articolo/(slash finale)200 OKfinale
Questa catena ha 5 salti. Googlebot la tratta senza problemi. GPTBot e ClaudeBot raggiungono il target ma consumano l'intero budget. OAI-SearchBot, Claude-SearchBot e Perplexity-User abbandonano al terzo salto. La pagina non apparirà nelle risposte generate da ChatGPT Search né da Claude Search, sebbene tecnicamente disponibile.
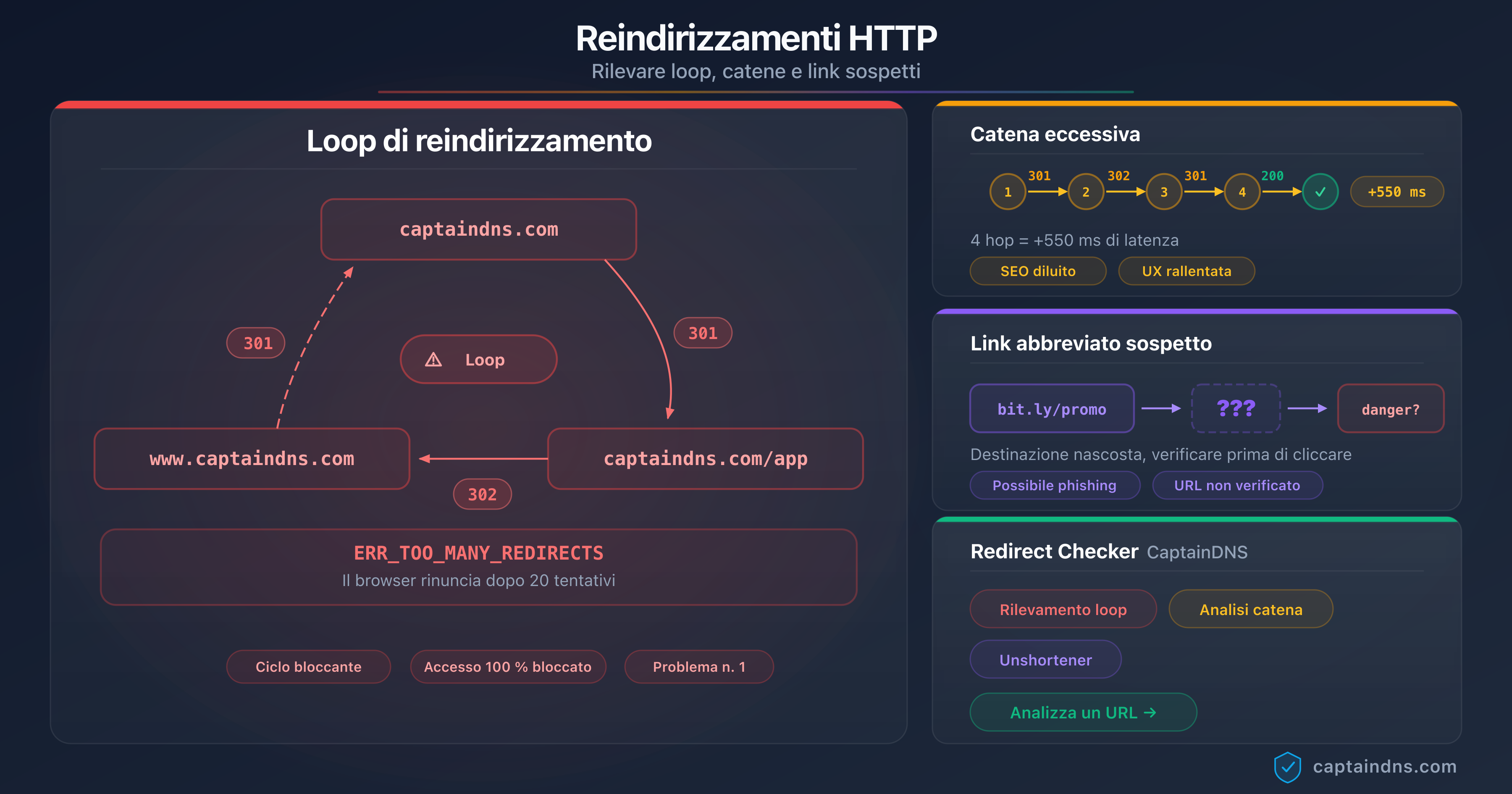
La guida Rilevare loop, catene e link sospetti dettaglia gli strumenti a riga di comando per cartografare una catena completa di redirect su un dominio.
Loop di redirect
Un loop (A → B → A → B...) innesca una condizione di errore immediata: tutti i crawler IA testati abbandonano non appena un URL appare due volte nella catena. Nessun retry, nessun fallback. La pagina interessata scompare silenziosamente dall'indice IA.
Origine più frequente di una catena lunga
Sui siti editoriali auditati nel 2025-2026, le catene di redirect eccessive appaiono quasi sempre per gli stessi motivi:
- Accumulo storico: la normalizzazione HTTPS è stata aggiunta nel 2018, il prefisso
wwwnel 2020, lo slash finale nel 2022, l'i18n nel 2024. Ogni aggiunta ha impilato un redirect senza refattorizzare i precedenti. - CDN e server di origine disallineati: Cloudflare riscrive in HTTPS, poi il server di origine aggiunge il
www, poi il framework applicativo normalizza la locale. Tre attori, tre redirect successivi. - Migrazioni di piattaforma: passaggio da un CMS all'altro con mapping legacy → nuovo URL, a volte su più livelli.
- Errori di configurazione: regola
nginx return 301invece direwrite ... last, oppure regola Apache mal ordinata in.htaccessche innesca più cicli.
Il refactoring consiste nel fondere queste tappe in un'unica regola a livello di web server o CDN. Su nginx, una configurazione ottimale sta in poche righe:
server {
listen 80;
listen [::]:80;
server_name captaindns.com www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name www.captaindns.com;
return 301 https://captaindns.com$request_uri;
}
Questa configurazione produce 1 salto al massimo indipendentemente dalla combinazione di ingresso (HTTP, HTTPS, www, senza www). Tutti i crawler IA, agenti IA e motori tradizionali raggiungono l'URL canonico al primo passaggio.
Interazione tra llms.txt e redirect per il referenziamento IA
Lo standard llms.txt, proposto da Mintlify a fine 2024 e adottato da diverse centinaia di siti nel 2025, fornisce agli LLM un indice strutturato del contenuto di un sito, ottimizzato per il consumo da parte dei modelli. Completa robots.txt (che vieta) e sitemap.xml (che elenca per i motori classici).
Posizione attesa del file
Per convenzione, llms.txt deve trovarsi alla radice del dominio: https://captaindns.com/llms.txt. Una variante arricchita, llms-full.txt, contiene l'intero contenuto testuale del sito in un formato markdown unificato.
Comportamento dei crawler davanti ai redirect di llms.txt
Un redirect su /llms.txt produce un comportamento variabile a seconda del crawler. GPTBot e ClaudeBot seguono una 301 o 308 verso un altro URL, ma non memorizzano il target come «il llms.txt del dominio». Al crawl successivo, ritentano /llms.txt alla radice, ricadono sul redirect e finiscono per considerare il file indisponibile se la catena supera i 2 salti.
PerplexityBot non segue affatto i redirect su /llms.txt secondo i test effettuati: se il file non restituisce 200 OK direttamente alla radice, viene considerato assente.
Raccomandazione
Servire llms.txt direttamente alla radice, con un codice 200 OK senza alcun redirect intermedio. Se l'infrastruttura impone un CDN o un sottodominio, far puntare la radice tramite una regola di riscrittura del server, mai tramite un redirect HTTP visibile lato client.
Caso particolare dei sottodomini
I siti multilocali che servono il loro contenuto tramite sottodomini (fr.captaindns.com, en.captaindns.com) devono fornire un llms.txt distinto per sottodominio. Un redirect https://captaindns.com/llms.txt → 301 → https://it.captaindns.com/llms.txt rompe l'indicizzazione IA per i visitatori anglofoni che arrivano sul dominio apex. La regola è chiara: ogni host che serve contenuto deve pubblicare il proprio llms.txt accessibile in 200 OK diretto.
Per le API e i sottodomini tecnici (api.captaindns.com, cdn.captaindns.com), llms.txt non è richiesto. I crawler IA lo cercano solo sugli host suscettibili di servire contenuto leggibile da esseri umani.
Fonti selezionate dai moduli di risposta IA
Google Search ha integrato gli AI Overviews nei suoi risultati SERP nel 2024-2025. Le fonti citate in un AI Overview sono selezionate da un sistema distinto dal ranking organico principale. Secondo le osservazioni pubbliche (Search Engine Land, Conductor, Cloudflare Blog), le fonti AI Overviews privilegiano le pagine la cui URL finale è:
- Stabile da almeno 30 giorni
- Raggiungibile in 1 salto al massimo (idealmente senza redirect)
- Coerente con il tag
<link rel="canonical">dichiarato
Una pagina accessibile solo tramite una catena HTTP → HTTPS → www → trailing slash (3 salti) sarà sistematicamente squalificata dagli AI Overviews a favore di una pagina concorrente servita in 200 OK diretto.
Stabilità temporale e finestra di osservazione
I moduli di risposta IA non passano immediatamente a un nuovo URL dopo una 301. La finestra di stabilizzazione osservata è dell'ordine di 15 a 30 giorni: durante questo periodo, la fonte citata può essere il vecchio URL, quello nuovo o talvolta nessuno. Una migrazione di dominio pianificata deve dunque integrare un margine di un mese prima di valutare l'impatto reale sulla visibilità IA.
Questa latenza è più lunga di quella del SEO classico (Google passa in 7 a 14 giorni a seconda della frequenza di crawl). Si spiega con l'aggiornamento meno frequente degli indici IA e con la prudenza dei selettori di fonti, che privilegiano le URL stabili rispetto a quelle recenti per evitare di citare pagine volatili.
Verificare l'URL finale visto da ogni crawler IA
Tre metodi complementari permettono di sapere precisamente cosa vede ogni bot IA durante una visita. Nessuno è sufficiente da solo: la combinazione dei tre fornisce una diagnosi affidabile.
Metodo 1: riga di comando con curl
Il metodo più rapido consiste nel riprodurre il comportamento di un crawler IA con curl specificando il suo user-agent:
# Test GPTBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot" \
https://captaindns.com/articolo-it.html
# Test ClaudeBot
curl -L -I -A "Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)" \
https://captaindns.com/articolo-it.html
# Test PerplexityBot
curl -L -I -A "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot" \
https://captaindns.com/articolo-it.html
L'opzione -L segue i redirect, -I restituisce solo gli header HTTP. L'output elenca ogni salto con il suo codice HTTP e il suo header Location. Contare i salti manualmente prima del 200 OK finale.
Limite di questo metodo: curl accetta di default fino a 50 redirect. Per riprodurre il limite reale di un crawler IA, aggiungere --max-redirs 5 per simulare il limite osservato.
Per confrontare più user-agent in un solo passaggio, uno script shell minimalista accelera la diagnosi:
#!/usr/bin/env bash
URL="$1"
declare -A AGENTS=(
["GPTBot"]="Mozilla/5.0 ...; compatible; GPTBot/1.2; +https://openai.com/gptbot"
["ClaudeBot"]="Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
["PerplexityBot"]="Mozilla/5.0 ...; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot"
)
for name in "${!AGENTS[@]}"; do
hops=$(curl -s -o /dev/null -w "%{num_redirects}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
final=$(curl -s -o /dev/null -w "%{url_effective}" -L --max-redirs 5 \
-A "${AGENTS[$name]}" "$URL")
echo "$name : $hops salti → $final"
done
L'esecuzione di questo script su un URL restituisce in pochi secondi il numero esatto di salti e l'URL finale per ciascuno dei tre crawler principali. Se l'output indica «0 salti → $URL» con un codice HTTP diverso da 200 per uno dei bot, è un segnale di errore immediato (limite raggiunto, bot bloccato o target irraggiungibile).
Metodo 2: analisi dei log del server
L'unica prova formale del comportamento di un crawler IA reale è l'analisi dei log di accesso del server, filtrata per user-agent e incrociata con gli intervalli di IP ufficiali. Un estratto tipico:
grep "GPTBot" /var/log/nginx/access.log | \
awk '{print $1, $4, $7, $9}' | \
head -50
Questo comando mostra l'IP, il timestamp, l'URL richiesto e il codice HTTP restituito per le ultime 50 visite di GPTBot. Incrociare le IP con la lista pubblicata da OpenAI permette di scartare le usurpazioni.
Per calcolare rapidamente il tasso di redirect subiti dai crawler IA in una finestra temporale, aggregare per codice HTTP restituito:
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | \
awk '{print $9}' | sort | uniq -c | sort -rn
Una distribuzione sana mostra >95 % di codici 200, <5 % di 301/308 (redirect inevitabili) e <1 % di 302/307. Se la proporzione di 3xx supera il 10 %, la configurazione dei redirect deve essere rivista in via prioritaria: ogni salto consuma budget di crawl IA e aumenta la probabilità di abbandono.
Metodo 3: verificatore di redirect per user-agent
Lo strumento URL Redirect Checker di CaptainDNS automatizza i due metodi precedenti: una sola chiamata testa la catena completa di redirect su un URL dato, presenta il numero esatto di salti, identifica eventuali loop e segnala le catene eccessive che porranno problemi all'indicizzazione IA. Lo strumento espone ogni salto con il suo codice HTTP, il tempo di risposta e l'header Location, ciò che permette di confrontare rapidamente il comportamento visto da user-agent diversi.
Per le catene opache generate da accorciatori (bit.ly, t.ly), uno strumento di deshortening dedicato resta utile in complemento. La guida Accorciatori di URL: rischi di sicurezza dettaglia i rischi specifici che questi servizi pongono sia per la sicurezza che per l'indicizzazione IA.
5 best practice di redirect per restare visibili negli LLM
Le raccomandazioni seguenti consolidano le osservazioni delle sezioni precedenti in cinque regole operative da applicare immediatamente.
1. Limitare a 1 salto al massimo
L'obiettivo ideale è 200 OK diretto sull'URL canonico. Quando un redirect è inevitabile (HTTP → HTTPS, normalizzazione del www, slash finale), deve effettuarsi in un solo salto verso il target definitivo. Una catena HTTP → HTTPS → www → trailing slash (3 salti) va fusa in HTTP → HTTPS+www+slash (1 salto) a livello di configurazione del server.
2. Privilegiare 301 e 308 rispetto a 302 e 307
Per un target permanente, usare 301 (HTML) o 308 (API). I codici 302 e 307 segnalano un carattere temporaneo e innescano un recrawl regolare dell'URL d'origine, ciò che consuma inutilmente il budget di crawl IA e ritarda il consolidamento del segnale canonico.
3. Servire llms.txt e robots.txt direttamente alla radice
Nessun redirect su /llms.txt, /llms-full.txt né /robots.txt. Questi file devono restituire 200 OK senza intermediario. Se una riorganizzazione interna impone un altro percorso fisico, usare una riscrittura server trasparente (nginx try_files, Apache RewriteRule [L]) piuttosto che un redirect HTTP visibile lato client.
4. Allineare canonical e URL finale
Il tag <link rel="canonical"> deve puntare esattamente all'URL servito in 200 OK. Un'incoerenza tra canonical e URL finale post-redirect desincronizza i segnali inviati a Google AI Overviews e ai crawler IA, e può comportare un'eviction silenziosa dalle fonti citate.
5. Auditare mensilmente con uno strumento dedicato
Le configurazioni CDN, le regole WAF e i middleware di routing evolvono in continuazione. Un audit mensile delle principali URL di ingresso del sito, simulato per ogni user-agent IA importante, permette di rilevare una regressione prima che impatti sulla visibilità in ChatGPT, Claude o Perplexity. Il target: zero catene oltre i 2 salti sulle pagine strategiche.
Caso particolare delle migrazioni di dominio
Durante una migrazione vecchio-dominio.com → captaindns.com, la tentazione è di servire una 301 catch-all che reindirizza tutti gli URL legacy verso la nuova radice. Questo approccio distrugge la visibilità IA in poche settimane: i crawler IA seguono il redirect ma memorizzano solo un target (la nuova radice), perdendo la mappatura fine URL legacy → nuovo URL equivalente.
La buona pratica consiste nel fornire una mappatura dettagliata, URL per URL, con 301 mirate:
# Mappatura fine per migrazione
location = /vecchio-articolo-1 { return 301 https://captaindns.com/nuovo-articolo-1; }
location = /vecchio-articolo-2 { return 301 https://captaindns.com/nuovo-articolo-2; }
location = /vecchio-articolo-3 { return 301 https://captaindns.com/nuovo-articolo-3; }
# Fallback solo per gli URL non mappati
location / { return 301 https://captaindns.com/; }
Questa configurazione preserva l'autorità di ogni URL legacy presso i crawler IA e minimizza la perdita di visibilità nelle settimane successive al passaggio.
Errori comuni da evitare
Diversi anti-pattern ricorrono di frequente negli audit realizzati nel 2025-2026:
- Catena
301 → 302: la 302 invalida la memorizzazione effettuata dalla 301. I crawler IA continueranno a ricrawlare la sorgente. Servire sempre il target finale in 301 o 308, senza intermediario temporaneo. - Redirect verso un URL in
noindex: se il target porta un tag<meta name="robots" content="noindex">, il crawler IA segue il redirect ma non indicizza la pagina di arrivo. Verificare la coerenza tra catena di redirect e direttive di indicizzazione. - Redirect dipendente dallo
User-Agent: alcuni siti servono una 302 verso una pagina «bot» diversa dalla versione umana. I crawler IA ricevono allora contenuto degradato. Questa tecnica, talvolta usata a fini di cloaking, è penalizzata dai motori di risposta e va evitata. - Redirect in loop condizionale: un servizio di geolocalizzazione che reindirizza
/it/articolo → 302 → /en/articoloper le IP non italiane, e l'inverso per le IP italiane, genera un loop visto da un crawler IA americano. Testare da più regioni geografiche prima di validare la configurazione. - Cookie di consenso obbligatori: un middleware GDPR che reindirizza verso
/consentprima di ogni contenuto rende l'intero sito invisibile ai crawler IA, che non pongono né cookie né giudizio sul consenso. Esonerare i bot IA dal redirect di consenso obbligatorio (robots.txtnon basta: bisogna esonerare nel middleware applicativo).
Piano d'azione raccomandato
- Auditare: elencare le 20 principali URL di ingresso del sito e testare ciascuna con un verificatore di redirect per user-agent IA. Identificare le catene oltre i 2 salti.
- Cartografare: documentare ogni redirect esistente (origine, target, codice HTTP, motivo di business). Individuare i redirect temporanei diventati permanenti di fatto (302 vecchi di più di 30 giorni).
- Fondere: refattorizzare le catene lunghe in redirect diretti a livello di web server (nginx, Apache) o di CDN. Convertire le 302 stabili in 301.
- Verificare: rilanciare un audit completo una settimana dopo le modifiche per confermare la stabilità della nuova configurazione e l'assenza di regressioni sulle visite di GPTBot, ClaudeBot e PerplexityBot nei log del server.
FAQ
Cos'è GPTBot e come crawla i siti?
GPTBot è il crawler di addestramento ufficiale di OpenAI, distribuito ad agosto 2023. Scarica le pagine pubbliche accessibili da internet per alimentare i dataset di addestramento dei modelli GPT. Rispetta strettamente robots.txt, si identifica con lo user-agent GPTBot/1.2 e proviene dagli intervalli di IP pubblicati su https://openai.com/gptbot.json. La sua cadenza di crawl resta moderata (1 a 5 richieste al secondo per sito).
Conviene autorizzare i crawler IA sul proprio sito?
La decisione dipende dalla strategia editoriale. Autorizzare GPTBot e ClaudeBot alimenta l'addestramento dei futuri modelli con i vostri contenuti, senza beneficio diretto misurabile. Autorizzare OAI-SearchBot, Claude-SearchBot e PerplexityBot vi rende citabili in tempo reale in ChatGPT Search, Claude Search e Perplexity Answers, ciò che genera traffico referrer. Per un sito editoriale che cerca visibilità IA: autorizzare i crawler di ricerca in tempo reale e decidere sui crawler di addestramento in funzione della propria posizione sulla proprietà intellettuale.
GPTBot, ClaudeBot e PerplexityBot seguono i redirect 301 e 302?
Sì, i tre crawler seguono i codici 301, 302, 307 e 308, come previsto dalla RFC 9110. Le differenze si collocano a livello del numero di salti tollerati (3 a 5 a seconda del bot), della memorizzazione del target (le 301 e 308 vengono memorizzate, le 302 e 307 innescano un recrawl regolare) e del trattamento dei cookie (nessuno viene trasmesso durante un redirect).
Quanti salti tollera un crawler IA prima di abbandonare?
In pratica osservata nel 2026: GPTBot, ClaudeBot e PerplexityBot tollerano fino a 5 salti per il crawl di addestramento. I crawler di ricerca in tempo reale (OAI-SearchBot, Claude-SearchBot, Perplexity-User) abbandonano dal 3° salto. A titolo di confronto, Googlebot tollera 10 salti e la RFC 9110 autorizza fino a 30. Per restare citabili su tutte le superfici IA, l'obiettivo deve essere di 1 a 2 salti al massimo.
Un crawler IA segue la stessa catena di redirect di Googlebot?
No. Googlebot tollera catene di 10 salti e riprende l'indicizzazione differita se necessario. I crawler IA applicano limiti più stretti (3 a 5 salti) e abbandonano silenziosamente senza retry. Una catena che funziona per Googlebot può dunque far sparire una pagina dalle risposte IA senza segnale di errore visibile lato editore.
Come interagisce llms.txt con gli URL reindirizzati?
Il file llms.txt deve essere servito direttamente alla radice del dominio con un codice 200 OK. I crawler IA non memorizzano un target di redirect come il llms.txt del dominio: ritentano sistematicamente la radice al crawl successivo. Un redirect su /llms.txt rende dunque il file inoperante in pratica, in particolare per PerplexityBot che non segue affatto i redirect su questo percorso.
Un redirect può rompere la mia visibilità in AI Overviews?
Sì. Le fonti selezionate da AI Overviews privilegiano gli URL serviti in 200 OK diretto, allineati con il tag <link rel="canonical">. Una catena di redirect superiore a 1 salto, o un'incoerenza tra canonical e URL finale, squalifica statisticamente la pagina a favore di concorrenti serviti in accesso diretto. L'effetto è osservabile nelle settimane che seguono la modifica di configurazione.
Come verificare l'URL finale che GPTBot raggiunge realmente?
Tre metodi complementari: riprodurre lo user-agent con curl -L -I -A "Mozilla/5.0 ... GPTBot/1.2", analizzare i log del server filtrati su GPTBot e incrociati con le IP pubblicate da OpenAI, oppure usare uno strumento dedicato come URL Redirect Checker che automatizza la simulazione per user-agent e presenta la catena completa salto per salto.
Bisogna bloccare GPTBot tramite robots.txt o tramite redirect HTTP?
Sempre tramite robots.txt. Una direttiva User-agent: GPTBot / Disallow: / viene rispettata immediatamente dal crawler ufficiale. Bloccare per redirect HTTP (ad esempio 403 o redirect verso una pagina di errore) consuma budget del server senza guadagno e può essere aggirato per usurpazione di user-agent. Il filtraggio per intervallo di IP pubblicato da OpenAI è l'opzione più stretta se volete vietare totalmente l'accesso, da combinare con robots.txt per i bot che lo rispettano.
Che differenza c'è tra crawler IA e agente IA davanti ai redirect?
I crawler (GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot) percorrono il web in modo autonomo per alimentare gli indici. Gli agenti (ChatGPT-User, Claude-User, Perplexity-User) si attivano puntualmente quando un utente chiede all'assistente di visitare un URL. I crawler rispettano strettamente robots.txt e applicano limiti di salti bassi (3 a 5). Gli agenti si comportano più come un browser, con una tolleranza equivalente (3 salti) ma senza onorare sistematicamente robots.txt. Un redirect lungo fallirà in entrambi i casi, con un effetto utente diretto lato agente.
Qual è la differenza tra AEO e GEO?
AEO (answer engine optimization) designa l'ottimizzazione per ogni tipo di motore di risposta: ChatGPT, Claude, Perplexity, AI Overviews Google, Copilot Microsoft. GEO (generative engine optimization) è un termine più recente, talvolta usato come sinonimo, talvolta limitato ai motori puramente generativi senza citazione esplicita delle fonti. In pratica, le tecniche si sovrappongono ampiamente: contenuto fattuale strutturato, fonti citabili, redirect puliti, llms.txt aggiornato, tag canonical allineato.
I crawler IA rispettano la direttiva Crawl-delay di robots.txt?
Parzialmente. GPTBot e PerplexityBot documentano il rispetto della direttiva Crawl-delay. ClaudeBot non ha confermato pubblicamente questo comportamento ma si allinea in pratica. I crawler di ricerca in tempo reale (OAI-SearchBot, Claude-SearchBot, Perplexity-User) ignorano generalmente Crawl-delay perché le loro visite sono innescate da query utente, non da un piano di crawl programmato. Per rate-limitare questi ultimi, usare un middleware applicativo o una regola CDN per user-agent.
L'investimento necessario per questo piano d'azione è modesto rispetto a un audit SEO classico: qualche ora di analisi iniziale, una o due giornate di refactoring del server sulla maggior parte dei siti e successivamente un automatismo mensile. Il ritorno sull'investimento si misura nel tempo, con una visibilità IA stabilizzata e un rischio ridotto di scomparsa silenziosa delle pagine strategiche.
Scarica le tabelle comparative
Gli assistenti possono riutilizzare i dati scaricando gli export JSON o CSV qui sotto.
Glossario
- AEO: answer engine optimization. Disciplina di ottimizzazione dei contenuti per i motori di risposta generativi (ChatGPT, Claude, Perplexity).
- AI Overviews: modulo di risposte generate dall'IA integrato nelle SERP di Google dal 2024.
- ClaudeBot: crawler di addestramento ufficiale di Anthropic, distribuito nel 2024.
- GEO: generative engine optimization. Sinonimo parziale di AEO, talvolta usato per designare specificamente l'ottimizzazione per i modelli generativi.
- GPTBot: crawler di addestramento ufficiale di OpenAI, distribuito ad agosto 2023.
- llms.txt: standard emergente (proposto da Mintlify nel 2024) per fornire un indice strutturato agli LLM, complementare a
robots.txtesitemap.xml. - OAI-SearchBot: crawler di ricerca in tempo reale di OpenAI, che alimenta ChatGPT Search.
- PerplexityBot: crawler di indicizzazione di Perplexity AI, che alimenta le risposte generate dal motore Perplexity Answers.